Best practices for migrating auto-incrementing keys to Spanner
Diem Tran
Software Engineer
Justin Makeig
Senior Product Manager, Google
Editor’s note: In the previous post in this series we introduced primary key default values in Spanner. We also showed how to use the UUIDs and integer SEQUENCEs to automatically generate keys in the database. In this post we’ll show how to use these new capabilities to migrate schemas and data from other databases to Spanner, minimizing changes to downstream applications and ensuring Spanner best practices.
Spanner is a distributed relational database that is designed for the highest levels of availability and consistency at any scale. It allows users to seamlessly scale resources up and down to optimize costs based on their real-time needs, while maintaining continuous operation. Customers in gaming, retail, financial services, and many other industries rely on Spanner for their most demanding workloads.
Migrating to Spanner
Many of these workloads did not start on Spanner, though. Customers come to Spanner from different relational and non-relational databases, looking to take advantage of Spanner’s seamless scaling and fully managed experience. Spanner provides a set of tools and best practices to facilitate migrations. The Spanner Migration Tools include assessment, schema translation, and data movement for terabyte-sized databases coming from MySQL and PostgreSQL. For broader migration guidance, you can refer to the Spanner documentation.
In this post we’ll focus specifically on migrating databases that use auto-generated keys, in particular, auto-incrementing sequential integers and UUIDs.
Each of the migration strategies below addresses the key requirements:
- Ensure the fidelity and correctness of the migrated keys
- Minimize downstream application changes, such as changing types or values of the keys themselves
- Support replication scenarios where either the source or target database generates the keys and data is synchronized between them, for example, to do a live cutover between systems
- Implement Spanner best practices for performance and scalability
Migrating sequential keys
We’ll start with the most common scenario for relational workloads coming to Spanner: migrating from a single-instance database that uses sequential monotonic keys, for example AUTO_INCREMENT in MySQL, SERIAL in PostgreSQL, or the standard IDENTITY type in SQL Server or Oracle. For databases that manage writes on a single machine, a counter to provide sequential keys is simple. However, ordered keys can cause performance hotspots in a distributed system like Spanner.
At a high level, the strategy to migrate sequential keys to Spanner is:
- Define a copy of the table in Spanner using an integer primary key, just as in the source database.
- Create a sequence in Spanner and set the table’s primary key to use it for its default value.
- Load the data with its keys as-is from the source database into Spanner, for example using the Spanner Migration Tool or the lower-level Dataflow templates.
- Optionally set foreign key constraints for any dependent tables.
- Before inserting new data, configure the Spanner sequence to skip values in the range of the existing keys.
- Insert new data, as before, allowing the sequence to generate keys by default.
Let’s start by defining the table and related sequence. In Spanner you define a new SEQUENCE object and set it as the default primary value of the destination table, for example using the GoogleSQL dialect:
The required bit_reversed_positive option indicates that the numbers generated by the sequence will be greater than zero, but not ordered (see the introductory post for more information on bit-reversed sequences). Generated values are of type INT64.
As you migrate existing rows from your source database to Spanner, the rows’ keys remain unchanged. For new inserts that don’t specify a primary key, Spanner automatically calls the GET_NEXT_SEQUENCE_VALUE() function to retrieve a new number. Since these values distribute uniformly across the range [1, 263], there could be collisions with the existing keys. If this occurred your insert would fail with a “key already exists” error. To prevent this, you can configure the sequence to skip the range of values covered by the existing keys.
For example, assuming that the table singers was migrated from PostgreSQL, where its key, singer_id, was in SERIAL type:
The column values are monotonically increasing. After migration, we retrieve the maximum value of the singer_id:
Assuming the returned value is 20,000, you configure the sequence in Spanner to skip the range [1, 21000]. The extra 1,000 serves as a buffer to accommodate writes to the source database after the initial bulk migration. These values would typically be replicated later and we want to ensure they also will not conflict.
