New Spanner geo-partitioning improves performance and lowers costs
Nitin Sagar
Product Manager
In today's interconnected world, your applications and users are geographically dispersed. If your database isn't designed to handle this geographic distribution, you are sacrificing performance and user experience. But now, with Spanner geo-partitioning, you don’t have to.
Spanner is Google’s fully managed, globally distributed database with high throughput and virtually unlimited scale. With features such as automatic sharding, zero planned downtime, and strong consistency, Spanner powers demanding, global workloads that are both relational and non-relational.
And with the addition of geo-partitioning, you retain the manageability of your single, global database while improving latency for users who are distributed around the globe.
What is geo-partitioning and why use it?
Geo-partitioning in Spanner allows you to partition your table data at the row-level, across the globe, to serve data closer to your users. Even though the data is split into different data partitions, Spanner still maintains all your distributed data as a single cohesive table for queries and mutations.
Spanner customers across industries — gaming, e-commerce, financial services, among others — can experience the following benefits from geo-partitioning:
-
Reduced latency: Reducing the distance between users and data improves network latency, resulting in faster response times and improved user experience.
-
Optimized costs: Using geo-partitioning, you can optimize your database configuration for each location’s specific workload. For instance, if your data partition A serves 10 times the number of users compared to data partition B, you can set data partition A to 10x the number of Spanner nodes as data partition B. This helps you optimize your costs to better align with actual usage for each of your data partition locations.
Wayfair is one of the world’s largest home e-commerce companies, serving more than 20 million customers across the globe on Spanner.
"We are excited by the launch of new data placement [geo-partitioning] capability in Google Cloud Spanner, which enables Wayfair to store and scale customer data with high consistency, availability, low latency along with reducing costs and replication overhead, making Cloud Spanner an emerging choice in ecommerce" - Hiren Patel, Director of Engineering, Storefront, and Shital Mehta, Principal Engineer, Storefront, Wayfair
How does geo-partitioning work?
-
Data division: Spanner geo-partitioning lets you distribute your single Spanner table across multiple Spanner configurations that you can place close to your users. These multiple data partitions act like smaller, localized resource pools and storage, all while providing the benefits of a single centralized table.
-
