Alert Scoring at Machine Scale with a Human Touch
Mandiant
Written by: Mandiant Data Science
Digital risk protection is a key component of any security-minded organization’s modern intelligence stack. The Mandiant Advantage Digital Threat Monitoring (DTM) module provides customers with the ability to gain visibility into threats that target their assets on social media, the deep and dark web, paste sites, and other online channels. DTM is composed of advanced natural language processing pipelines that use machine learning to surface high-fidelity alerts based on the detection of meaningful entities and security-related topics. But even after winnowing down Mandiant’s vast collections funnel from millions of documents ingested per day to only a small subset of the most relevant alerts, customers may still find themselves spending precious time deciding which resulting alerts are most pertinent.
Highlights
- We have developed a new alert scoring feature for DTM that combines the benefits of hands-on analyst interaction with a complementary layer of automation based on machine learning.
- DTM alert scoring is governed by two components: Confidence, which scores how certain Mandiant is in the given alert actually being malicious, and Severity, which scores what the potential impact of the threat is.
- After applying Confidence and Severity scoring, on average only 3.1% of all alerts and <0.1% of all ingested documents get bucketed into the
highseverity category, resulting in an enormous time and cost savings that customers can now achieve by prioritizing their triage.
Augmenting Human Expertise with Machine Learning
The experience of Mandiant’s leading threat researchers, reverse engineers, intelligence analysts and incident responders is unparalleled, having defended organizations of all sizes at the front lines of cyber conflict since 2004. Expert analysts understand the semantic complexities of alerts, identify abstract concepts not directly observable in the data, and quickly ascertain whether an alert should be investigated within the next day or within the next hour. But since human review does not scale to DTM’s data volumes, we have developed a new alert scoring feature for DTM that combines the benefits of hands-on analyst interaction with a complementary layer of automation based on machine learning.
A single score cannot tell the whole story about a threat, and each customer has unique preferences and requirements when it comes to alert prioritization. That is why we developed the Mandiant scoring framework, presented at this year’s mWISE Conference, to carefully weave human and machine competencies. It allows us to scale Mandiant expertise to millions of DTM alerts per day, standardize the process for all customers, free up analyst time for other tasks, and adapt to new sources over time.
Case Study: Scoring Digital Threat Monitoring Alerts
DTM alert scoring was launched and is generally available for customers today; it is currently governed by two components: Confidence and Severity.
The Confidence score of a DTM alert captures the certainty in the quality of the alert’s malicious content given existing evidence. DTM alert Confidence is modeled using a form of semi-supervised learning called weak supervision, which closely mirrors how an analyst might ask questions to gather and weigh relevant alert information before applying their final judgment (Figure 1).

