DynamoDB to Cloud Spanner via HarbourBridge
Hengfeng Li
Software Engineer
Deep Chowdhury
Software Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
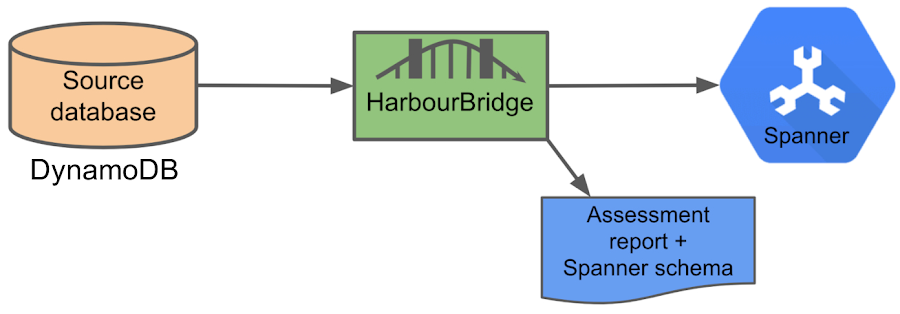
Free trialToday, we would like to announce that HarbourBridge—the open source toolkit that automates much of the migration effort to Cloud Spanner including evaluation and assessment—supports DynamoDB in addition to existing support for PostgreSQL and MySQL. This allows DynamoDB users to try out Cloud Spanner with zero-configuration. HarbourBridge helps users to quickly resolve issues during schema and data migration and let them try out Cloud Spanner as soon as possible.
Workflow
HarbourBridge can now automatically load data from multiple DynamoDB tables into Cloud Spanner. It first builds a Cloud Spanner schema by learning the data in DynamoDB. HarbourBridge then creates a Cloud Spanner database using this schema and populates the database with the data from the DynamoDB tables. In addition, it generates a detailed assessment report which includes all issues encountered and rows that failed to migrate. For DynamoDB, HarbourBridge directly connects to the source table using public APIs. The tool is designed for assessment, evaluation and migration (Best used for up to tens of GB).
How HarbourBridge converts the schema
It is challenging to migrate from a schemaless database to a relational database. We need to resolve the following issues for schema conversion in our DynamoDB support:
Schemaless - DynamoDB is a schemaless database: other than a primary index and optional secondary index, column names and types are essentially unconstrained and can vary from one row to the next. However, many customers use DynamoDB in a consistent, structured way with a fairly well defined set of columns and types. HarbourBridge’s support for DynamoDB focuses on this use-case, and we construct a Spanner schema by inspecting table data. For small tables, we inspect all rows of the table. For large tables, scanning the entire table would be extremely expensive and slow, and so we only inspect the first N rows (defined by the flag schema-sample-size with default value 100,000) from the table scan. In practice, this gives a reasonable sample of data to work with since DynamoDB scans don’t return results in order. In principle, random row selection could provide a more representative sample, but it would be much more expensive.
Number - In most cases, we map the Number type in DynamoDB to Spanner's Numeric type. However, since the range of Numeric in Cloud Spanner is smaller than the range of Number in DynamoDB, this conversion could result in out of range with potential precision loss. To address this possibility, we try to convert the sample data, and if it consistently fails, we choose the STRING type for the column.
Null - In DynamoDB, a column can have a Null data type that represents an unknown or undefined state. Also, each row defines its own schema for columns (not for primary keys). So columns can be absent in rows. We treat the above two cases the same as a Null value in Cloud Spanner. The cases that a column contains a Null value or a column is not present is an indication that this column should be nullable.
List & Map - DynamoDB supports List and Map for storing complex data structures. Their elements can be different data types e.g., a List can be ["Book", "Camera", 3.14159]. We encode list and map values as json strings in Cloud Spanner. They need to be parsed when read from Cloud Spanner.
Occasional Errors - As no schema is enforced when writing to a DynamoDB table, it can happen that a small number of data rows are incorrectly inserted, sometimes unbeknownst to the user. In Cloud Spanner, a table’s schema is strictly enforced, and we can’t write rows that differ from the table’s schema. To handle this in HarbourBridge, we define an error threshold when we are inferring the type of a column - if a type only appears in a very small proportion of rows (less than or equal 0.1%), then we treat the row as an error. Such rows are ignored when we determine the type of a column. This allows us to filter a certain amount of noise when building the Cloud Spanner schema.
