Everything you need to know about architecting reliable infrastructure for Google Cloud workloads
Nir Tarcic
Senior Staff Engineer, Google
Kumar Dhanagopal
Cross-Product Solution Developer
Do you worry about the reliability of your workloads in the cloud? Does the thought of application downtime give you sleepless nights? At Google, we also think about reliability a lot — and take steps to ensure your workloads are running on a reliable foundation: We’ve designed Google Cloud to tolerate infrastructure failures and recover quickly from them, and we continually invest and innovate to prevent outages and to improve the resilience of the Google Cloud infrastructure.
To help you build and manage reliable infrastructure for your cloud workloads, we’ve also developed a comprehensive Google Cloud infrastructure reliability guide, which combines industry-leading reliability best practices with the knowledge and deep expertise of reliability engineers across Google.
What does reliability really mean?
The introductory part of the Google Cloud infrastructure reliability guide helps you understand how reliability can imply different outcomes for different workloads. For example, reliability indicators for a content-serving application can be different from the reliability indicators for databases or analytics workloads.
Why should I worry about reliability? Shouldn’t Google Cloud manage this for me?
Yes! Google Cloud services provide SLAs. However, to make appropriate design choices when building reliable infrastructure for workloads in the cloud, you need to understand the platform-level reliability capabilities of Google Cloud. The Google Cloud infrastructure reliability guide walks you through the building blocks of reliability in Google Cloud and how these building blocks affect the availability of your cloud resources. You’ll get a deeper understanding of regions, zones, and platform-level availability targets for applications deployed in a single zone, in multiple zones, or across regions. And you’ll understand the differences in reliability between zonal, regional, and global resources.
Okay, how do I design reliable infrastructure for my workloads in Google Cloud?
