Finding a problem at the bottom of the Google stack
Steve McGhee
Solutions Architect, Google Cloud
At Google, our teams follow site reliability engineering (SRE) practices to help keep systems healthy and users productive. There is a phrase we often use on our SRE teams: "At Google scale, million-to-one chances happen all the time." This illustrates the massive complexity of the system that powers Google Search, Gmail, Ads, Cloud, Android, Maps, and many more. That type of scale creates complex, emergent modes of failure that aren’t seen elsewhere. Thus, SREs within Google have become adept at developing systems to track failures deep into the many layers of our infrastructure. Not every failure can be automatically detected, so investigative tools, techniques, and most importantly, attitude are essential. Rare, unexpected chains of events happen often. Some have visible impact, but most don't.
At Google scale, million-to-one chances happen all the time.
This was illustrated in a recent incident that Google users would likely not have noticed. We consider these types of failures "within error budget" events. They are expected, accepted, and engineered into the design criteria of our systems. However, they still get tracked down to make sure they aren’t forgotten and accumulated into technical debt—we use them to prevent this class of failures across a range of systems, not just the one that had the problem. This incident serves as a good example of tracking down a problem once initial symptoms were mitigated, finding underlying causes and preventing it from happening again—without users noticing. This level of rigor and responsibility is what underlies the SRE approach to running systems in production.
Digging deep for a problem’s roots
In this event, an SRE on the traffic and load balancing team was alerted that some GFEs (Google front ends) in Google's edge network, which statelessly cache frequently accessed content, were producing an abnormally high number of errors. The on-call SRE was paged. They immediately removed ("drained") the machines from serving, thus eliminating the errors that might result in a degraded state for customers. This ability to rapidly mitigate an incident in this way is a core competency within Google SRE. Because we have confidence in our capacity models, we know that we have redundant resources to allow for this mitigation at any time.
At this point, our SRE had mitigated the issue with the drain, but they weren’t done yet. Based on previous similar issues, they knew this type of error is often caused by a transient network issue. After finding evidence of packet loss, isolated to a single rack of machines, our SRE got in touch with the edge networking team, which identified correlated BGP flapping on the router in the affected rack. However, the nature of the flaps hinted at a problem with the machines rather than the router. This indicated that the problem revolved around a particular machine or set of machines.
Further investigation uncovered kernel messages in the GFE machines' base system log. These errors indicated CPU throttling:
MMM DD HH:mm:ss xxxxxxx kernel: [3220998.149713] CPU16: Package temperature above threshold, cpu clock throttled (total events = 1596886)
The process on the machine responsible for BGP announcements showed higher-than-usual CPU usage, which perfectly correlated with both the onset of the errors and the CPU throttling. This confirmed the theory that the throttling was significant enough to be impactful and measurable by Google's monitoring system:
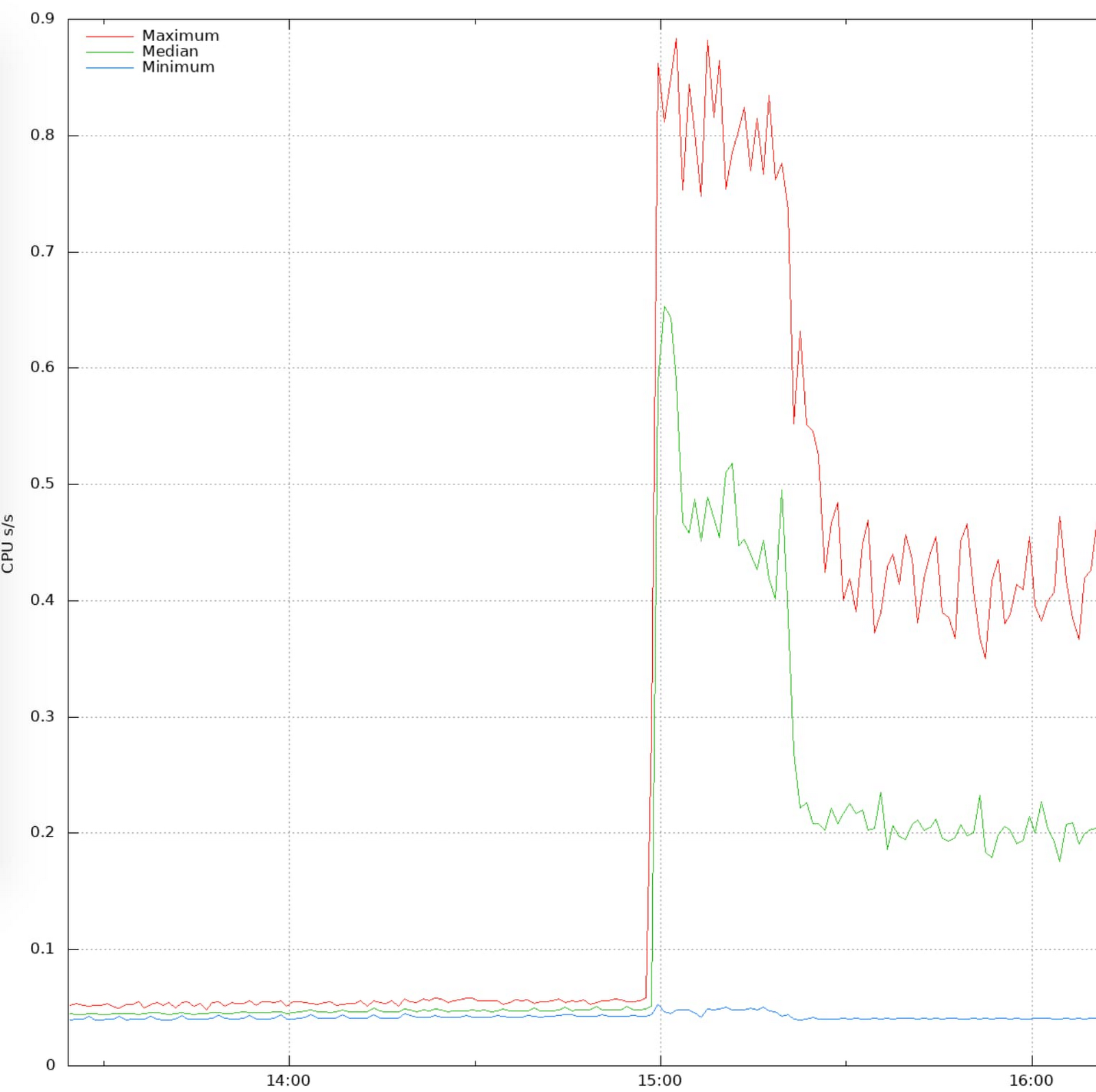
