Automating self-service tech support with Tensorflow

Gus Kristiansen
Machine Learning Engineer
Max Saltonstall
Developer Advocate
Speed up access to self-service tech support content with AI that can better parse and surface the right articles for the right queries.
What would tech support be like if an AI agent could recommend the right self-service article before a human support agent even got on the ticket?
At Google we wanted to find out. So we got our machine learning teams working on ways to suggest support documentation automatically integrated into our ticketing system, before human responses come in.
This is the perfect kind of AI problem: lots of data available, a decision that happens many times, major natural language component and the potential to gain tens of thousands of person-hours back in productivity. High impact and less complex than some of our other IT challenges.
Getting support faster
Googlers make use of knowledge-base support articles to help them troubleshoot and solve common technical issues at work. A self-service channel like this makes it easy for people to help themselves and relieves agents from the stress of repeatedly responding to recurring, well-documented issues. When someone doesn’t take advantage of self-service articles, it can be a time-consuming experience: for the requester, who is routed through chat channels or tickets and dependent on an available agent, and for the agent, who must walk users through the problem solving steps. An efficient way to help both sides would be to automatically surface self-service support articles in chat and ticket channels - saving search time for agents and providing immediate help to users.
The old, painful, slow, manual way
Support technicians currently respond to tickets manually, either by sending one of the support articles or relaying the information directly. Currently there is a regular expression (regex) solution that tries to identify when a support article might be helpful. The regexes are handcrafted rules and not as robust as a machine learning model could be. This system fails to adjust to newly arising issues unless someone makes new rules by hand.
Speed it up with ML
We can do better. A new system, offering replies generated by a Machine Learning (ML) model, can speed things up and provide near-instant replies using existing documentation.
Users submitting support tickets receive ML-suggested help center articles ahead of human-powered support. The model evaluates a user’s problem description in the ticket and, if available, instantly emails the user an existing help center article that may resolve the issue.
Benefits of this process:
- Saves time for the techs without a major impact on users in cases where the model fails.
- Solves more tickets at first touch and saves Googlers thousands of hours they would have spent waiting for human support.
Often this meant the difference between waiting two or three hours for a ticket response to getting a response in under a minute, for a decent chunk of our ticket pool.
Tensorflow and BERT
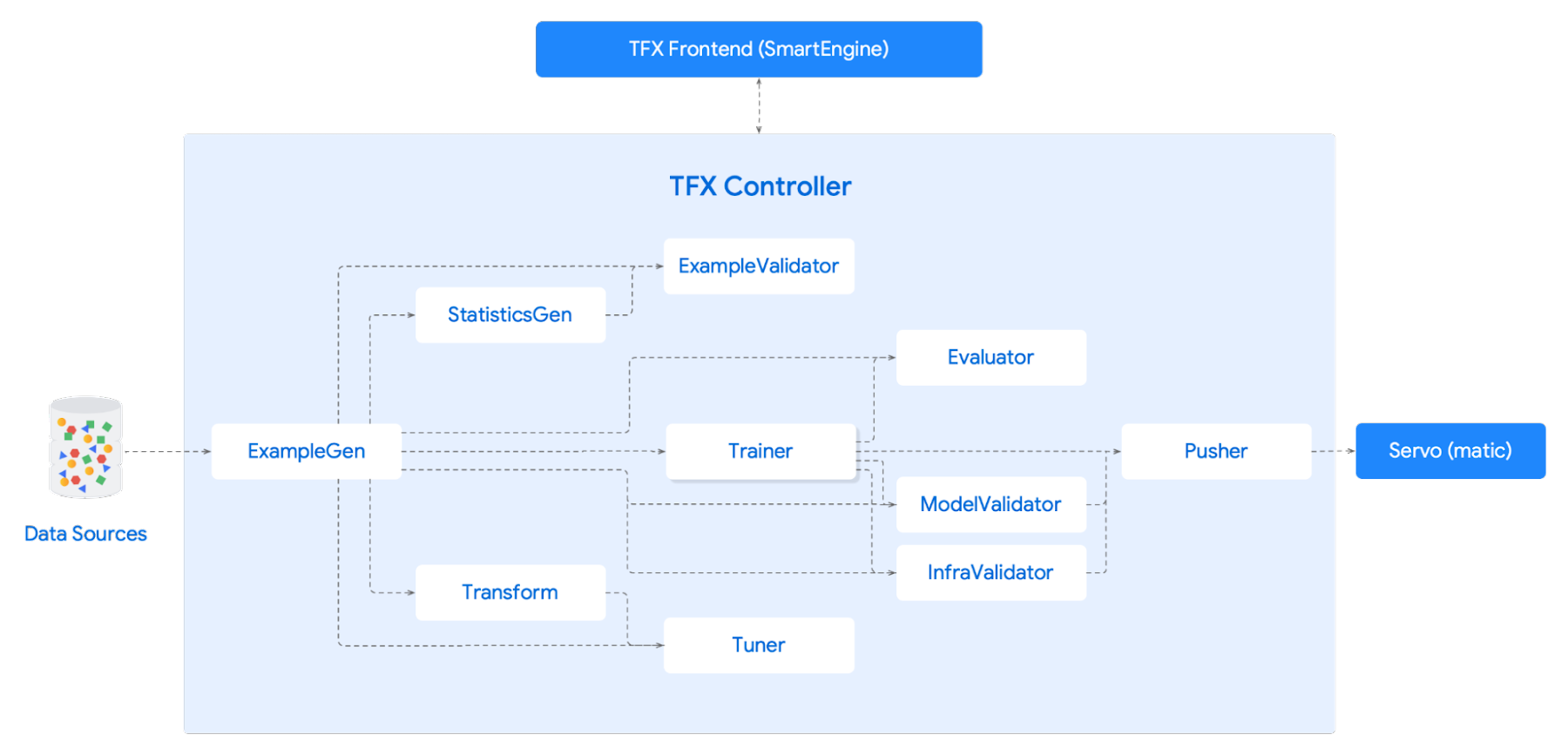
