The differences between synchronous web APIs and asynchronous stateful APIs
Jordan Janeiro
Geir Sjurseth
Outbound Product Manager, Apigee
This article aims to differentiate the use cases that drive architectural decisions between async, and perhaps integration solutions, and synchronous and API driven solutions. Largely this isn’t an either or discussion. Many solutions rely on a ton of moving parts and to solve for that complexity a blend of both synchronous and asynchronous solutions is often the best approach. Furthermore, the types of problems one is solving for with traditional integration systems (often asynchronous) are different than the set of problems one solves for with API Management.
History: APIs before the service revolution
Application Programming Interface, or API, simply refers to a bridge that mediates interactions between two applications. These APIs define which calls can be made between applications, how these calls are made and wrap the whole piece up into a contract. Often this contract will even define the structure of the data that flows via the API.
Web APIs emerged as an ad hoc standard, originated on the extensibility of systems, in which developers used libraries and other systems through its APIs, contributing to the dissemination of a strong software engineering concept - software reuse. This concept evolved, continuing to implement software reuse in the context of the Internet, in which each service with a public endpoint can potentially be reused forming distributed systems.
In the context of Web APIs, no consortium or standards body specified the concept of Web APIs and its underlying protocols. However, the practice of Web APIs is based on publicly exposed endpoints that are available for communication and use the HTTP protocol, typically version 1.1, for this purpose. Web APIs also use the request-response messaging mechanism to exchange data, in which the originator of the communication (client) initiates the message with a request to a service provider. This in turn, results in a response back to the client. Typically, requests and responses have payloads in the data format of XML and JSON.
In the early 2000s we saw Service Oriented Architecture gain popularity in the enterprise space. And in the 2010s REST began its rise in popularity. These network based interactions that connected different applications whether it be SOAP (from the SOA world) or REST had one thing in common: they were all stateless.
There were, however, stateful integrations at play as well. Integration software was being used to connect disparate systems and translate payloads and protocols between systems. And, furthermore, many of these systems relied on the stateful nature of the setup to ensure delivery patterns that are very difficult to engineer using HTTP alone: guaranteed once delivery, at least once delivery, and even streaming topics where a producer of events never knows who’s or even how many are receiving the events.
Stateful async vs stateless sync
The internet and in particular the web and mobile internet thrive on stateless, HTTP based APIs. Nearly everything we do on our mobile devices is based on a client/server model that is mediated by an API. These APIs are stateless and that means that the underlying infrastructure requirements can scale up and down on demand and that there’s no single point required to handle a huge pool of connections.
Moreover, all of these HTTP APIs are mediating immediate and therefore synchronous transactions. Sometimes certain interactions take a long time and so the industry adapted to handle this need; how many of us have written an application that accepts a request and returns a `202 Accepted` in response only to begin the longer process of actually handling what is in reality a long running or perhaps asynchronous transaction.
Let’s take that previous example and explore it a bit. The world of mobile devices expects an immediate response. Returning a 202 is an appropriate response and it can be accompanied with a payload indicating that the request is `pending` or `in process`. That process may rely on a number of downstream factors out of reach for the server side developer. Consider a downstream application that is often offline. We may need to create a queue that keeps track of all of our incoming orders, but allow us to try and fail each one for a time. When that backend does come online it would be great if when we succeeded with the first, second, and third items in the queue if we could just continue until we hit the first couple of failures. At that point we can back off on trying for a time. Building a client/server style application on these types of interactions creates a terrible experience, but that doesn’t mean we don’t see these real needs in the real world.
When use API management or system integration
The API management discipline has its main focus on Synchronous HTTP APIs rather than Asynchronous Stateful APIs. This decision is mainly based on historical reasons associated with the emergence of HTTP APIs in the context of the World Wide Web. The WWW model is currently the most common standard for accessing resources through HTTP. The popularity of this model contributed to create the foundation that influenced the development of distributed applications, culminating in reusing the infrastructure of the Internet and the WWW model to turn APIs, used in libraries of programming languages for example, in HTTP APIs, which can now be endpoints available in the Internet to server information to requestors.
Alternatively, the discipline of system integration had its main focus on both Synchronous Web APIs and Asynchronous Stateful APIs, which are built with enterprise service buses (ESBs). The implementation of APIs in ESBs is less dependent on the HTTP, as ESBs support a different set of protocols, such as JMS, AMQP and others.
Choosing a discipline to adopt depends on the nature of the use cases that need to be implemented.
