Uncomplicating the complex: How Spanner simplifies microservices-based architectures
Szabolcs Rozsnyai
Senior Staff Solutions Architect
Karthi Thyagarajan
Senior Staff Solutions Architect
In the realm of modern application design, developers have a range of choices available to them for crafting architectures that are not only simple, but also scalable, performant and resilient. Container platforms like Kubernetes (k8s) offer users the ability to seamlessly adjust node and pod specifications, so that services can scale. This scalability does not come at the expense of elasticity, and also ensures consistent performance for service consumers. So it’s no surprise that Kubernetes has become the de facto standard for building distributed and resilient systems in medium-to-large organizations.
Unfortunately, the level of maturity and standardization in the Kubernetes space available to system designers in the application layer doesn’t usually extend to the database layer that powers these services. And it goes without saying that the database layer also needs to be elastic, scalable, highly available, and resilient.
Further, the challenges are amplified when these services:
-
Are required to manage (transactional) states or
-
Orchestrate distributed processes across multiple (micro-) services.
Traditional relational database management software (RDBMS) brings with it side effects that are not aligned with a microservices way of thinking, and entails fairly significant trade-offs. In the sections below, we dive deeper into the scalability, availability and operational challenges faced by application designers specifically within the database tier. We then conclude with a description of how Spanner can help you build microservices-based systems without the often unspoken “impedance mismatch” between the application layer and the database layer.
We look at this problem from a scalability and availability perspective, specifically in the context of databases that cater to OLTP workloads. We explore the intricacies involved in accommodating highly variable workloads, shedding light on the complexities associated with managing higher demands through the utilization of both replicas and sharding techniques.
Wanted: scalability and availability
When it comes to scaling a traditional relational database, you have two choices (leaving aside caching strategies):
-
Scale up: To scale a database vertically, you typically augment its resources by adding more CPU power, increasing memory, or adding faster disks. However, these scale-up procedures usually incur downtime, affecting the availability of dependent services.
-
Scale out: Although vertically scaling up databases can be effective initially, it eventually encounters limitations. The alternative is to scale out database traffic, by introducing additional read replicas, employing sharding techniques, or even a combination of both. These methods come with their own trade-offs and introduce complexities, which lead to operational overhead.
In terms of availability, databases require maintenance, resulting in the need to coordinate regular periods of downtime. Relational databases can also be prone to hardware defects, network partitions, or subject to data center outages that bring a host of DR scenario challenges that you need to address and plan for.
Examples of planned downtime:
-
OS or database engine upgrades or patches
-
Schema changes - Most database engines require downtime for the duration of a schema change
Examples of unplanned downtime
-
Zonal or regional outages
-
Network partitions
Most “mature” practices for handling traditional RDBMSs run counter to modern application design principles and can significantly impact the availability and performance of services. Depending on the nature of the business, this can have consequences for revenue streams, compliance with regulations, or adversely impact customer satisfaction.
Let’s go over some of the key challenges associated with RDBMSs.
Challenges associated with read-replicas
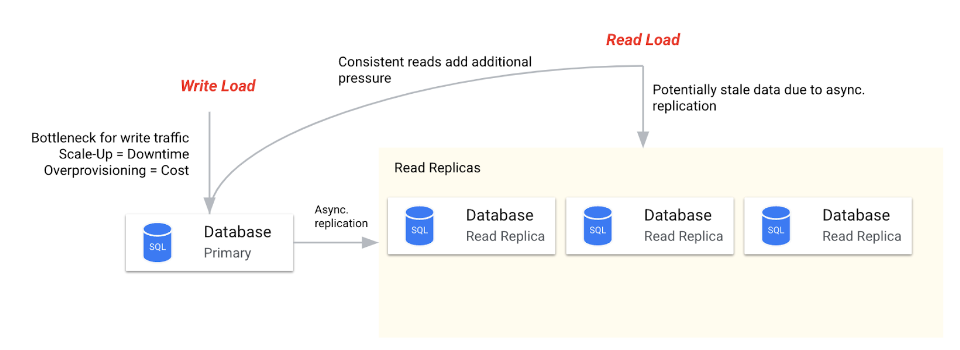
Database read replicas are a suitable tool for scaling out read operations and mitigating planned downtime, so that reads are at least available to the application layer.
