Using Apache Spark with TensorFlow on Google Cloud Platform
Bill Prin
Developer Programs Engineer
Neeraj Kashyap
Developer Programs Engineer
Apache Spark and TensorFlow are both open-source projects that have made significant impact in the world of enterprise software in recent years. TensorFlow provides a foundational framework for running distributed numerical computations, such as deep learning algorithms, while Spark is a general Hadoop-like, large-scale data processing framework that's also a popular choice for more traditional machine learning algorithms using MLlib.
Google Cloud Platform offers managed services for both Apache Spark, called Cloud Dataproc, and TensorFlow, called Cloud ML Engine. Both of these services deliver the power of their respective open-source frameworks in a managed environment, letting you focus on the data science while we worry about the operations.
Intuitively, there is some overlap — Spark provides a framework for big data computations, and the type of datasets that power TensorFlow algorithms tends to be large. This leads to a possible intersection between the two frameworks: using Spark to preprocess the input to TensorFlow.
On our GitHub repo for Cloud Dataproc, we have new TensorFlow-Spark samples which demonstrate two of these use cases. The first is generating TFRecords from CSVs. The second is using Spark to preprocess the data and generate artifacts for the Tensorflow graph. Many of the concepts in the samples are borrowed from TF Transform.
One example is using Spark to generate TFRecords, the recommended TensorFlow format, using the Spark TensorFlow Connector from the input CSVs. TFRecords are a standard input format for training data examples. Another technique is to use Spark to generate artifacts used by the TensorFlow graph. For example, one common preprocessing technique is to replace missing numerical feature values with the mean of the observed values for that feature. Since deep learning jobs often operate on large datasets, Spark is a natural choice to run this preprocessing.
As a developer or data scientist, you will need to decide how much preprocessing to do in Spark rather than in the TensorFlow graph itself. For example, given those numerical values, we can either use Spark to replace the missing values as a preprocessing step, or just have the Tensorflow graph feature column set the value as a default value for the feature. To better understand the difference, first, take a look at the architecture for when we our TF model accepts TSV (tab-separated values) input, only using Spark to create artifacts, not the training data:
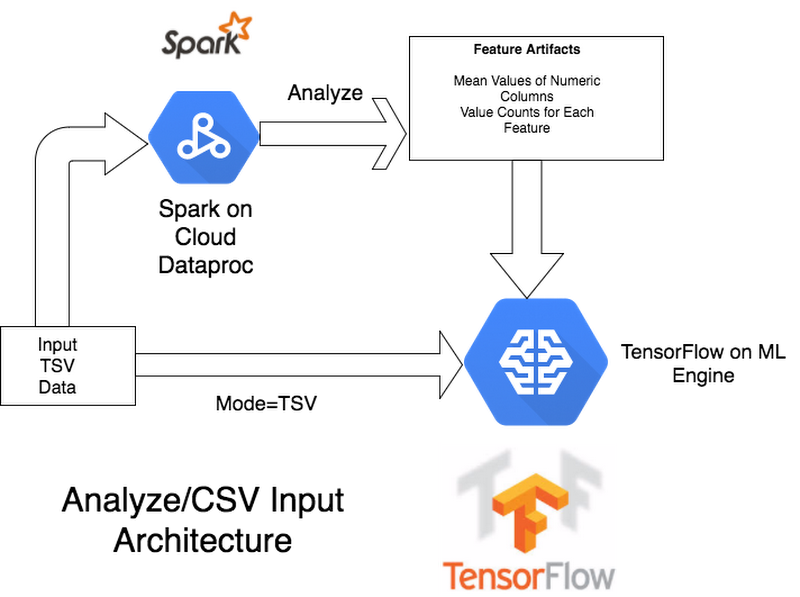
Now compare it to the architecture in which Spark also replaces the missing values and does all the preprocessing, and hands the TensorFlow model complete TFRecords as training data.
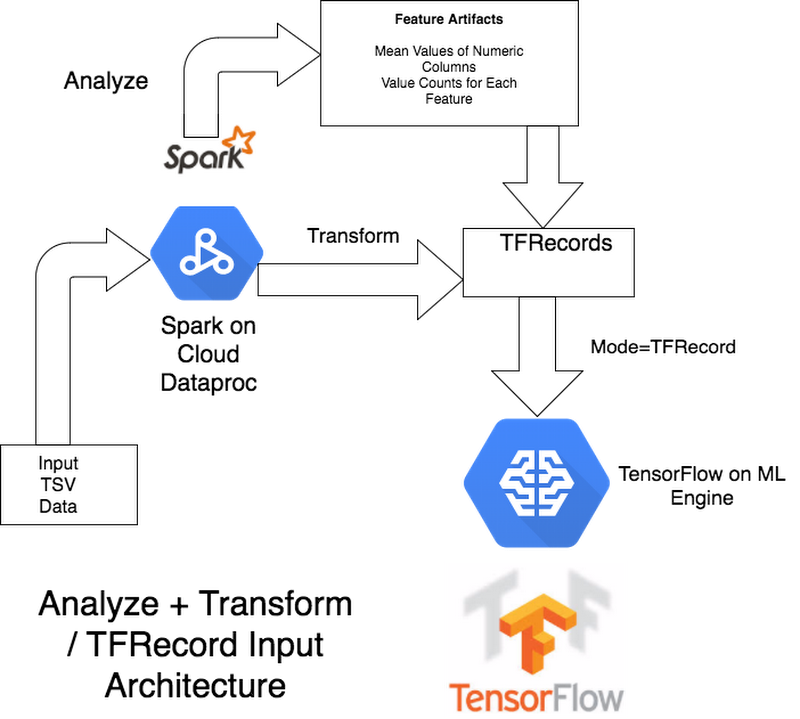
An advantage of doing more of the preprocessing in Spark is that it will only happen once, whereas in the TensorFlow graph you may end up doing duplicate transformations on every training epoch. An advantage of doing the preprocessing in TensorFlow is that you can serve predictions without having to incorporate Spark into the pipeline.
We look forward to continue exploring the intersection of Spark and TensorFlow, and hope to learn more from the greater community's exploration of the topic as well. In the meantime, we encourage you to check out our GitHub sample.
Find me on Twitter @waprin_io.


