Introducing easier de-identification of Cloud Storage data

Scott Ellis
Senior Product Manager
Jordanna Chord
Senior Staff Software Engineer
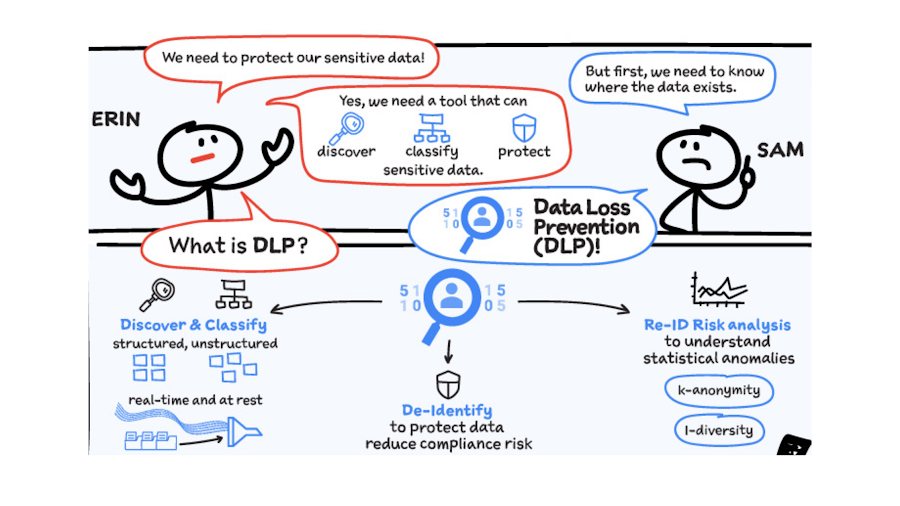
De-identification of Cloud Storage just got easier
Many organizations require effective processes and techniques for removing or obfuscating certain sensitive information in the data they store. An important tool to achieve this goal is de-identification. Defined by NIST as a technique that “removes identifying information from a dataset so that individual data cannot be linked with specific individuals. De-identification can reduce the privacy risk associated with collecting, processing, archiving, distributing or publishing information.”
Always striving to make data security easier, today we are happy to announce the availability of a de-identification action for our Cloud Storage inspection jobs. Now, you can de-identify Cloud Storage objects, folders, and buckets without needing to run your own pipeline or custom code. Additionally, we have enhanced our transforms by adding a new dictionary replacement method that can help you achieve stronger privacy protection – especially with unstructured data you might store like customer support chat logs.
The “De-identify findings” Action
The “de-identify findings” action for Cloud DLP inspection jobs is a fully managed feature that creates a de-identified copy of the data objects that are inspected. This means that you can inspect a Cloud Storage bucket for sensitive data like Personal Identifiable Information (PII) and then create a redacted copy of these objects all with a few clicks in the Console UI. No need to write custom code or manage complex pipelines and since it’s fully managed, it will auto-scale for you without you needing to manage quota.
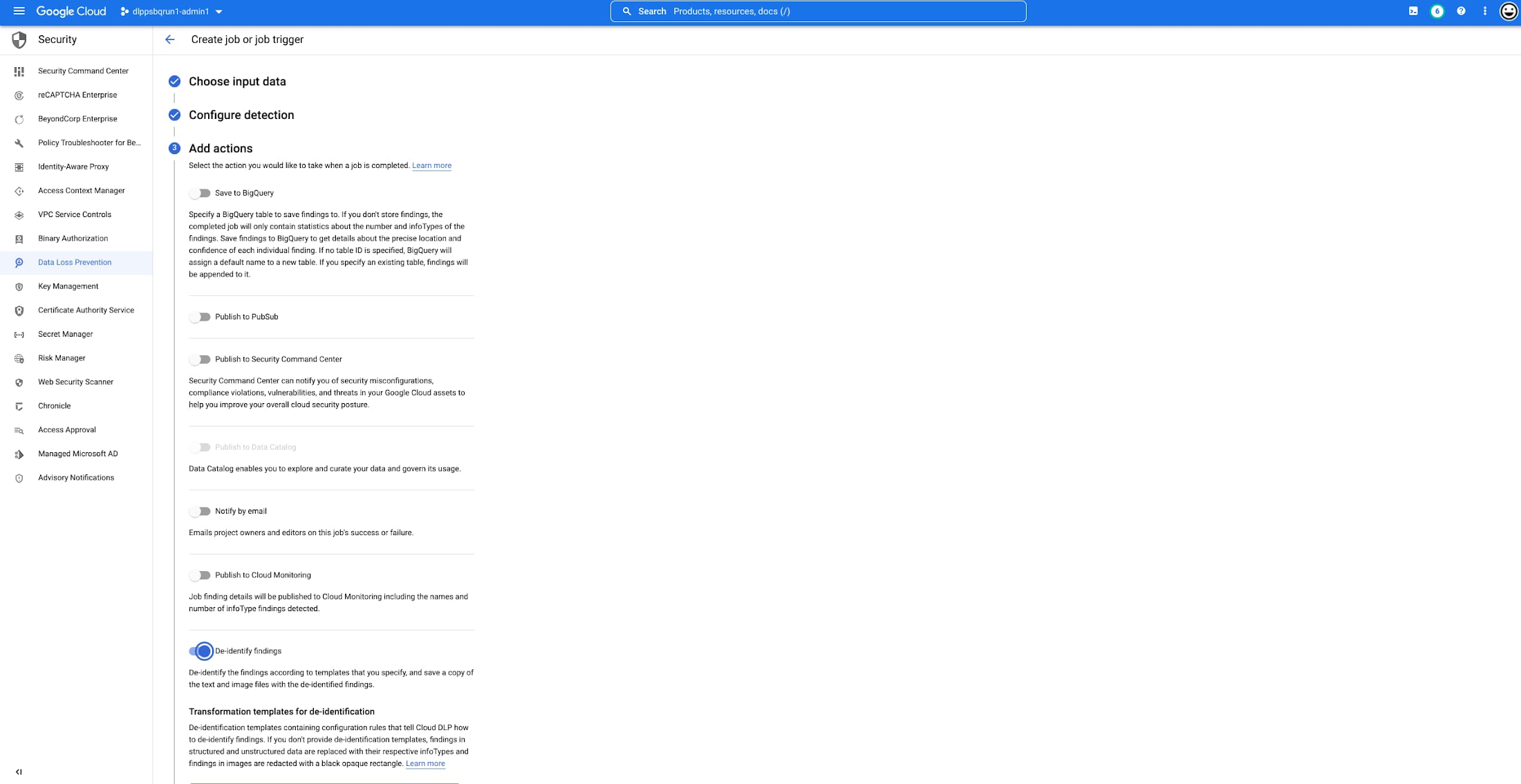
This new action supports the following data types:
Text files
Comma- or tab-separated values
Images (see regional limitations)
Once enabled, the DLP job will perform an inspection of the data and produce a de-identified copy of all supported files into the output bucket or folder.
You can also use the new de-identify action on Job Triggers to automatically de-identify new content as it appears on a recurring schedule. This is useful for creating a workflow with a safe drop zone for incoming files that need to be de-identified before being made accessible.
What can automatic De-identification do?
Cloud DLP provides a set of transformation techniques to de-identify sensitive data while attempting to make the data still useful for your business. These techniques include:
Redaction: Deletes all or part of a detected sensitive value.
Replacement: Replaces a detected sensitive value with a specified surrogate value.