In order to reduce load on the primary database instance, replicas can be created to distribute read load across multiple machines and thus handle more read requests concurrently.
Replication between the primary and secondary replicas is usually done asynchronously. This means there can be a lag between when data is written to the primary database and when it is replicated to the read replicas. This can result in read operations getting slightly outdated (stale) data if they are directed to the replicas. This also dictates that guaranteed consistent queries need to be directed to primary instances. Synchronous replication is rarely an option, in particular, not in geo-distributed topologies, as it is complex, and comes with a range of issues such as:
-
Limiting the scalability of the system, as every write operation must wait for confirmation from the replica, causing performance bottlenecks and increasing latency
-
Introducing a single point of failure — if the replica becomes unavailable or experiences issues, it can impact the availability of the primary database as well
And lastly, write throughput can become bottlenecked due to the limit on how much write traffic a single database can handle without performance degradation. Scaling writes still requires vertical scaling (more powerful hardware) or sharding (splitting data across multiple databases), which can lead to downtime, additional costs, and limits imposed by non-linearly escalating operational toil. Now let’s look at sharding challenges in a bit more detail.
Sharding challenges
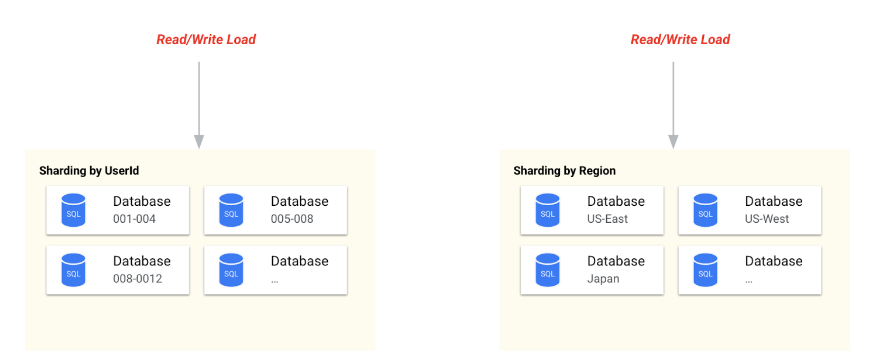
Sharding is a powerful tool for database scalability. When implemented correctly, it can enable applications to handle a much larger volume of read and write transactions. However, sharding does not come without its challenges and brings its own set of complexities that need careful navigation.
There are multiple ways to shard databases. For instance,
-
they can be split by user id ranges,
-
regions or
-
channels (e.g. web, mobile) etc..
As shown in the above example, sharding by user id or region can lead to significant performance improvements, as smaller data ranges are hosted by individual databases and the traffic can be spread across these databases.
Key considerations:
-
Deciding on the “right” kind of sharding: One of the primary challenges of sharding is the initial setup. Deciding on a sharding key, whether it be user ID, region, or another attribute, requires a deep understanding of your data access patterns. A poorly chosen sharding key can result in uneven data distribution, known as "shard imbalance," which can significantly dull the performance benefits of sharding.
-
Data integrity is another significant concern. When data is spread across multiple shards, maintaining foreign-key relationships becomes difficult. Transactions that span multiple shards become complex and can result in increased latency and decreased integrity.
-
Operational complexity: Sharding introduces operational complexity. Managing multiple databases requires a more sophisticated approach to maintenance, backups, and monitoring. Each shard may need to be backed up separately, and restoring a sharded database to a consistent state can be challenging.
-
Re-sharding: As an application grows, the chosen sharding scheme might need to change. This process involves redistributing the data across a new set of shards, which can be time-consuming and risky, often requiring significant downtime or degraded performance during the transition.