The value proposition of the API management discipline
The API management discipline is more suitable for organizations that have the strategic goal to become an active player in the digital economy and be recognized by it. Companies that pursue this strategy are interested in exposing public or private APIs to reach out to a community of developers with a natural interest in these, as they contribute to aggregate value to the apps by reuse. For example, not all companies that develop apps based on geolocation services need to implement a service such as Google Maps; they can reuse the APIs of Google Maps to aggregate value without rebuilding a similar service.
The API management discipline tackles directly these types of situations, as it defines a set of concepts that allow companies to expose APIs, mainly taking into consideration:
- the frictionless onboarding of API developers,
- tracking the usage of the APIs by these developers and
- ease to access APIs over the Internet.
In API management, app developers that need to consume APIs offered by 3rd parties, need frictionless developer experience to understand, try, subscribe and consume these APIs. Developers need different mechanisms, like mature developer portals, freemium rate plans and guidelines to explore the different outcomes of using APIs and being successful in becoming experts in their use. These mechanisms should contribute to acquiring and quickly converting occasional developers exploring APIs into developers that become customers and are willing to pay for quality services. Therefore, the API management discipline foresees the use of all possible mechanisms that can contribute to this positive experience.
The success of API programs depends not only on its implementation of APIs and their public availability but also on understanding consumption trends of these APIs. Companies need to understand the number of app developers that are consuming their APIs, the number of API calls that are being generated, together with the additional revenue caused by their consumption and the frequency in which app developers, under a freemium model, are converted to a rate plan. This information is necessary to identify the popularity of some APIs over the others and provides insights. Decision makers can make informed decisions and favor APIs and API Products that are successful over those that are less successful. Such information is generally automatically collected by an API management platform, such as Apigee, and presented in the form of dashboards to facilitate consumption. These dashboards can also be customised to adapt to the different realities and characteristics of API programs across companies but the original intent remains - there should be mechanisms to determine the success of API programs in general. Therefore, the API management discipline encourages the implementation and use of API tracking mechanisms associated with their consumption by developers.
Finally, as the strategy of companies is to reach out to an unknown number of app developers, offering its own APIs, it is important that the APIs are easily consumable by developers without introducing additional technological components that can act as barriers. This is a main reason for the API management discipline to have built Web APIs using the standard and widespread HTTP in the communications. It should be straightforward for Web developers accustomed to this protocol to become API developers by using and consuming them. Therefore, the API management discipline, through its API management platforms, expose APIs as synchronous Web APIs that depend only on the request-response messaging pattern supported by HTTP.
The value proposition of the system integration and async discipline
The world of System Integration is primarily focused on solving tactically for the technical communications between systems. Rather than creating a marketplace for engagement this space aims to define interfaces that solve for a list of problems usually associated with internal only systems and tightly bound with the core business logic. On internal networks we’ll see a variety of protocols, backends, and latencies. We need a way to account for all of this complexity and meanwhile making it as easy as possible to create stable, and easily adopted services. Messaging systems that rely on queues, topics, and streams are often top of mind, but there’s an additional set of high priority items endemic to this space. Here is a non-exhaustive list where each one builds upon the last. We’ll go through each one individually.
- Protocol Translations
- Transaction Integrity
- Exception Handling
Protocol translations
The world of API development revolves around HTTP, but the concerns inside any large organization can span all kinds of protocols, versions, and sockets. Here, the integration world attempts to account for those needs by offering gateways and stateful systems that translate these needs. Here you may find a service that accepts client communications over HTTP, but then has a persistent runtime connected to a backed queue hosted on RabbitMQ, or consuming a topic hosted on Kafka. You may find an integration with a custom trigger looking for updates or inserts in a given table. On every change to that table the system may grab that event and emit a new event in the form of message sent to the queue or a topic: thereby translating the DB world to the Message world and offering systems that don’t need to understand DB logic the ability to simply subscribe to the topic instead.
gRPC
Just a quick note on gRPC. gRPC relies on http/2 and does provide the ability to work with both synchronous and asynchronous patterns. It’s still an http bound protocol, however, is really about how developers create services and consume them and less about how one might need to integrate web systems with database and queueing systems. One could use gRPC or RESTful APIs to do this and the basic principles would be the same. Further exploration of gRPC is beyond the scope of this paper.