Masking: Replaces a number of characters of a sensitive value with a specified surrogate character, such as a hash (#) or asterisk (*).
Crypto-based tokenization: Encrypts the original sensitive data value using a cryptographic key. Cloud DLP supports several types of tokenization, including transformations that can be reversed, or "re-identified."
Bucketing: "Generalizes" a sensitive value by replacing it with a range of values. (For example, replacing a specific age with an age range, or temperatures with ranges corresponding to "Hot," "Medium," and "Cold.")
Date shifting: Shifts sensitive date values by a random amount of time.
Time extraction: Extracts or preserves specified portions of date and time values.
New Dictionary Replace method
When a sensitive data element is found, dictionary replacement replaces it with a randomly selected value from a list of words that you provide. This transformation method is especially useful if you want the redacted output to have more realistic surrogate values.
Consider the following example: You collect customer support chat logs as part of providing service to your customers. These support chat logs contain various types of Personal Identifiable Information (PII) including people’s names and email addresses. Cloud DLP can find and de-identify the sensitive elements with static replacements such as “[REDACTED]” to help prevent someone from seeing this sensitive data.
With the new dictionary replacement method you can instead replace these findings with a randomly selected value from a dictionary. This dictionary replacement provides two key benefits over static replacement:
The resulting output can look more realistic
Because the output looks more realistic, it can help conceal any residual names (a privacy de-identification technique sometimes referred to as “hiding in plain sight”)
An example of this:
Input:
[Agent] Hi, my name is Jason, can I have your name?
[Customer] My name is Valeria
[Agent] In case we need to contact you, what is your email address?
[Customer] My email is v.racer@example.org
[Agent] Thank you. How can I help you?
De-identified Output:
[Agent] Hi, my name is Gavaia, can I have your name?
[Customer] My name is Bijal
[Agent] In case we need to contact you, what is your email address?
[Customer] My email is happy.elephant44@example.org
[Agent] Thank you. How can I help you?
As you can see in the output, the names and email addresses have been replaced with a random value that both protects the original sensitive information but also makes the output look more realistic. This can make the data more useful and help “hide” any residual PII.
Next Steps:
To learn more about De-Identification check out our Technical Docs, try De-identification of Storage in the Cloud Console and Watch a recent Google I/O talk on De-identification of data.