-
Increased development complexity: Application logic can become more complex because developers must account for the distribution of data. This could mean additional logic for routing queries to the correct shard, handling partial failures, and ensuring that transactions that need to operate across shards maintain consistency.
Exploding complexity and operations
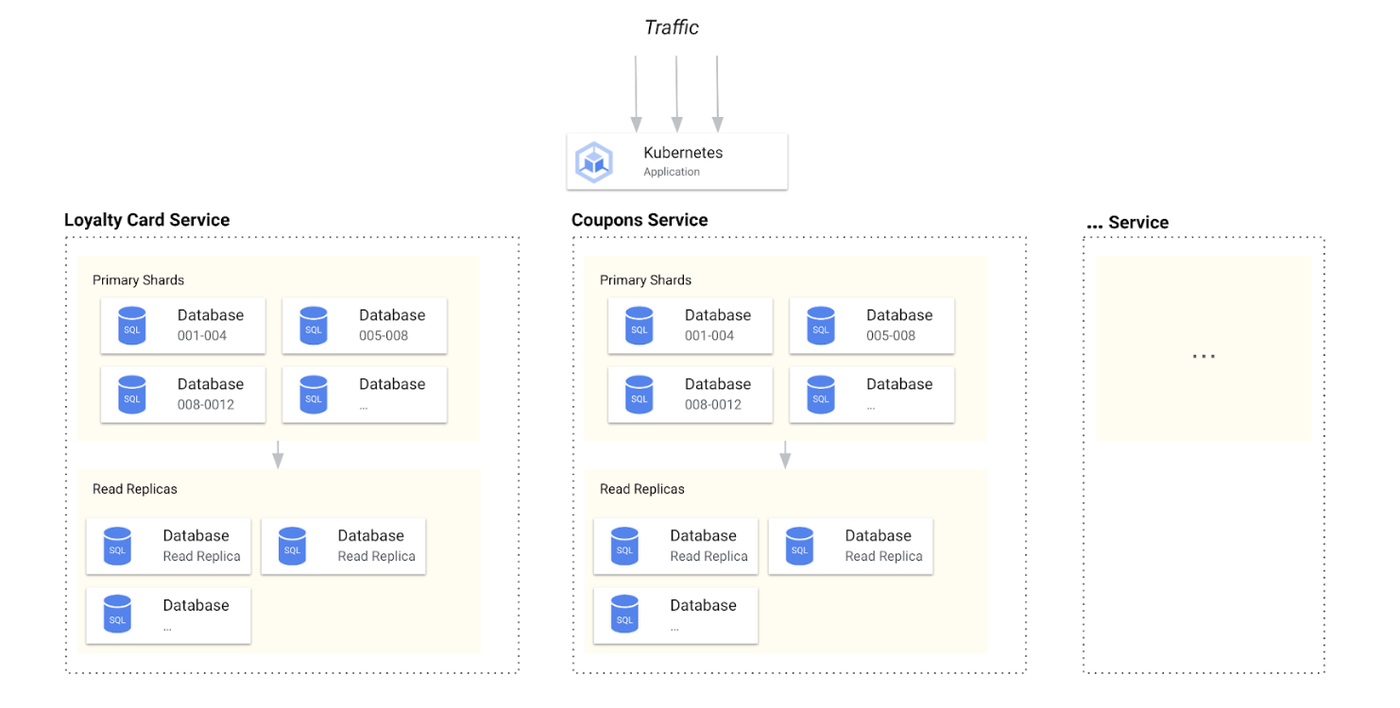
Over time, database complexity can grow along with increased traffic, adding further toil to operations. For large systems, a combination of sharding along with attached scale-out read replicas might be required to help ensure cost-effective scalability and performance.
This combined dual-strategy approach, while effective in handling increasing traffic, significantly ramps up the complexity of the system's architecture. The above illustration captures the need to add scalability and availability to a transactional relational database powering a service. It doesn’t even include full details on DR (e.g. backups), or geo-redundancy, nor does it cater to zero-to-low RPO/RTO requirements.
