How to solve customer challenges when security patching Google Kubernetes Engine
Stan Trepetin
Technical Program Manager
Editor's note: This blog post has been adapted from the April 2023 Threat Horizons Report.
Cloud customers are increasingly running their compute workloads in Kubernetes clusters due to the availability, flexibility, and security they provide. Just like other IT assets, these clusters need to be routinely patched to keep their features current and to install security and bug fixes. Reviewing data collected between 2021 and 2022, Google has found that Google Kubernetes Engine (GKE) customers sometimes delay security patching their clusters. The primary cause of these delays is the concern that patching might inadvertently interrupt production operations. While delaying security patches might seem like the most effective solution in the short-term, doing so can increase the risk that an organization faces.
GKE customers can maintain workload availability and keep security patches current by:
configuring and orchestrating Kubernetes environments to speed up patching while maintaining business continuity;
specifying appropriate maintenance windows and maintenance exclusions windows to align with business needs; and,
using notification and scanning services to find vulnerabilities and plan for security patch installations.
GKE customers are concerned with tradeoffs between Kubernetes cluster availability and security patching. Customer workloads need to run during important production time frames such as Black Friday or New Year’s Eve. Security patching might impact availability, as systems can be down during patching – and there might even be outages after patching. For example, patches could inadvertently introduce new bugs across the IT environment.
Conversations we had with customers revealed the following main reasons why they prolonged or delayed security patching, as they balanced security and availability. (Suggested solutions to these concerns are described at the bottom of this post.)
Customers of applications that need to maintain “state” — such as via sessions or similar mechanisms — worried that unexpected patching would break the states. This could happen when recycling a node-hosted load balancer or web server containing a pinned session, which could undermine their applications’ execution. (This issue can be addressed by a Pod Disruption Budget and Termination Grace Policy, as explained at the bottom of the post).
Similar to the “stateful” customers, were other clients executing batch and AI/ML applications. They worried that patching might interrupt work like ML “training”, as not-yet-completed workloads could be restarted during patching. Although for such clients, non-interruption, rather than patching per se, was the aim. If the cluster nodes (virtual machines making up Kubernetes clusters where customers execute workloads) can finish without interruption, they could be terminated without patching. These workloads were, in effect, ‘one time’ jobs. (Patching concerns for such workloads can be mitigated via maintenance exclusion configurations, provided later in this post).
Customers delayed security upgrades because they worried that such upgrades might also bring unanticipated API changes, which might undermine their applications’ functionality. Yet, APIs do not change when security upgrades occur within a minor version (the version of the Kubernetes cluster’s overall operating environment); and updates can be configured to only upgrade the current minor version, and not upgrade to a newer minor version (that is, the scope of the updates can be controlled). Customers were not always aware of this configuration option, however.
For customers with very large node fleets, patching could take more time, and possibly maintain a weak security posture longer. The default GKE node patching method is surge upgrade, with a default node-update parameter, maxSurge, of 1. Customers can modify this parameter to make patching go faster, but the default value creates a longer patching process, as only one node can be updated at a time. The environment will, consequently, run with vulnerable nodes longer.
Prolonging or delaying security patching has its own challenges, however. Clusters running on older GKE patch releases had 2X, 3X, or more open CVEs compared to those on newer patch releases. Effectively, unmanaged risk accumulates over time.
We looked at a year’s worth of node patching data, ending in October 2022. Customers were running several GKE minor versions and various Container-Optimized Operating Systems (COS, the actual OS image deployed within the minor version) in this timeframe. The relative number of High and Moderate COS CVEs in one of the earlier GKE minor versions, 1.20, as well as one of the later minor versions, 1.22, in this timeframe, is illustrated in Figure 1 and Figure 2.
