Build a secure data warehouse with the new security blueprint
Andy Chang
Senior Product Manager, Google Cloud Security
Erlander Lo
Senior Cloud Security Product Manager
As Google Cloud continues our efforts to be the industry’s most trusted cloud, we’re taking an active stake to help customers achieve better security for their cloud data warehouses. With our belief in shared fate driving us to make it easier to build strong security into deployments, we provide security best practices and opinionated guidance for customers in the form of security blueprints. Today, we’re excited to share a new addition to our portfolio of blueprints with the publication of our Secure Data Warehouse Blueprint guide and deployable Terraform.
Many enterprises take advantage of cloud capabilities to analyze their sensitive business data. However, customers have told us that their teams invest a great deal of time in protecting the sensitive data in cloud-based data warehouses. To help accelerate your data warehouse deployment and enable security controls, we've designed the secure data warehouse blueprint.
What is the secure data warehouse blueprint?
The secure data warehouse blueprint provides security best practices to help protect your data and accelerate your adoption of Google Cloud's data, machine learning (ML), and artificial intelligence (AI) solutions. The blueprint’s architecture can help you not only cover your data’s life cycle, but also incorporate a governance and security posture as seen in the following diagram.
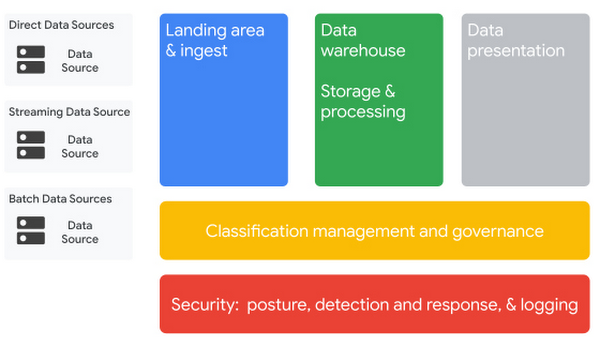
The blueprint consists of multiple components:
The landing area ingests batch or streaming data.
The data warehouse component handles storage and de-identification of data, which can later be re-identified through a separate process.
The classification and data governance component manages your encryption keys, de-identification template, and data classification taxonomy.
The security posture component aids in detection, monitoring, and response.
The blueprint can create these components for you by showing you how to deploy and configure the appropriate cloud services in your environment. For the data presentation component, which is outside of the scope of the blueprint, use your team’s chosen business intelligence tools. Make sure the tools used, such as Looker, have appropriate access to the data warehouse.
To get started, you can discuss recommended security controls with your team by using the blueprint as a framework. You can then adapt and customize the blueprint to your enterprise’s requirements for your most sensitive data.
Let’s explore some benefits this blueprint can provide for your organization: accelerate business analysis securely and provide strong baseline security controls for your data warehouse.
Accelerate business analysis
Limited security experience or knowledge of best practices can inhibit your data warehouse transformation plans. The blueprint helps address this need in different ways by providing you with code techniques, best practices on data governance, and example patterns to achieve your security goals.
This blueprint provides infrastructure as code (IaC) techniques such as codifying your infrastructure and declaring your environment that allow your teams to analyze the controls and compare them against your enterprise requirements for creating, deploying, and operating your data warehouse. IaC techniques can also help you simplify the regulatory and compliance reviews that your enterprise performs. The blueprint allows for flexibility – you can start a new initiative or configure it to deploy into your existing environment. For instance, you can choose to use the blueprint’s existing network and logging modules. Alternatively, you can keep your existing networking and logging configuration and compare them against the blueprint’s recommendations to further enhance your environment with best practices.
The blueprint also provides guidance and a set of Google best practices on data governance. It helps you implement Data Catalog policy tags with BigQuery column-level access controls. You can enforce separation-of-duty principles. The blueprint defines multiple personas and adds least-privileged IAM roles, so you can manage user identity permissions through groups.
Sometimes, seeing an example pattern and adapting it can help teams accelerate their use of new services. Your team can focus on customization to achieve your enterprise goals instead of working through setup details of unfamiliar services or concepts. For instance, this blueprint has examples on how to separate build concerns with your Dataflow flex template from your infrastructure. The example shows how you can:
Create a separate re-identification process and environment.
Apply data protection and governance controls such as data loss prevention (DLP) with Cloud Data Loss Prevention (DLP) and customer-managed encryption keys (CMEK) with Cloud HSM.
Generate sample synthetic data that you can send through the system to observe how confidential data flows through the environment.