Data placement: You can choose to partition some or all of your tables. For non-partitioned tables, all data is stored in a partition known as ‘default partition’. For partitioned tables, data is partitioned at the row level and you can specify placement rules that place each row into a specified partition.
-
User requests: When your application connects to Spanner, requests are forwarded to one or more partitions that contain the requested data. The previously mentioned ‘default partition’ helps with routing your data requests to the partition(s) where that data resides.
Let’s take an example: Massively Multiplayer Online game
Imagine you have a sprawling Massively Multiplayer Online (MMO) game, with players spread across North America, Europe, and Asia, and you want to geo-partition data related to your players — PlayerID, RegionID, Username, Level, CharacterClass, etc.
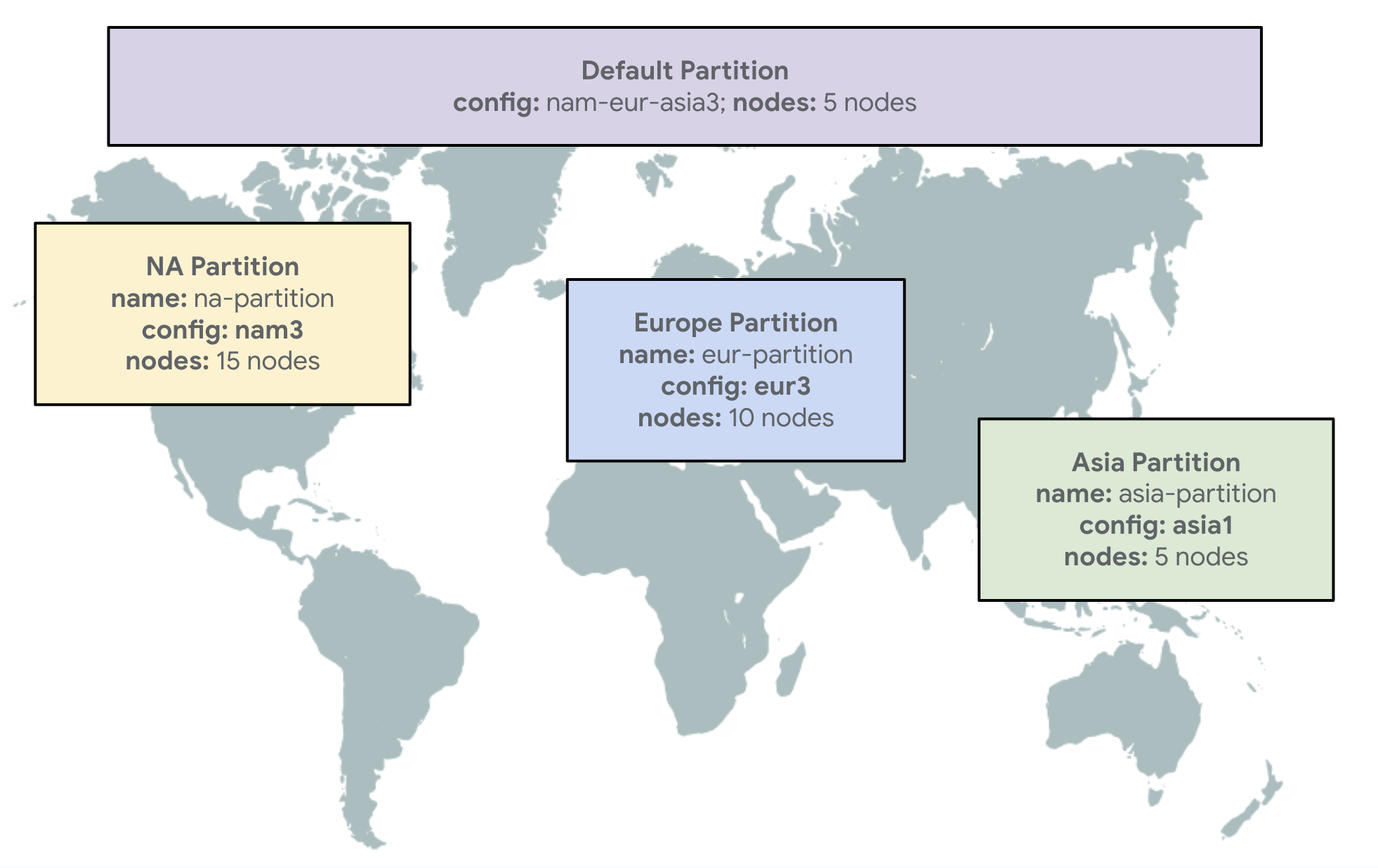
First, start by creating one Spanner instance with one default partition and three additional partitions aligning to the locations of your players:
-
Default partition (default partition): This is a required partition. You can use this to store and serve all non-player specific game data to all your players across the globe. Configure this as multi-regional configuration nam-eur-asia3 across North America, Europe, and Asia.
-
North American Partition (na-partition): This partition can be used to store player data for players in North America. You can configure this as multi-regional configuration nam3 with regions across North America.
-
Europe Partition (eur-partition): Similarly, for European players, configure this as multi-regional configuration eur3 with regions across Europe.
-
Asia Partition (asia-partition): Finally, for players in Asia, configure this as multi-regional configuration asia1 with regions across Asia.
As shown in the diagram below, your different data partitions can be configured with different numbers of nodes based on the specific requirements — reads, writes, and storage — of the data that your partition serves. This helps you optimize your costs for asymmetrical distribution of players.
Now, create the placement rules for your player data. Your primary goal for geo-partitioning here is to improve the user experience by reducing read and write latencies. You can also create a Players table that is geo-partitioned based on the placement rules.
SQL
Your inserts, updates, queries, and transactions on your Spanner geo-partitioned data work just as before. Here’s an example of an insert:
SQL
You can also update or query data across multiple partitions. Do keep in mind that your requests that touch multiple partitions may result in higher latencies.
Start using geo-partitioning today
Spanner geo-partitioning is available in preview starting today. You can create a new Spanner database, create partitions, and start playing with data within minutes. Please refer to the documentation page to learn more.