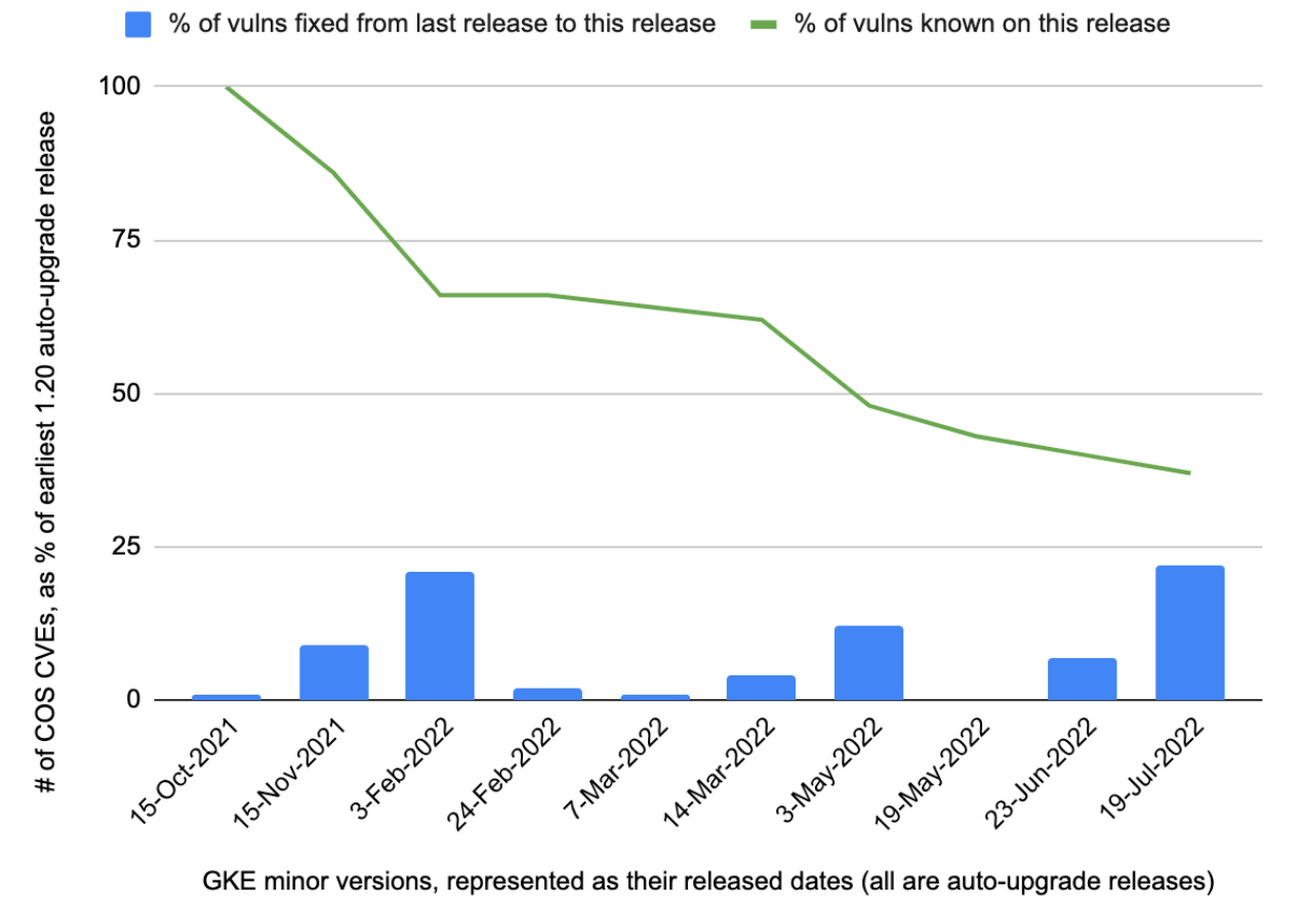
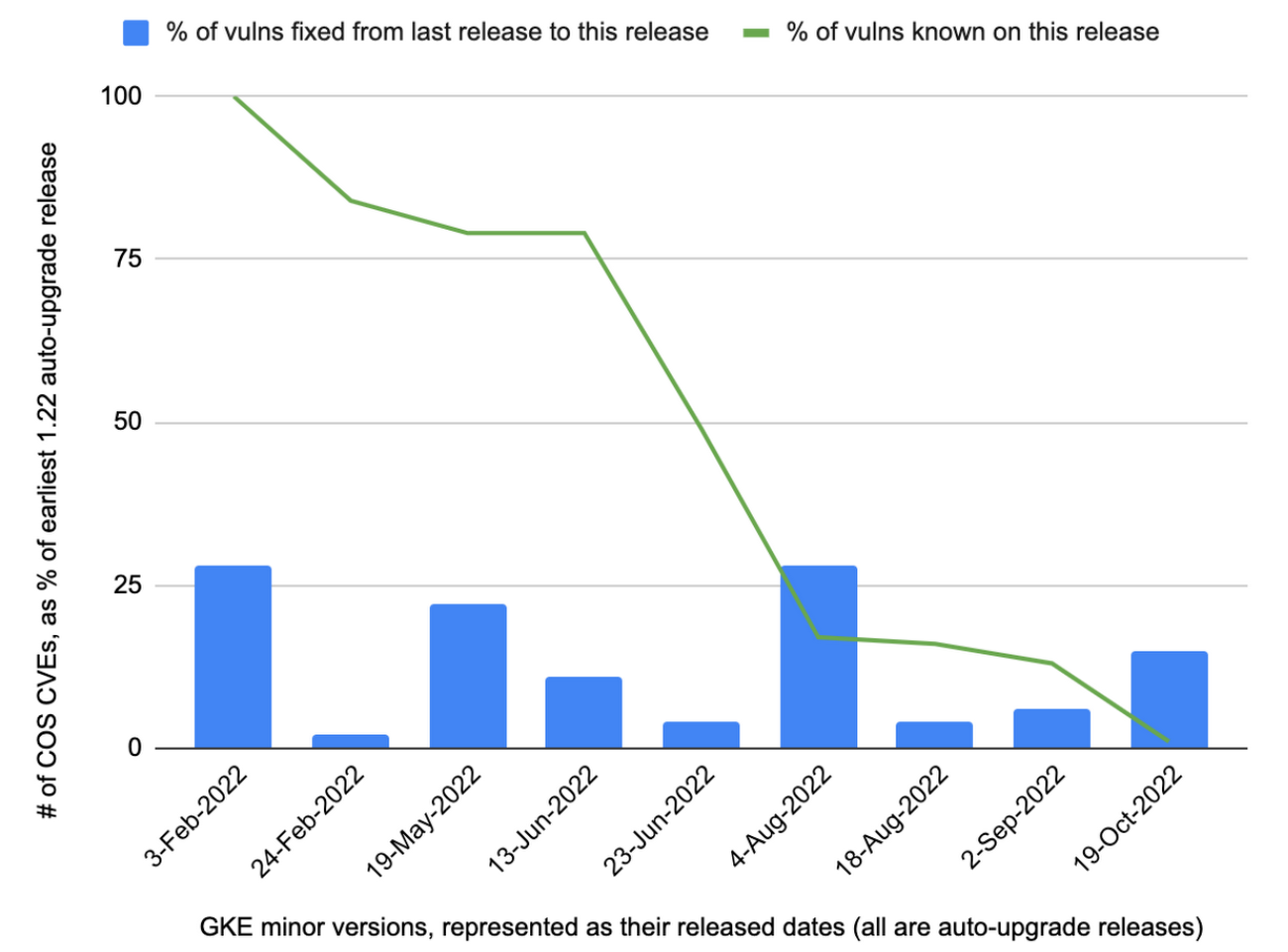
The graphs show the patch lifecycle over time when using the “auto-upgrade” process, wherein Google automatically deploys patches in customer clusters within the same minor version at a regular cadence. The graphs show relative CVE percentages, i.e. the CVE count for a given auto-upgrade release, as compared to the CVE count for the first auto-upgrade release in the same minor version. As seen, the percentages generally decreased by 2X, 3X, or higher multiples, as clusters were being patched towards more current releases–as less CVEs were found in more current releases.
The following suggestions explain how customers can achieve availability and security patching in a more unified manner.
Solutions for balancing availability and security patching within GKE
Ensure that your clusters are in a release channel, which are Google-managed rollout policies allowing customers to choose the appropriate, relevant upgrade path for them. The channels automatically maintain customer clusters with new Kubernetes features and security and bug fixes. Of the three available release channels (Rapid, Regular, and Stable), Google Cloud recommends the Regular channel for a useful balance between security patch speed and availability. Still, security fixes are automatically published and patched in all three channels in due time.
Use regularly-occurring maintenance windows (specifying when environment upgrades are allowed), of proper duration, to ensure that nodes are patched when production processing permits. (However, short maintenance windows may be insufficient for large clusters, to fully complete patching in one cycle).
Use maintenance exclusion windows (MEW, specifying when environment upgrades are prohibited), to prevent patching from occurring during non-interruptible work periods. The timeframe for the exclusion, as well as its scope, can be specified. For example, a given minor version can continue to be updated, but migrating to a newer minor version – where, for instance, API functionality could change — can be excluded via a MEW.
The default node pool patching method is surge upgrade, as before. If using surge upgrade for very large clusters, consider increasing the maxSurge parameter beyond the default of 1. More than one node will be patched simultaneously, allowing for faster node fleet patching. If the deployed application(s) can also withstand some disruption during patching, increase the maxUnavailable parameter beyond its default 0. This might take down some production nodes — which by definition, should be tolerable — but will also finish the patching faster.
