How Udacity students succeed with Google Cloud

Will Kessler
Director, Content and Classroom Experience at Udacity
Editor’s note: Today we hear from Udacity, which uses a variety of Google Cloud technologies for its online learning platform. Read on to learn how they built online workspaces that give students immediate access to fast, isolated compute resources and private data sets.
At Udacity, we use advanced technologies to teach about technology. One example is our interactive “Workspaces,” which students use to gain hands-on experience with a variety of advanced topics like artificial intelligence, data science, programming and cloud. These online environments comprise everything from SQL interpreters to coding integrated development environments (IDEs), Jupyter Notebooks and even fully functional 3D graphical desktops—all accessible via an everyday browser.
To build these Workspaces, we relied heavily on Google Cloud Platform (GCP) in numerous interesting and novel ways. This article details our implementation and where we hope to take it in the future.
Workspaces design goals
Udacity customers are smart, busy learners from all over the world, who access our courses remotely. To meet their needs, we designed Udacity Workspaces to:
Be ready to use in under 15 seconds
Offer advanced functionality directly inside the browser-based Udacity Classroom
Instantly furnish starter and example files to students in a new Workspace, and automatically save all student work and progress for the next session
Provide quick access to large external datasets
Function well with any session duration… from two minutes to four hours, or more
Provide reliable compute availability and GPU power wherever needed
We chose GCP for its ease of use, reliability, and cost-effectiveness. Let’s see how we used different GCP offerings to meet these goals.
Fast, personalized access to Workspaces
Students demand immediate access to their Workspaces, but booting up a full GCP host from an image can take awhile. That’s OK if a student plans on using their Workspace for an hour, but not if they’re using it for a two minute Workspace coding challenge.
To address this, we built a custom server management tool (“Nebula”) that maintains pools of ready servers to assign to students immediately. To control costs, the pools are sized by a custom usage-pressure measurement algorithm to be fairly surge ready, but which also reduces the pools to as small as a single instance during idle periods. Pools are maintained in multiple data centers, to maximize access to GPUs.
GCP’s by-the-second pricing and flexible reservations policy served us well here. Given the short usage windows of some student exercises, hourly billing or bulk billing might have proved cost prohibitive.
Having ready-to-go server pools minimizes startup time, but we also needed to place “starter files,” or later on, the student’s own work from a previous session, onto the hosts as quickly as possible. After experimenting with several approaches, we decided to store these files as tarballs in Cloud Storage. We found that we can copy up to 3GB to and from Cloud Storage within our SLA time window, so we set a hard limit of 3GB for student drives.
Every time a student’s session goes idle for half an hour, we deallocate the host, compress and copy the student’s files to Cloud Storage, then delete the host. In this manner we make time-stamped backups of each session’s files, that students can opt to restore any time they need to (via the Workspaces GUI). An alternative approach could be to leverage Cloud Storage’s version control, which provides access to GCP’s lifecycle controls as well. However, at the time we built the student files storage system, this GCP feature was still in beta, so we opted for a home-grown facility.
In addition, we take advantage of Cloud Functions to duplicate the student files in a second region to ensure against regional outages. Side note: if we were to build this feature today, we could take advantage of dual-region buckets to automatically save student files in two regions.
Access to large datasets
From time to time, students need to access large datasets, e.g., in our machine learning courses. Rather than writing these datasets on server images, we mount read-only drives to share a single dataset across multiple student hosts. We can update these datasets on new shared drives, and Nebula can point new sessions at these new drives without interrupting existing session mounts.
To date, we’ve never run into a concurrent read-only mount limit for these drives. However, we do see a need for quick-mount read-write dataset drives. One example could be a large SQL database that a student is expected to learn to modify in bulk. Duplicating a large drive on-the-fly isn’t feasible, so one approach could be to manage a pool of writeable drive copies to mount just-in-time, or to leverage Google Cloud’s Filestore.
With the Filestore approach, you’d pre-create many copies of data drives in a folder tree, and mount a particular folder on the Filestore to a specific student’s container when access is needed; that copy would then never be assigned to anybody else, and asynchronously deleted/replaced with a fresh, unaltered copy when the student’s work is finished.
Consistent compute power
In a shared environment (e.g. Google Kubernetes Engine ), one student’s runaway process could affect the compute performance of another student’s entire container (on the same metal). To avoid that, we decided on a “one-server-per-student” model, where each students gets access to a single Compute Engine VM, running several Docker containers—one container for the student’s server, another for an auto-grading system, and yet another for handling file backups and restores. In addition to providing consistent compute power, this approach also has a security advantage: it allows us to run containers in privileged mode, say, to use specialized tools, without risking a breach beyond the single VM allocated to any one student.
This architecture also ensures that GPU-equipped hosts aren’t shared either, so students benefit from all available performance. This is especially important as students fire up long-running, compute intensive jobs such as performing image recognition.
As a cost control measure, we meter GPU host usage and display available remaining GPU time to students, so they switch their GPUs on and off. This “switching” actually allocates a new host from our pools to the student (either GPU-enabled or not). Because we can do the switch in under 15 seconds, it feels approximately like a toggle switch, but some aspects of the session (such as open files) may be reset (e.g., in an IDE configuration). We encourage students to ration their GPU time and perform simpler tasks such as editing or file management in “CPU mode.”