Multi-type Columns - In some situations we may get a column that has an equal distribution of two data types. E.g., a column has 40% rows in String and 60% rows in Number. If we choose Number as its type, then we will drop 40% of the rows during data conversion. To handle this, we define a conflicting threshold on normalized rows (after removing Null data types and rows where the column is not present). By default, the conflicting threshold is 5% and if the percentages of two or more data types are greater than it, we would consider that the column has conflicting data types. As a safe choice, we define this column as a STRING type in Cloud Spanner.
During conversion, any rows that fail to convert to the inferred schema (at least 1 column fails conversion) or cannot be written to spanner are reported as bad rows in the assessment. Although we write the bad rows to *.dropped.txt, since the number can be large, we limit the logging to 100 rows to give the user a sample of the bad rows.
For more details about schema conversion, you can check here.Getting Started
You can directly use HarbourBridge with a Cloud Spanner instance. For convenience, you can also use Cloud Spanner Emulator - a local, in-memory emulation of Cloud Spanner for testing and evaluation purposes. We can use the emulator to try out Cloud Spanner’s functionality without any cost.
To use the emulator, you can follow the steps in Emulator instructions. You can start an emulator service via gcloud, docker, or linux binaries. Then, you need to set the SPANNER_EMULATOR_HOST environment variable, so HarbourBridge will connect to the emulator instead of talking to a real Cloud Spanner instance.
In order to get the permission to retrieve data from DynamoDB, we need to set up the AWS credentials and region by using the following environment variables:
You also can find other ways to configure them here.
By default, DynamoDB uses the environment variable AWS_REGION to resolve the endpoint url. To provide a custom endpoint, we can use the following environment variable:
Before you start running habourbridge, ensure that you run
Set the GCLOUD_PROJECT environment variable to your Google Cloud project ID:
Next, you need to have Go installed and set the GOPATH environment variable properly. Then, you can install HarbourBridge via the following command:
By default, it will install the binary at $GOPATH/bin/harbourbridge. To use the tool directly on DynamoDB (it will migrate all tables), run:
It will generate a new Cloud Spanner database, create tables by modeling schemas, and load data from source tables. In addition, you may see the following generated files:
*.report.txt: the assessment report.
*.schema.txt: Cloud Spanner schema for the source tables.
*.session.json: a persisted state of your schema conversion and it can be modified/used for future data migration.
*.dropped.txt: it contains rows that cannot be converted.
For more information about files generated by HarbourBridge, see here.
Now, if you go to the Cloud Spanner instance or the emulator, you should be able to see a new database that contains tables with loaded records from DynamoDB sources.
Optimize your schema conversion
There are more aspects that we can optimize for different scenarios:
Sample Size - If you are trying to test with a large scale database, you may find that the default size (100,000 rows) of sample data is not enough. You would like to increase the sample size. We already provide a command option “-schema-sample-size” so you can set a number to meet your needs. For example, the following command will sample 1 million records for modelling the schema:
Secondary Index - HarbourBridge provides a good starting point, but it does not support converting indexes (we only convert primary keys) at the moment. To achieve a better performance or to have a fair comparison with the source database, it would be better to add indexes. See Keys and Indexes for more information.
Interleaved Tables - This is a key concept in Cloud Spanner to improve locality and optimize table layout. Interleaved tables are tables that you declare to be a child of another table because you want the rows of the child table to be physically stored together with the associated parent row to save time to look up data that are related to each other. As a result of that, we can get a better performance of joins and also of writes.Summary
HarbourBridge is an open-source tool for Cloud Spanner evaluation and migration, which supports PostgreSQL, MySQL, and DynamoDB. It saves your time and effort by automating manual steps and creating an initial migration as quickly as possible. We also provide the options to refine and optimize the schema generated.
We would like to hear your feedback and suggestions. You can file an issue with us if you want to start a discussion or request any features. We have a roadmap for HarbourBridge. HarbourBridge is part of the Cloud Spanner Ecosystem, which is owned and maintained by a user community effort. It is not officially supported by Google as part of Cloud Spanner.