Figure 1: Automating the analyst’s process for determining the confidence of a DTM alert. Like an analyst, our machine learning model factors in a large number of weak signals (navy rectangles) that are codified into simplified labeling functions. The output of these functions (gray rectangles) are weighed together with their learned accuracies of these labeling functions (gold, silver, and bronze medals) to obtain a final model that outputs a confidence score.
We noticed that analysts assessing alerts do not simply take the answer from a single question to determine each one’s overall maliciousness. Instead, they use answers gathered from a suite of probing questions, each with its own expectation and fraction of certainty, to reach a conclusion. We can model each question programmatically as a labeling function and each answer as its associated result for a given alert. Analysts may have additional prior knowledge about how influential the answer to one of their questions could be in determining the impact of the overall confidence verdict, and we can model this expectation using a prior probability.
Using a combination of these initial priors together with statistics obtained from executing our set of labeling functions over millions of accumulated alerts, we can train a weakly supervised model that adjusts its weights according to (1) how often labeling functions return a malicious or benign result, and (2) how often they agree or disagree with one another. The learned model can then be used to return a weighted vote, or scaled value between 0 and 100, on each newly generated DTM alert. Confidence scores can be thresholded and calibrated using the following criteria: less than 40 indicates benign, between 40 and 60 is indeterminate, between 60 and 80 is suspicious, and greater than 80 indicates malicious.
One of the most appealing aspects of weak learning is that it naturally marries this data-driven analysis with direct input from analysts. They can flexibly define interpretable labeling functions and essentially “program” a machine learning model, without any of the technical know-how. On the output side, analysts can interact further to validate scores, identify weaknesses in noisy labeling functions, and refine them with new detection logic. In some cases, analysts’ prior expectations may not be borne out in the data, creating additional iteration possibilities and providing an opportunity for experts to update their own preconceived notions of alert maliciousness.
The Severity score of a DTM alert categorizes the impact of malicious activities possible for high-confidence alerts. Severity is assessed using additional context, enrichments, and expert judgment downstream of Confidence. In the scoring framework’s division of labor, the Confidence score helps initially remove any obvious noise, and any available context is then used by the Severity scoring model to further iteratively divide alerts into either high, medium, or low categories (Figure 2).
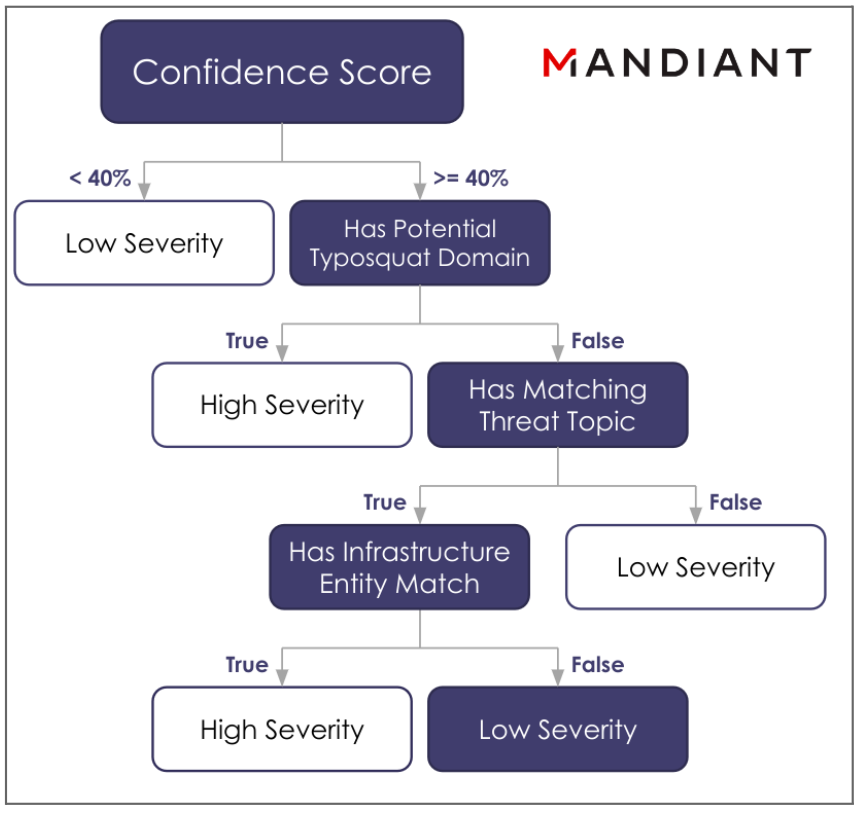
Figure 2: Automating the analyst’s process for determining the severity of a DTM alert. In this simplified alert severity scoring decision tree, an alert traverses from the root until it is associated with a low Severity category at one of its leaves (traced from top to bottom by following the navy rectangles).
Like the Confidence model, the Severity model relies on input from expert analysts, who possess a deep and up-to-date understanding of the impact of different threat types. Analysts create expressions and rules for calculating the severity of an alert and then submit them to an internal engine that in turn constructs a decision tree. The rules engine evaluates this decision tree to compute severity statistics over high volumes of alert data, allowing analysts to subsequently query the statistics, zoom in on specific alerts, and iterate on fine-tuning the rules. In this way, the benefits of human and machine are combined just like they are in the Confidence score—analysts can perform longitudinal analysis of threat trends on large-scale observations and telemetry—all without requiring knowledge of the technical details under the hood.
Creating Customer-Efficient Outcomes for DTM
In this blog post, we have introduced an alert scoring framework that leverages both human and machine capabilities to scale intelligence and customize its application. Alert scoring demonstrates the importance of using these complementary approaches, and weaves human and machine together to lead to better outcomes than either one alone. It is available in the Mandiant Advantage DTM module, where users are now able to rank alerts in their Alert List dashboard and have each alert modal display a Severity score (Figure 3 and Figure 4).
Since deploying our alert scoring models into production, on average we observe 35.4% of alerts categorized as low Confidence with the remaining higher Confidence alerts further categorized into 62.3% low, 32.8% medium and 4.9% high Severity. When all is said and done, only 3.1% of all alerts and <0.1% of all ingested documents get bucketed into the high Severity category. This results in an enormous time and cost savings that customers can now achieve by prioritizing their triage.

Figure 3: An example alert list view for a DTM user displaying a new color-coded Severity column.

Figure 4: Users are able to view alert Severity by clicking into individual alerts to investigate more specific details.