One of our GPU host configurations provides an in-browser Ubuntu desktop with pass-through Nvidia K80 GPUs for high-performance compute and graphics. This configuration is heavily employed by our Autonomous Systems students, who run graphics-intensive programs like Gazebo (shown), and run robot environment simulations. You can read more about this configuration here.
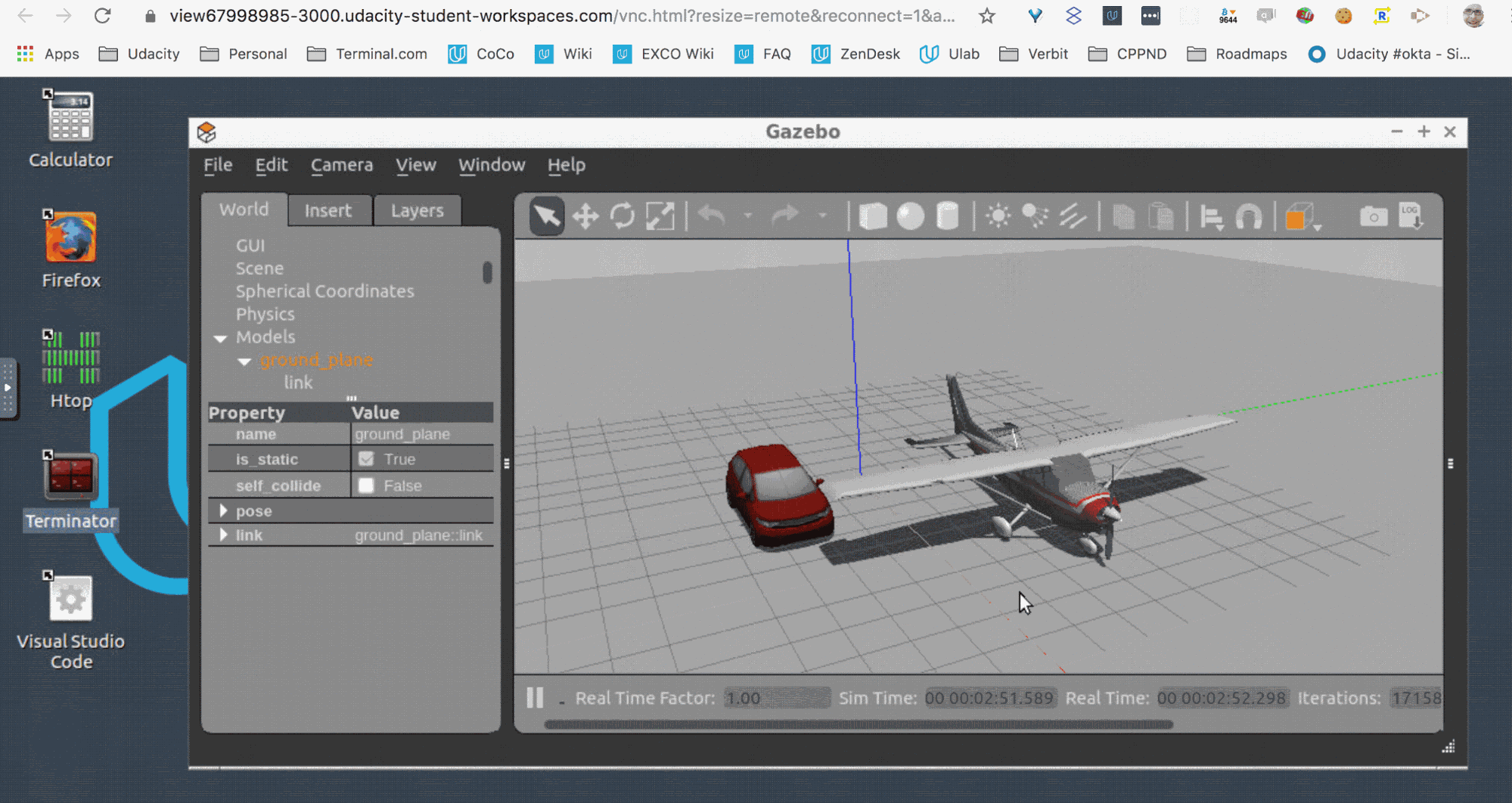
Wanted: flexible and isolated images
This configuration has hit all our goals except for true image flexibility. For our large variety of courses we require many variations of software installations. Normally such needs would be satisfied with containers, but the requirement of isolated compute environments eliminates that as an option.
In the past two years, we’ve empowered hundreds of thousands of Udacity students to advance their careers and learn new skills with powerful learning environments called Workspaces, built on top of GCP. Throughout, GCP has proven itself to be a robust platform and a supportive partner, and we look forward to future product launches on top of Google Cloud. If you’d like to learn more about the solutions we’ve built, feel free to reach out to me on Twitter, @Atlas3650.