The SRE then checked on adjacent machines to find if there were any other similarly failing systems. Notably, the only machines that were affected were on a single rack. Machines on adjacent racks were not affected!
Why would a single rack be overheating to the point of CPU throttling when its neighbors were totally unaffected?? What is it about the physical support for machines that would cause kernel errors? It didn't add up.
The SRE then sent the machine to repairs, which means that they filed a bug in our company-wide issue tracking system. In this case, the bug was sent to the on-site hardware operations and management team.
This bug was clear and to the point:
Please repair the following:Machines in XXXXXX are seeing thermal events in syslog:MMM DD HH:mm:ss xxxxxxx kernel: [3220998.149713] CPU16: Package temperature above threshold, cpu clock throttled (total events = 1596886)This throttling is ultimately causing user harm, so I've drained user traffic.
This bug, or ticket, clearly specified the machine(s) that were affected and described the symptoms and actions taken up to that point. At this point, the hardware team took over the investigation and determined the physical issue that resulted in this chain of events in the software. Google's 24x7 team is composed of many teams, working together to ensure problems are well-understood at all levels of the stack.
Finding the cause of a chain of events
So what was the problem?
Hello, we have inspected the rack. The casters on the rear wheels have failed and the machines are overheating as a consequence of being tilted.

The wheels (casters) supporting the rack had been crushed under the weight of the fully loaded rack. The rack then had physically tilted forward, disrupting the flow of liquid coolant and resulting in some CPUs heating up to the point of being throttled.

The caster got fixed and the rack was returned to proper alignment. But the greater issues of "How did this happen?" and "How can we prevent it?" needed to be addressed.
The hardware teams discussed potential options, ranging from distributing wheel repair kits to all locations to improving the rack-moving procedures to avoid damaging the wheels, and even considered improving the method of transporting new racks to data centers during initial build-out.
The team also considered how many existing racks risk similar failures. This then resulted in a systematic replacement of all racks with the same issue, while avoiding any customer impact.
Talk about deep analysis! The SRE tracked the problem all the way from an external, front-end system down to the hardware that holds up the machines. This type of deep troubleshooting happens within Google's production teams due to clear communication, shared goals, and a common expectation to not only fix problems, but prevent all future occurrences.
Another phrase we commonly use here on SRE teams is "All incidents should be novel"—they should never occur more than once. In this case, the SREs and hardware operation teams worked together to ensure that this class of failure would never happen again.
All incidents should be novel.
This level of rigorous analysis and persistence is a great example of incident response using deep and broad monitoring and the culture of responsibility that keeps Google running 24x7.
Google Cloud customers often ask how SRE can work in a hybrid, on-prem, or multi-cloud environment. SRE practices can be used to work across teams within an organization, across multiple environments. SRE helps teams work together during incidents like this, from traffic management to data center hardware operations.
Find out more about the SRE approach to running systems and how your team can adopt SRE best practices.