We’ve provided this guidance to help with faster reviews for the completeness and security of your data warehouse.
Protect data with layered security controls
Using this blueprint, you can demonstrate to your security, risk, and compliance teams which security controls are implemented in the environment. The blueprint builds an architecture that can minimize the infrastructure you need to manage and uses many built-in security controls. The following diagram shows not only the services used in the architecture, but also how the services work together to help protect your data. VPC Service Controls creates perimeters to group services by functional concerns. Perimeter bridges are defined to allow communication and to monitor between the perimeters.
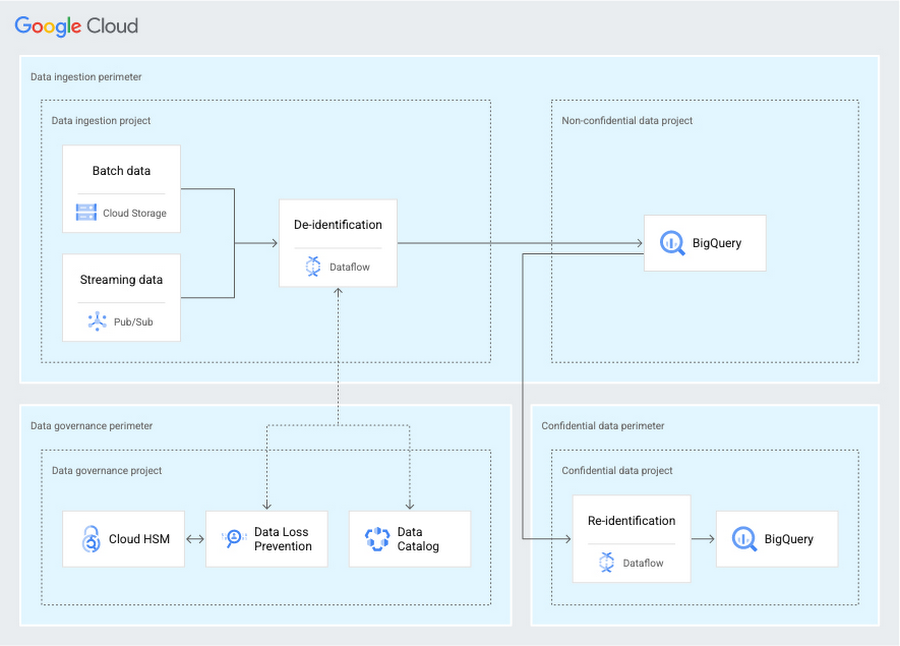
The data governance perimeter controls your encryption keys that are stored in Cloud HSM, de-identification templates that are used by Cloud DLP, and data classification taxonomy that is defined in Data Catalog. This perimeter also serves as the central location for audit logging and monitoring.
The data ingestion perimeter uses Dataflow to de-identify your data based on your de-identification template and store the data in BigQuery.
The confidential data perimeter covers the case when sensitive data might need to be re-identified. A separate Dataflow pipeline is created to send the data to an isolated BigQuery dataset in a different project.
Additional layers such as IAM, organization policies, and networking are described in the Secure Data Warehouse Blueprint guide.
Let’s explore how these controls relate to three topics that often arise in security discussions: minimizing data exfiltration, configuring data warehouse security controls, and facilitating compliance.
Minimize data exfiltration
The blueprint enables you to deploy multiple VPC Service Controls perimeters and corresponding bridges so that you can monitor and define where data can flow. These perimeters can constrain data to your specified projects and services. Access to the perimeter is augmented with context information from the Access Context Manager policy.
The blueprint helps you create an environment with boundaries where data can flow and what data can be seen. You can customize the organization policies or use the provided organization policies that help create guardrails, such as preventing the use of external IPs. Your data in transit remains on trusted networks by using private networks and private connectivity to services. You can use the provided Cloud DLP configuration to de-identify your data with additional security protection in case the data is unintentionally accessed. The data is obfuscated through Cloud DLP’s cryptographic transformation method.
Limiting who can access your most sensitive data is an important consideration. The blueprint uses fine-grained IAM access policies to ensure least privilege and minimize lateral movement. These IAM policies are limited in scope and bound as close to the resource as possible rather than at the project level. For instance, an IAM access policy is bound to a key that is used to protect BigQuery. Also, service accounts, rather than user identities, are defined to perform operations on your data. These service accounts are granted predefined roles with least privilege in mind. The IAM bindings for these privileged accounts are transparently defined in the blueprint, so you can evaluate the IAM policies and monitor them. You can allow the correct users to see the re-identified data by adding additional access grants using column-level access controls with BigQuery.
