Take charge of your data: Using Cloud DLP to find and protect PII
Scott Ellis
Senior Product Manager
Editor’s Note: We’re kicking off a series of “taking charge of your data” posts, which give you tips about how to leverage solutions like the Cloud Data Loss Prevention API to discover, protect, and make use of your sensitive data.
Being a good steward of your business’s data, and that of your users, is of critical importance. Protecting your data isn’t just about making sure your storage buckets are configured correctly, although that’s a big part of it. It’s important to take a holistic look at where your data resides and how it’s being used, and then create processes to ensure it’s being handled appropriately.
Sensitive data can show up in unexpected places—for example, customers might inadvertently send you sensitive data in a customer support chat or upload. And if you’re using data for analytics and machine learning, it’s imperative that sensitive data be handled appropriately to protect users’ privacy.
Over many years managing large-scale systems, we have thought deeply about how to apply security and privacy techniques to protect sensitive data. Core security concepts still apply: you need to discover and classify your data, and then obfuscate/mask it to reduce risk of exposure. However, today’s landscape is different. You have new use-cases like managing cloud storage buckets, not to mention things like data warehouses, data lakes, and complex analytical pipelines. Then, to make things extra challenging, there are applications where you are interacting with customers in real-time, increasing the risk of inadvertently collecting or exposing sensitive data.
Securing sensitive data and reducing the risk of over exposure is critical across these workloads. Traditional data loss prevention (DLP) tools that are focused only on endpoints or your SaaS-based productivity applications may not be enough. You also need visibility into the data that you are processing in production workloads, so you know exactly which workloads process user data and personally identifiable information (PII). With this visibility, you can make “content-aware” policy decisions to adhere to your privacy and security posture. Then, once you understand the data that you are working with, you need automated tools to help you redact or obfuscate sensitive data, so that you can provide safer service to your users as well as perform analytics.
Cloud DLP was designed to help you gain visibility into sensitive data and reduce risk in your production workloads. Below are a few examples of how we see customers using
Cloud DLP to gain visibility into their data and build workloads that prioritize privacy.
Large scale discovery and classification
If you’re managing a large data warehouse or data lake, it can be challenging to understand if and where there’s sensitive data. Imagine you have Cloud Storage buckets storing data across your company, including small and large (>GB sized) objects, and you need to create an audit report of where sensitive data exists.
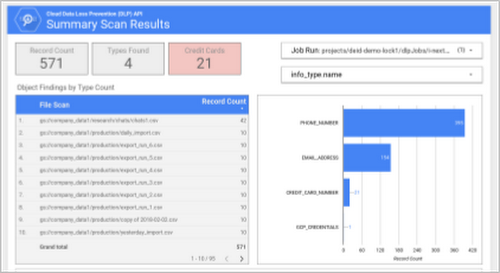
Cloud DLP writes its findings directly to BigQuery, letting you explore, analyze, and visualize results directly or using the tools of your choice. For example, you can use Data Studio to create a custom audit report.
Securing cloud buckets
Cloud-based object storage can support massive workloads for large numbers of users or that are distributed around the globe. However, as we have seen in headlines over the past year, improperly configured storage buckets can also lead to exposure of your sensitive data. Imagine a scenario where you have public buckets serving content to customers, and someone uploads sensitive customer data into it. That data is now exposed to anyone with access to that bucket!
On Google Cloud, you can help prevent this kind of unintended exposure with a simple, three-stage process:
Use Identity & Access Management (IAM) to restrict
writeaccess to your public bucket so that employees or users can’t write directly to it.Set up a second bucket to which authorized users or service accounts are allowed to write their data.
Use Cloud DLP to scan and classify data in this second bucket. Then, if it passes your policy checks, move it to the public bucket.
This is a great example of putting in automated checks and balances without disrupting your workflow. For more information about how to automate classifying data uploaded to Cloud Storage, here is a tutorial and reference example.
Cloud DLP is a powerful tool to protect the security and privacy of your data. Stay tuned for the next installation in our “Taking charge of your data” series, where we’ll tackle how to incorporate data obfuscation and minimization techniques into your workflows—leaving less potential for human error.