To take advantage of the building blocks in Google Cloud to build reliable infrastructure, you need to first assess the reliability requirements of your workloads. Identify the reliability requirements as granularly as possible, so that you can focus your IT spending on the requirements that are most critical. Identify periods when availability might be relatively more business-critical, and consider the tradeoffs between reliability and other requirements.
After assessing the reliability requirements of your workloads, you need to design reliable infrastructure in Google Cloud to protect the workloads against failures at the resource, zone, and region level. The Google Cloud infrastructure reliability guide emphasizes the importance of avoiding single points of failure (SPOFs) in your application stack. The guide presents deployment architectures that you can choose from to distribute resources across locations and deploy redundant resources:
A single-zone architecture might suffice for workloads that can tolerate downtime or for applications that you can deploy quickly at another location when necessary.
A multi-zone architecture is suitable for workloads that need resilience against zone outages but can tolerate some downtime caused by region outages.
A multi-region deployment architecture is ideal for workloads that are business-critical and where high availability is essential, such as retail and social media applications.
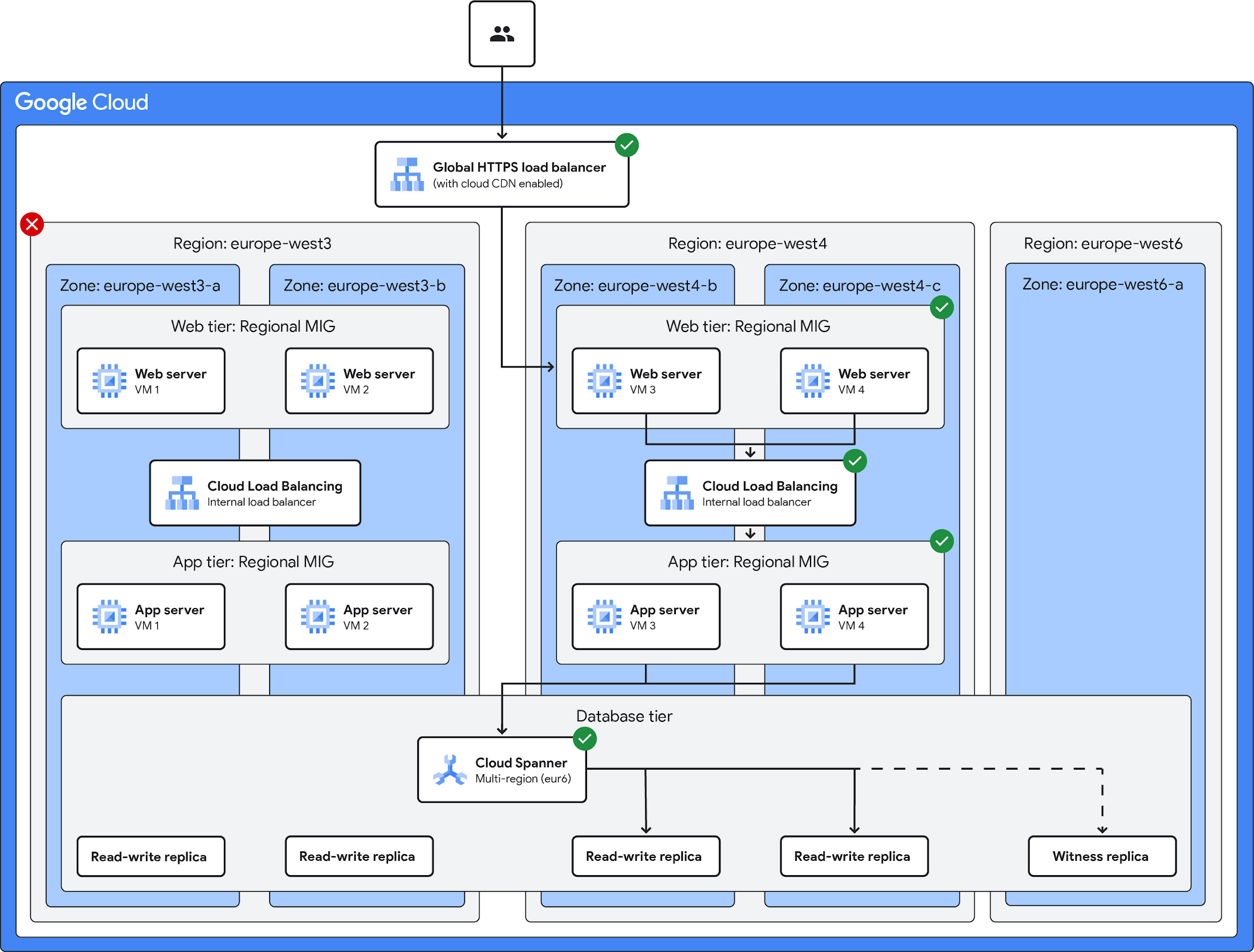
Multi-region deployment with global load balancing
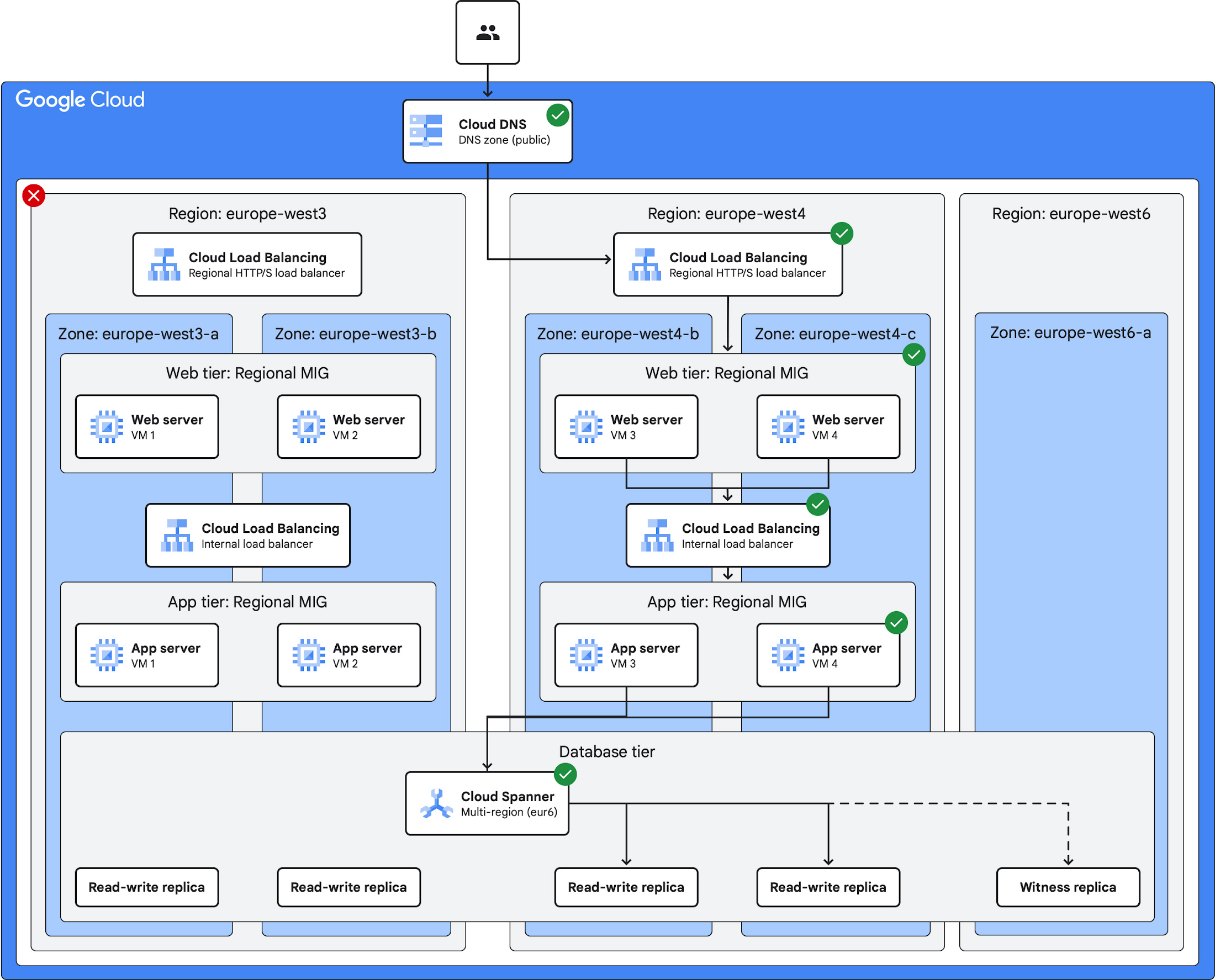
Multi-region deployment with regional load balancing
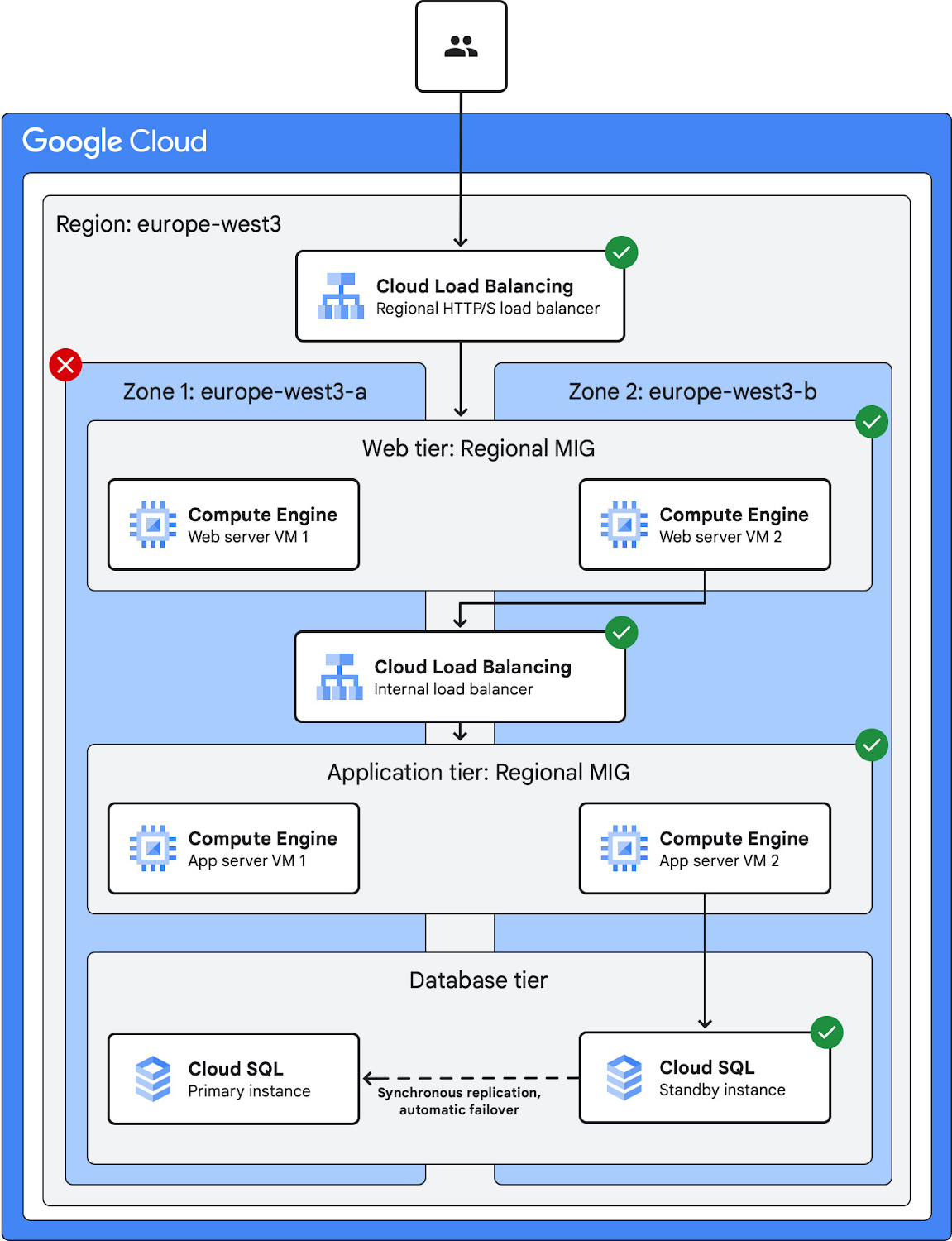
Multi-zone deployment
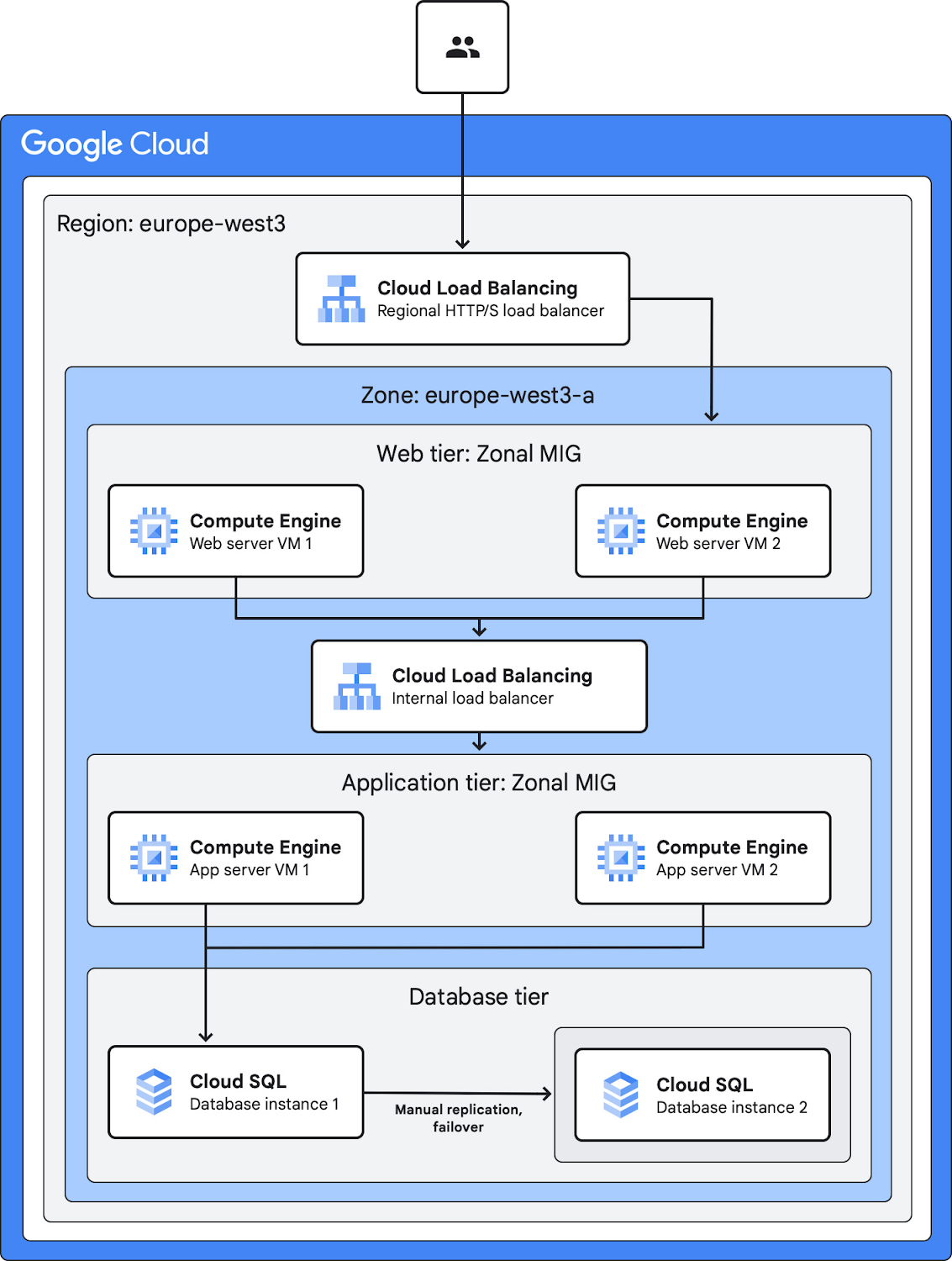
Single-zone deployment
When you run distributed workloads in the cloud, it’s important to make sure that traffic is routed efficiently to the available resources across different locations. The Google Cloud infrastructure reliability guide discusses traffic and load-management techniques like capacity planning, autoscaling, and load balancing, which you can use to improve the reliability of your cloud workloads. The final part of the guide summarizes change-management guidelines to reduce the reliability risk of the infrastructure resources: deploying infrastructure changes progressively and controlling changes to global resources.
Distributed deployments can help ensure high availability for your most critical business applications. But that’s not all. To ensure business continuity during extreme failure events, you can take additional steps beyond simply distributing your cloud resources across locations. For example, you can implement operational practices for DR testing, managing incidents, verifying application functionality after incidents, and performing retrospectives.
This is great! But I need more help.
After reading the Google Cloud infrastructure reliability guide, if you need further assistance with architecting reliable infrastructure for your cloud workloads, contact a Google Cloud specialist. Tell us about your workloads and reliability goals. We’ll help you understand and evaluate the architectural options for designing reliable infrastructure.
Where can I learn more about running reliable workloads in Google Cloud?
Review patterns and best practices for building scalable and resilient applications.
Learn about strategies and techniques for rate limiting.
Implement best practices for mitigating ransomware attacks.
Design your workloads for disaster recovery (DR) in the cloud.