Configure pervasive data warehouse controls
The data warehouse security controls can cover various aspects of your data warehouse across multiple resources rather than focusing on a single service. Various security controls are packaged into different modules. For instance, if you want to protect your trust perimeter, create Cloud DLP de-identification templates, use BigQuery controls, or build Dataflow pipelines for ingestion or re-identification, you can explore those particular modules. You can adjust those modules to match your requirements.
Data encryption controls can be enabled on each service to protect your data with customer-managed encryption keys. Multiple keys are created, which define separate cryptographic boundaries for specific purposes. For instance, one of the keys may be used for services that handle ingestion, while a separate key may be used for protecting the data within BigQuery. These keys have an automatic rotation policy and are stored in Cloud HSM.
The blueprint helps you build data governance by applying Data Catalog policy tags. It can create a taxonomy that you define. The following diagram shows a hierarchy where the highest level of access is tagged as “Confidential.”
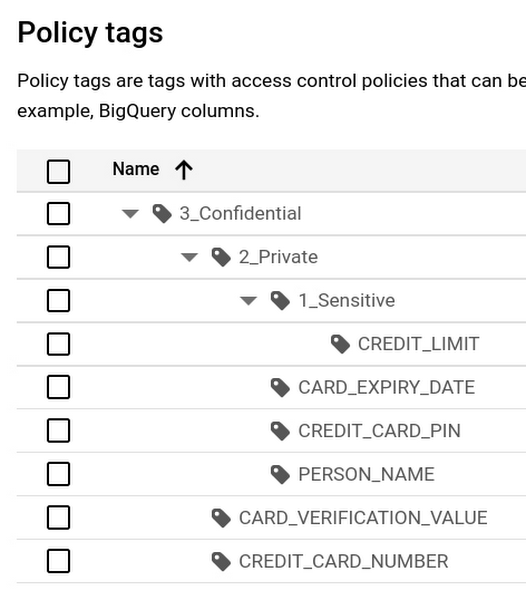
These policy tags are applied to your BigQuery table schema and enable column-level access controls.
Beyond the IAM policies that limit who can access your data, additional controls like Dataflow’s streaming engine and organization policies are in place to help minimize things you need to manage. Multiple organization policies are configured such as preventing service account creation to make it obvious when a change occurs. These policies are applied at the project level to give you flexibility and more granularity of these controls.
Facilitate compliance needs
The blueprint helps address data minimization requirements with Cloud DLP’s cryptographic transformation methods. We have also recently added automatic DLP for BigQuery to provide the build-in capability to help detect unexpected types of data in your environment. This new integrated DLP capability also gives you visibility into your environment to help with assessments. Data encryption is handled in the deployed services using keys that you manage in Cloud HSM, which is built with clusters of FIPS 140-2 Level 3 certified HSMs.
Access controls to your data are configured with service accounts built around the principle of least privilege access to data. If a user identity needs to read confidential data, that identity must be explicitly granted access to both the dataset and column, and audit logs capture these IAM updates. Policies defined in Access Context Manager add extra context information to enforce more granular access. The Access Context Manager policy is configured with context information such as IP and user identity that you can further enhance.
You can use additional Google best practices from the Security Foundations blueprint. That blueprint uses built-in security controls such as Security Command Center, Cloud Logging, and Cloud Monitoring. The security foundation blueprint’s logging and monitoring section describes how Security Command Center helps you with your threat detection needs. Security Health Analytics is a built-in service of Security Command Center that monitors each project to minimize misconfigurations. Audit logs are centrally configured with CMEK to help with your access monitoring. In addition, Access Transparency can be configured for additional insight.
We also know that it's helpful to get outside validation and perspective. Our Google Cybersecurity Action Team and a third-party security team have reviewed the security controls and posture established by this blueprint. Learn more about the reviews by reading the additional security considerations topic in the guide. These external reviews help you know you are applying best practices and strong controls to help protect your most sensitive data.
Explore best practices
To learn more about these best practices, read the Secure Data Warehouse Blueprint guide and get the deployable Terraform along with our guided tutorial. Listen to our security podcast titled “Rebuilding vs Forklifting and how to secure a data warehouses in the cloud.” Our ever-expanding portfolio of blueprints is available on our Google Cloud security best practices center. Build security into your Google Cloud deployments from the start and help make your data warehouse safer with Google.


