Google Cloud Vertex AI + Battlesnake: Using practical reinforcement learning to defeat your friends
Brad Egler
Senior Customer Engineer, Data
Mike Verbanic
Senior Customer Engineer, Infrastructure
How do you like to learn a new skill? Read books? Take a course? Try to build something? We are a small group of Customer Engineers who, with no formal background in machine learning, who decided to learn about reinforcement learning by entering Battlesnake, an online survival game where our trained agent would cut its teeth against competitors around the world.
Our project was fueled by Vertex AI, Google Cloud’s machine learning platform, and we share our process and lessons learned here in the hope it may inspire you to also learn by doing.

Let's consider a different approach utilizing the construct of a game to evaluate new technology and learn new skills.
Enter the arena
Battlesnake isn't your indestructible Nokia candy bar CDMA phone snake game. This isn't even an updated Google Snake spin off (but do try and get the secret rainbow snake), this is something very different and much more useful.
On the surface, Battlesnake seems like a simple game with a small number of basic rules:
Don’t run into walls or other snakes
Don’t starve
Don’t get eaten by another snake
Once you break through the basic premise, you’ll soon realize it is a lot more complicated than that.
There are many ways to build and place your own battlesnake into a competition. Depending on your team’s experience level you may want to try out one of the starter projects that Battlesnake makes available. Alternatively, you may want to start wading into the deeper end of the competitive pool and enhance your snake with health-based heuristics models or cannonball into the pool using a reinforcement learning approach.
The approach we took to our first competition was to hedge our bets a little - get something into competition quickly and gather some data to iterate on, then explore improvements on the initial snake performance through a series of ML model tweaks; ultimately building a reinforcement learning model that we were sure was going to win (in the most virtuous and collaborative sporting way of course). More on results later but here is walkthrough of how our architecture and development progressed:
Introduction to reinforcement learning
Reinforcement learning (often referred to as RL) has had a long history as a way to build AI models. From games like chess, Go and Starcraft II to more industry specific problems like manufacturing and supply chain optimization, reinforcement learning is being used to build best in class AI to tackle increasingly difficult challenges.
For those unfamiliar with RL, here is a quick primer:
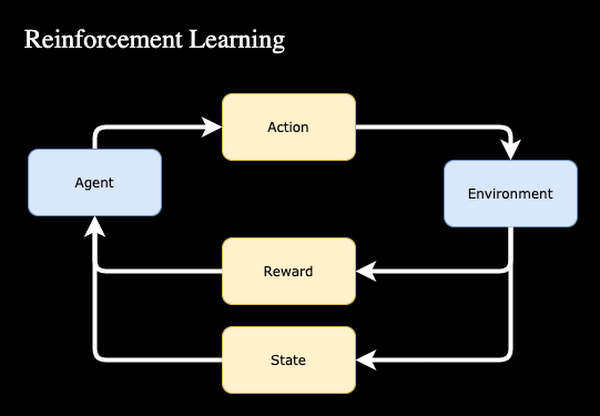
- Traditionally, machine learning models learn to make predictions based on massive amounts of labeled example data. In RL, agents learn through experimentation..
- Each iteration is scored based on a reward function. As an example for Battlesnake, a basic set of rewards might be a 1 for winning and a -1 for losing.
- The rewards are fed into the model so that it “learns” which moves earn the highest reward in any given scenario. Similar to humans learning to not touch a hot stove, the model learns that running a snake head first into a wall will produce a negative reward and the model will remember not to do that (most of the time).
- For complex systems this reward structure might consist of dozens of different inputs that help to shape the reward based on the current state of the overall system.
Our team did not have a classically trained machine learning expert but we did have enough expertise to take some concepts that we learned from others who had attempted this approach and apply them using Google Cloud’s Vertex AI platform.
How we charmed trained our snake
One of the key starting areas for building a RL model is to set up an environment that knows how to play the game. OpenAI's gym toolkit provides an easy way for developers to get started building RL models with a simple interface and many examples to start training your model quickly. This allows you to focus purely on the parts of the model that matter, like....
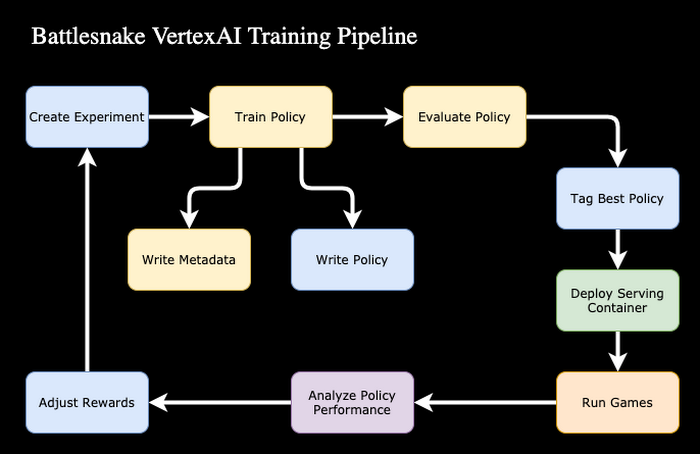
For our Battlesnake competition, we had one week to build, train and test a snake before throwing it into the arena against our peers in a winner takes all tournament. Though traditional ML loops can take weeks or months to build, with the power and simplicity of Vertex AI, we made an end-to-end ML pipeline in a few hours. This velocity freed up several days to run training experiments and tune our model.