We tried out a few different types of machine learning models. A fully connected Deep Neural Network with TF-IDF featurization was the simplest, and a fine-tuned BERT model was the most complex. Surprisingly TF-IDF ended up working the best, potentially because we didn’t have enough training data (only hundreds of thousands of tickets) to take full advantage of BERT. The difference wasn’t huge, but TF-IDF is a lot cheaper to train and serve. We have an entire pipeline set up using TFX that allows us to get the latest data, train a model, and serve that model all automatically. We leverage the tickets where techs have manually responded with support articles as training data for the model.
In the end our toolchain consisted of:
- Tensorflow for ML modeling
- TFX for prototyping, retraining, and serving the models
- Servomatic, an internal tool to serve the models to the support team
- Vizier for hyperparameter tuning, including batch size, learning rate, vocabulary size, hidden layers
- TF Hub to spin up our BERT model
We took advantage of TFHub to quickly get a BERT model running, enabling us to test out various types of models and find the best one for our goals.
Our initial performance came in below expectations. Inspecting the model more closely, we realized the cause of the poor answers was not the model but the data we were feeding in. We had a data issue!
The training data was noisy due to tickets where a tech did not suggest an article but manually relayed the information. To solve this problem, we had humans label a portion of the dataset to create a handcrafted set of tickets and labels for model validation. This allowed us to tune our models using data we knew was extremely accurate. We found out our models were actually performing much better than we thought.
Another caveat is that the model will sometimes suggest an article that isn’t helpful. In these cases there may be a slight annoyance to the user, but it should not cause a significant delay in their problem getting solved, because we'll follow up with human support if the issue remains open after an auto-response.
How to solve article suggestion yourself
To replicate a similar solution, you'll need a few key ingredients:
- Data - we used hundreds of thousands of examples, but more is even better. You want tickets where a support person solved them by linking to an existing article
- ML library with NLP - something that can handle embedding or bag-of-words transformations
- Model serving - a way to run your model for any request and return its results.
Google's AutoML services, including the Natural Language modules, can make getting started very fast, and allows you to quickly test out whether this sort of augmentation can help your help desk as it helped ours. You can see a walkthrough for basic text classification with Tensorflow; if you want to solve this with BERT and get more rapid results, you will want to try it out using TPUs.
Remember to iterate. We didn't get it right on the first try, and found our ideal solution through experimentation and comparing various options. Try, try again, and keep your focus on your end goal.



