Uptime checks for availability
Aron Eidelman
Developer Relations Engineer, Security Advocate
Amol Devgan
Senior Product Manager
A reliable system and end-user experience is critical to an organization's success. Any downtime or degradation of user experience across an organization’s applications can impair its ability to create value for its stakeholders.
Cloud Monitoring’s uptime check capability enables you to monitor your application's availability and performance. The primary purpose of an uptime check is to track resource availability and latency over regular intervals. It's analogous to a “pulse check” for a system and can proactively detect availability and latency issues with an application, potentially reducing the length and impact of an outage.
Uptime Checks can also be an incredibly useful and fast way to get started with monitoring availability with zero instrumentation.
In this post, we’ll consider the benefits and identify best practices of alerting on uptime checks as a way to support availability.
Availability and Alerting
We’ll begin by stating some assumptions and defining terms about availability and alerting:
What is Availability?
Availability defines whether a system is able to fulfill its intended function at a point in time. Availability needs to be determined based on a specific event (e.g., “a user purchases an item,” “an application makes queries to a database.”) Availability can be identified at multiple levels, e.g. the availability of an entire application, a regional workload, a particular feature, or an individual compute resource.
How does an Uptime Check relate to Availability?
An uptime check is a periodic test of whether a service or resource is reachable. Uptime monitoring mimics an end-user and verifies resource availability on an ongoing basis, even during times when traffic is low due to time and seasonality, e.g. night time or holidays. It's a great starting point, and should be complemented with traffic monitoring to get a complete picture of availability. Likewise, if a system has external dependencies, uptime checks can indicate availability issues with dependencies in the absence of access to other metrics.
For Google Cloud, Cloud Monitoring makes it easy to quickly create Uptime Checks for both public and private resources with just a few minutes of configuration.
How should we Alert on Availability?
Ideally the events that we alert on should have business implications, such as user satisfaction or successful item purchases. We should alert on availability incidents that impact our organization’s goals. We need to minimize noise and false positives by focusing on the relevance and intended outcome of each alert.
Avoiding noise can improve response times, and overall trust in the urgency of a problem. It becomes more difficult for operators to detect and respond to issues if they are inundated with alerts that do not actually need their attention. The stress, burnout, and counterproductive context switching of unactionable or irrelevant alerts makes it worthwhile to think critically about what to alert on, and why.
In Google Cloud Monitoring, alerts and their notification policies can trigger an automated flow, or it can be used to notify people. We should only notify people (either through tickets or paging, depending on the urgency) when their manual intervention is required. In Google Cloud Monitoring, notification channels such as Pub/Sub and Webhooks can split off into other tools for ticketing and paging.
The more automated a system is, the higher the abstraction level we can focus on for alerting, e.g. we alert on failures in applications and their features, not on failures in infrastructure. As discussed in Why Focus on Symptoms, Not Causes and in the Google SRE Handbook, our goal is to progressively move to a state where we alert from the user’s point of view–and little to nothing else.
When is an Uptime Check Useful to Detect Availability Issues?
A public uptime check is a stand-in for one of us manually accessing our own resources to see if they work. If we use a highly available architecture and design for individual resources to fail safely, we can focus our uptime-check based alerting strategy on the resources most relevant to our users, for example:
Website availability
External load balancer is available and resolving requests
Geographic availability
In addition to these primary use cases, uptime can also be used to check on resources that are critical, but may see infrequent use. Suppose a critical endpoint only receives requests a few times a day, but it needs to be up during those times. In this instance, alerting on an uptime check could give us a warning if the service goes down before a user or external system makes an attempt to do so. We might choose to keep the uptime check in place until the service starts to get enough traffic for us to switch our focus to alerting on other metrics.
There are some exceptions to alerting on user-facing symptoms that we highlighted in Why Focus on Symptoms, Not Causes. In some situations, we may have critical resources that cannot (yet) fail safely, either because we still haven’t moved to a more reliable system or because we have external dependencies that give us limited visibility. In each of these cases, we can use uptime checks to preempt issues. In general, though, we should maintain as much focus on alerting on symptoms as possible to avoid noise, and public uptime checks by their nature focus on symptoms.
Best Practices for Alerting with Uptime Checks
When creating uptime based alerts, we should keep the following best practices in mind:
Frequency: An uptime check only occurs in intervals, meaning that if there is an outage between intervals, it may go unnoticed. It is possible that a resource could go down immediately after an uptime check has passed, and the failure wouldn’t be evident until the next interval. The correct interval may vary considerably depending on the use case, so ask in advance, “How much time do we need to respond, and how long can we tolerate an outage?”. Uptime checks can run at a maximum frequency of once every 60 seconds. (See the resources section at the bottom for how to set the check frequency.)