Training on Vertex AI, in this case, started with a custom training job. Vertex AI allows you to specify your own training container (in our case we used Pytorch) to run any arbitrary training tasks on the Vertex AI managed infrastructure. Initial experimentation started in a basic Jupyter notebook hosted on Vertex AI but we quickly transitioned to a custom Docker container that was produced by Cloud Build on a push to our main source repository. We attempted to source our container image from multiple prebuilt images, but ultimately found that we were spending too much time working through conflicting dependencies which was slowing down our progress so we switched to a cleaner base image containing just the NVIDIA CUDA drivers.
As we started to scale our training we converted our notebook into an ML pipeline using Vertex AI’s managed pipeline service. The workflow took advantage of the built in hyperparameter tuning service to automatically tune our model to perform as well as possible with minimal supervision from our team. Each training job ran for 2-4 hours before going into the evaluation phase. During evaluation we selected previous versions of the model to run simulated games against to see if the newly trained model performed better than previous versions. The winner of the evaluation battles was promoted to the top model and the new baseline for the next iteration of training. Our pipeline was triggered on demand to do additional training. This was usually after we loaded the new model into the snake in the global arena and observed its behavior. If we were taking this fully to production we would have used the data we captured about game win rates to intelligently trigger additional training if the model was starting to underperform.
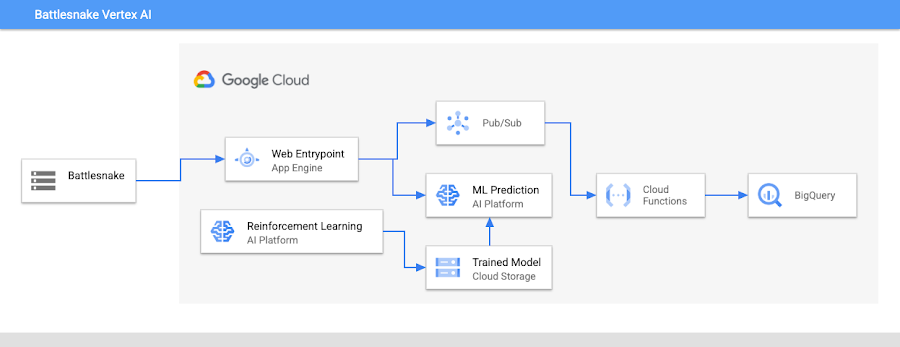
Deployment architecture
We deployed our top model to production using Vertex AI’s model serving infrastructure. The data sent from Battlesnake is a JSON document of all the current positions of the snakes, the food and any hazards that are on the board.
Responses from our server were required to be completed in 500ms. Any snake that “timed out” responding to requests from the game would continue moving in the same direction that it was already traveling. Given the time constraint we took a two pronged approach to control our snake. Requests from Battlesnake first came to a web service deployed on Google App Engine. The App Engine server forwarded the request to the model server with a hard timeout of 300ms. Responses from the model were validated in the App Engine server as a last fail safe, in case the model responded with a move that was clearly invalid (move outside of the board, etc.). If the model service timed out, the App Engine server fell back on its own logic to produce a reasonable move.
Data analysis
Our snake played thousands of games within the Battlesnake ecosystem both in the public arena and our private tournament. Each game consisted of tens to hundreds of moves and produced a finite result. As part of our experimentation we captured all the messages sent from the Battlesnake platform and fed them via Pub/Sub to BigQuery to be used later for statistical analysis of our performance. As mentioned in the previous sections, the data received from Pub/Sub was not in the standard tabular format but in an array of JSON objects. To perform analysis we first needed to convert the data into a standard table format. We leveraged the UNNEST function in BigQuery to flatten the record into the table. The data points in the messages from the battles consisted of the health, length, food location, head and body coordinates, turns and latency for all the snakes on the board including board size etc. For exploratory analysis of our ML model we attempted to answer questions like which snake did we battle the most and how did we perform in each of those battles? Is there a particular snake that keeps beating us? What are the frequent food locations? After gathering these insights, we can further refine how we tune our model parameters to what works best for our snake.
Conclusion
Our snake performed very well in open competition in the public arena but had a string of bad luck in actual tournament play. During the group stages we competed against two of the snakes that made it into the finals. The primary snake in our group was a hungry monster that quickly gobbled up food and boxed our snake out very effectively. This led to our untimely death by wall collision and a fast exit from tournament play. We accomplished a reasonable amount of success in the global arena for a very short amount of training time thanks to the power of Vertex AI.
To learn more
Battlesnake
Vertex AI - ML Training, Managed Pipelines, Hyperparameter Tuning, Model Serving
https://cloud.google.com/vertex-ai/docs/pipelines
https://cloud.google.com/vertex-ai/docs/training/hyperparameter-tuning-overview
https://cloud.google.com/vertex-ai/docs/predictions/deploy-model-console
Machine Learning
https://learndigital.withgoogle.com/digitalgarage/course/machine-learning-basics
https://ai.googleblog.com/2021/04/evolving-reinforcement-learning.html