Transaction integrity
The API world is world based on stateless, fire and forget style http requests. The integration world, meanwhile, is often handling transaction wrappers that handle distributed transactions and often while connected to stateful backend systems. Consider a pattern where a client wants to make a banking transaction and move funds from one account to another (maybe even in two different banks): a classic example. It’s imperative that the debit of funds from the source account doesn’t occur if the credit of the funds to the target account fails. This is transaction integrity and in the case here a distributed transaction. Handling this type of low-level logic in your API Gateway is not only an antipattern, but most certainly involves systems that simply cannot communicate over HTTP. We need other systems that not only handle these protocols, but that can build a transaction system on top of others; and if necessary roll back those transactions in case of a failure.
Exception handling
Finally, we get to the exceptions which are the culmination of the previous two topics. In the previous example we considered a distributed transaction and the requirement to roll back any part of it if there’s any issue. But what if we’d like the system to try again, and if it fails again to keep trying for up to 5 times. What if on top of this we’d like to increase the time between retries i.e. a backoff function. Obviously, this could never be accomplished during the lifetime of a single HTTP request, and building systems that can account for these types of transactions are by their very nature asynchronous. Asynchronous systems are often characterized by their persistent nature, and the fact that systems react to incoming events. All of this is true, but the ability to build in retries, proper exception handling and even backoff functions are equally important traits.
A real world example
Given the needs APIs are trying to address and space addressed by the world of Integration and Asynchronous systems what might a real world scenario look like that adopts both of these? Let's consider the following example and like before it’s not exhaustive, but should illustrate how we might combine both of these types of systems.
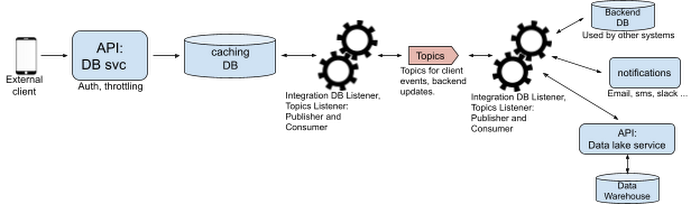
The frontend client
We have an external client shown here as a mobile phone. Let’s consider this an app developed by a developer that’s consuming APIs. The API GW can uniquely identify this application, throttle the application, and collect analytics. Furthermore, it’s fronting a lightweight db service which updates its own caching database. When a new order comes in, let’s call it a service order, the system writes a row to the caching DB and returns a 202 with a body informing the application that a new order is pending.
The first integration
We’ve set up an integration pattern to listen to that caching DB and pick up any new service orders. Assuming we have a new order that integration is triggered and emits an event to the “New Service Order” topic hosted on the Topics (let’s assume it’s a kafka cluster hosting this and other topics).
The second integration
Like before we have another integration setup waiting on events. This time the integration is waiting on new events published to the “New Service Order” topic. We get a new order and that integration now updates a backend database (setting up the new order properly), sends notifications to other parties, and sends an API Request to our Data lake service which in turn updates the Data Warehouse. If any part of this fails it needs to retry for a time and if ultimately necessary roll back any of these transactions. If it succeeds it will emit a new message to another topic: “Updated Service Order”.
Back to the first integration
That first integration is also listening for updates on the “Updated Service Order” topic. Here we receive an update that includes the finished service order id. The system now updates the caching DB with the new information and changes the “pending” status to “in process.” If the mobile client checks on the status again it will retrieve the updated “in process” status as stored in the caching DB and hosted by the DB service.
All together
We can imagine more complexity here as well. Perhaps the Data Lake Service isn’t the only downstream subscriber interested in “New Service Order'' events. Likewise, we can imagine that the DB service isn’t the only service interested in “Updated Service Order” events. Consider an application that creates the pending service order, but then never lets the user check for an update until it has received a notification. We could have another service that sends a push notification. By stitching together these asynchronous and synchronous events we build a system that’s easy to scale and extend, but also engaging for developers and properly discriminates between business logic needs and simple API contract requirements.
Conclusion
Architectural decisions often drive the decision to use synchronous or asynchronous patterns, and often a complete end to end solution will rely on both. With that said it’s still important to understand these patterns and how developers engage with these systems that rely on these patterns.
Asynchronous systems are often solving integration problems, translating between protocols, handling stateful sockets and more. Those systems are built to cater for those specific needs. API Management systems and APIs in general are built to make it as easy as possible for developers to find and use those APIs. Moreover, those APIs are usually stateless, RESTful APIs that are only using a single protocol: http. Complex architectures require both types of platforms and understanding when and how one uses each of these is crucial for an elegant system design. It’s also important to understand what expectations one should have for these systems. One shouldn’t try and solve integration challenges with API Management, and likewise trying to solve for API Management challenges with traditional integration systems will leave you struggling to handle developer engagement and dynamic scaling.