Proper Configuration: Uptime checks require no instrumentation and serve as a stand-in for manually testing whether a service is up–but they may be inaccurate if they are not properly configured or if the resources they are monitoring are experiencing intermittent problems. For example, if a firewall’s configuration blocks the uptime-check server, it may seem unavailable, whereas normal users with other IP addresses have no issues accessing the resource. These types of issues will be apparent when you first create the check or whenever there is a configuration change, and can be mitigated with testing.
Noise Minimization: Even with good planning, a sufficiently large system will create noise. It is worth noting that alerts can be snoozed and refined. As a team iteratively improves reliability, alerts may transition from notifying people to starting an automated remediation. Always question–is this alert actually relevant to my organization’s ability to create value? And if so, what would I expect someone to do about it? If there is no answer to either question, it may be creating more confusion and distraction to keep the alert active.
Uptime checks can be a valuable tool for ensuring the uptime of your resources in Google Cloud, and a great way to get started with zero instrumentation. The flexibility in how a team uses alerts helps avoid situations in which alerting starts to pose its own operational problems. By carefully planning and implementing your uptime checks, you can minimize the risk of these problems and maximize the benefits of using uptime checks.
Get Started Today
To create an uptime-check based alert, navigate to Google Cloud Monitoring - Uptime in the Google Cloud Console by clicking here.
To modify the frequency of uptime checks, use the following option in the console:
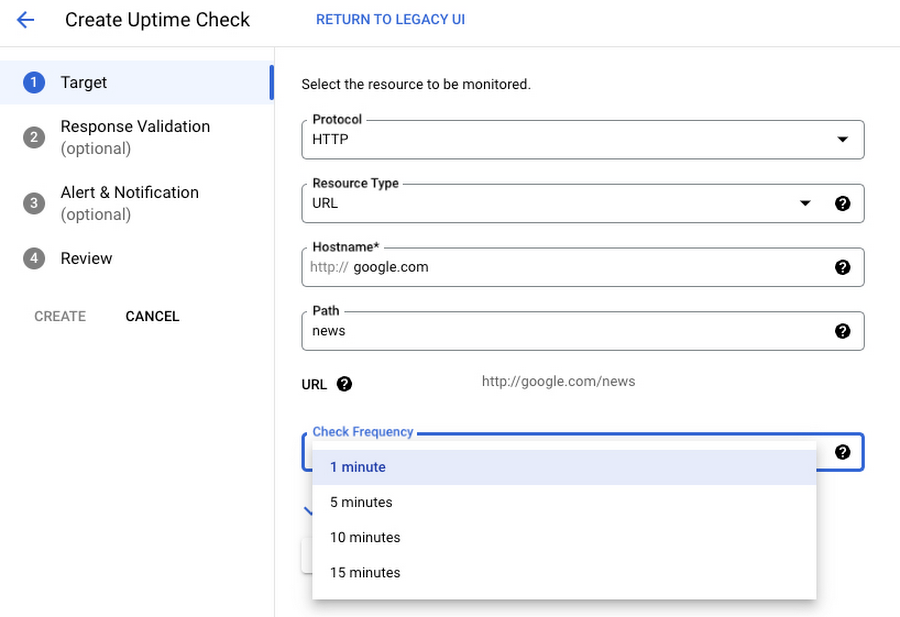
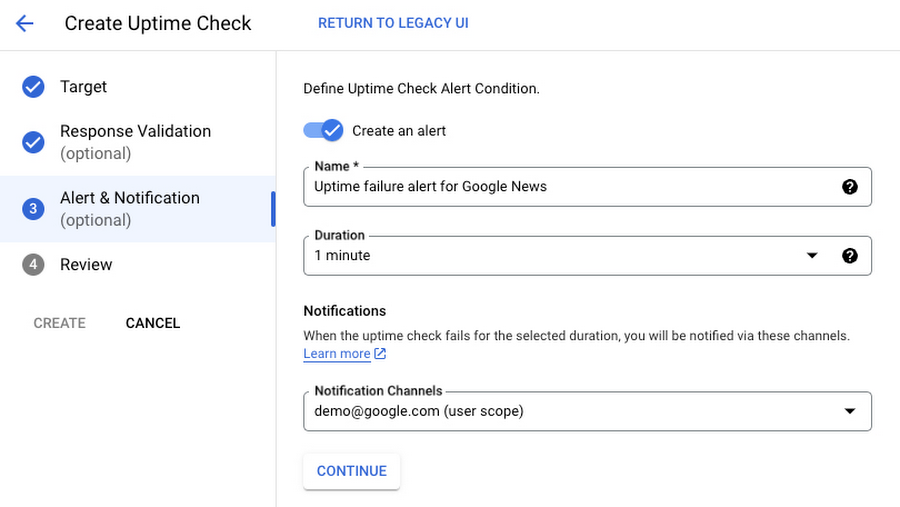
To define alert conditions for an uptime check, use the “Alert & Notification” tab:
Learn more about how to set up uptime checks and alerts here:
If you have any questions about setting up alerts, or how to blend uptime checks with metric and log-based alerting, please join us at the next Reliability Engineering Discussion.