Furthermore, the dual-strategy approach described above can:
-
negatively impact the ease of service maintenance
-
increase operational demands, and
-
elevate the risk associated with the resolution of incidents
Doesn’t NoSQL address this?
NoSQL databases began to emerge in the early 2000s as a response to traditional RDBMSs’ above-mentioned limitations. In the new era of big data and web-scale applications, NoSQL databases were designed to overcome the challenges of scalability, performance, flexibility and availability that were imposed by the growing volume of semi-structured data.
However, the key tradeoff they made was to drop sound relational models, SQL, and support for ACID-compliant transactions. However, many prominent system architects have questioned the wisdom of abandoning these well-worn relational concepts for OLTP workloads, as they are essential features that still power mission-critical applications. As such, there’s been a recent trend to (re)introduce relational database features into NoSQL databases, such as ACID transactions in MongoDB and Cassandra Query Language (CQL) in Cassandra.
Enter Spanner
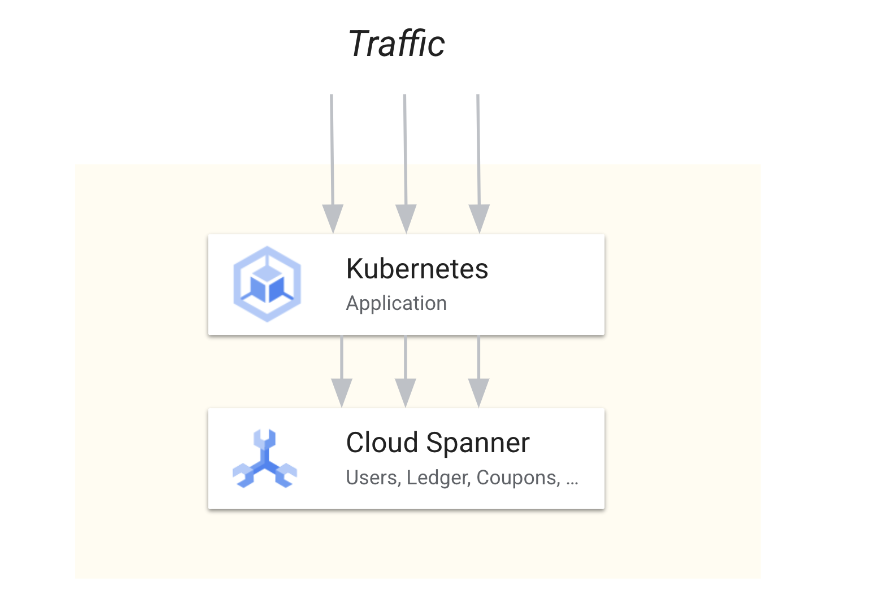
Spanner eliminates much of this complexity and helps facilitate a simple and easy-to-maintain architecture without most of the above-mentioned compromises. It combines relational concepts and features (SQL, ACID transactions) with seamless horizontal scalability, providing geo-redundancy with up to 99.999% availability that you want when designing a microservices-based application.
We want to emphasize that we’re not arguing that Spanner is only a good fit for microservices. All the things that make Spanner a great fit for microservices also make it great for monolithic applications.
To summarize, a microservices architecture built on Spanner allows software architects to design systems where both the application and database provide:
-
“Scale insurance” for future growth scenarios
-
An easy way to handle traffic spikes
-
Cost efficiency through Spanner’s elastic and instant compute provisioning
-
Up to 99.999% availability with geo-redundancy
-
No downtime windows (for maintenance or other upgrades)
-
Enterprise-grade security such as encryption at rest and in-transit
-
Features to cater for transactional workloads
-
Increases in developer productivity (e.g. SQL)
You can learn more about what makes Spanner unique and how it’s being used today. Or try it yourself for free for 90-days or for as little as $65 USD/month for a production-ready instance that grows with your business without downtime or disruptive re-architecture.