For stateful and similar workloads, set a Pod Disruption Budget (PDB). Pods are subtasks of a workload running within a node. Setting an appropriate PDB will ensure that for session-based and similar applications, the “minimum available” pods specified in the Budget will continue executing–while the patching is occurring. The Termination Grace Period can be increased if necessary (the default is 30 seconds) to ensure that as pods get shutdown during the patching process a sufficient amount of time is allotted for a graceful shutdown of workload tasks, if needed.
For additional production workload availability, customers should set up regional clusters rather than zonal clusters when creating their GKE environment. While a zonal cluster is being patched, access to the Kubernetes API is not available, which can impact production applications dependent upon it. Regional clusters don’t have this limitation, however.
The zonal cluster has only one control plane, the software infrastructure managing the Kubernetes cluster. While the zonal cluster is patched, the Kubernetes API cannot be used, as the API’s manager (the control plane) is unavailable. Regional clusters, in contrast, have control plane redundancy of three – and when they are patched, one control plane will be unavailable, while the others will be available. The available control planes will, among other functionality, keep the Kubernetes API operating.Use the security posture dashboard (SPD), currently in Public Preview, to find various security concerns with your clusters. Through the SPD, vulnerability scans looking for workload misconfigurations, or CVEs in the OS images used on nodes, can be initiated–and the results provided in a dashboard. Vulnerability scan results are also placed into Cloud Logging for additional reportability.
Utilize various notification services for additional security awareness regarding your clusters. View deprecation insights and recommendations to determine which APIs or other GKE features will be changing in the future, including suggestions how to mitigate the changes within your environment. Subscribe to the GKE pub/sub to receive security bulletins and patch release information tailored to the specific cluster versions you’re running. Both notifications can be used for planning and change management purposes.


