Learn how to stream JSON data into BigQuery using the new BigQuery Storage Write API
Veronica Wasson
Technical Writer
The Google BigQuery Write API offers high-performance batching and streaming in one unified API. The previous post in this series introduced the BigQuery Write API. In this post, we'll show how to stream JSON data to BigQuery by using the Java client library.
The Write API expects binary data in protocol buffer format. This makes the API very efficient for high-throughput streaming. However, protocol buffers can also be somewhat difficult to work with. For many applications, JSON data is a more convenient data format. The BigQuery client library for Java provides the best of both worlds, through the JsonStreamWriter. The JsonStreamWriter accepts data in the form of JSON records, and automatically converts the JSON objects into binary protocol buffers before sending them over the wire.
Let's see how it works.
The scenario
Let's consider a scenario where you are streaming GitHub commit data to BigQuery. You can use this data to get real-time insights about the commit activity.
For the purpose of the example, we'll read the data from a local file. However, you can imagine an application that receives this data in the form of events or streamed from a log file. In fact, one advantage of the Write API is that it doesn't matter where the data comes from, as long as you can get it into a compatible format.
Each line in the source file has the following structure:
Create the destination table
First, we need to create a table in BigQuery to receive the streamed data. There are several ways to create a table in BigQuery, but one of the easiest is by running a CREATE TABLE query:
Stream data to the table
Now that we have a table, we can write data to it.
The Write API supports several modes, including committed mode for streaming applications that require exactly-once delivery, and pending mode for batch writes with stream-level transactions. For this example, we'll use the Write API's default stream. The default stream is suitable for streaming applications that require at-least-once semantics but don't need the stronger exactly-one guarantee. Git commits have a unique commit ID, so you can identify duplication in the destination table if needed.
Start by initializing the JsonStreamWriter, passing in the name of the destination table and the table schema:
Now we're ready to read the data file and send the data to the Write API. As a best practice, you should send the data in batches rather than one row at a time. Read each JSON record into a JSONObject and collect a batch of them into a JSONArray:
To write each batch of records, call the JsonStreamWriter.append method. This method is asynchronous and returns an ApiFuture. For best performance, don't block waiting for the future to complete. Instead, continue to call append and handle the result asynchronously.
This example registers a completion callback. Inside the callback, you can check whether the append succeeded:
Handling table schema updates
BigQuery lets you modify the schema of an existing table in certain constrained ways. For example, you might decide to add a field named email that contains the commit author's email. Data in the original schema will have a NULL value for this field.
If the schema changes while you are streaming data, the Java client library automatically reconnects with the updated schema. In our example scenario, the application passes the data directly to the Write API without any intermediate processing. As long as the schema change is backward compatible, the application can continue streaming without interruption. After the table schema is updated, you can start sending data with the new field.
Note: Schema updates aren't immediately visible to the client library, but are detected on the order of minutes.
To check for schema changes programmatically, call AppendRowsResponse.hasUpdatedSchema after the append method completes. For more information, see Working with Schemas in the Write API documentation.
Query the data
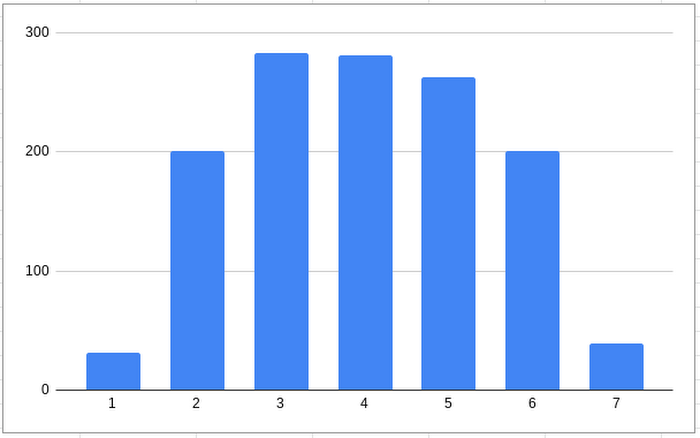
Our data is available for analysis as soon as it's ingested into BigQuery. For example, we can now run a query to find out which days of the week have the most commits:
It turns out that the busiest day is Tuesday. Not surprisingly, Saturday and Sunday have the fewest commits.
Conclusion
In this article, you learned how the Java client library makes it easy to stream JSON data into BigQuery. You can view the complete source code on GitHub. For more information about the Write API, including how to use committed and pending modes, see the BigQuery Storage Write API documentation.