The diagram below illustrates a few migrated rows along with new rows inserted in Spanner after migration:
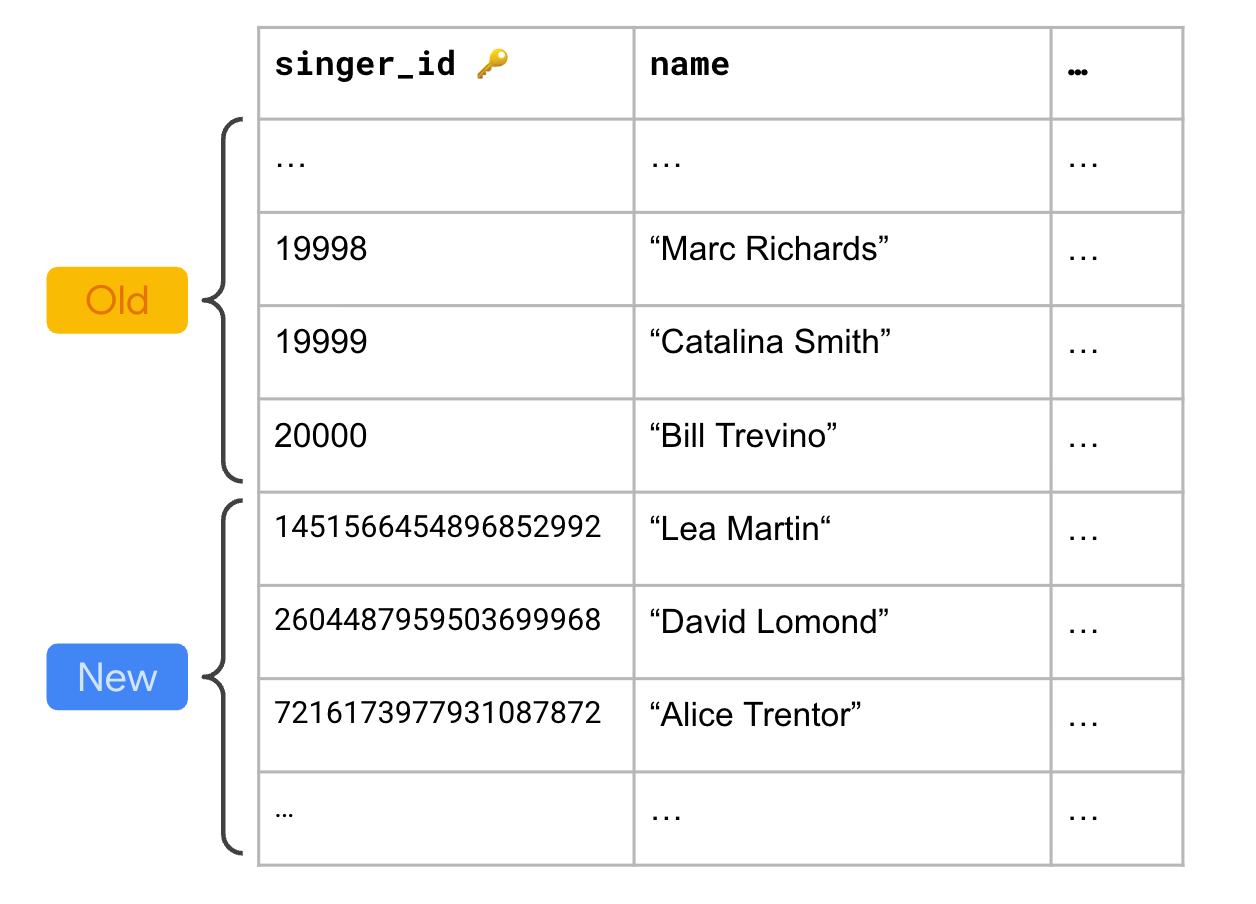
Now new keys generated in Spanner are guaranteed to not conflict with the range of keys generated in the source PostgreSQL database.
Multi-database usage
You can take this skipped range concept one step further to support scenarios where either Spanner or the upstream database generates primary keys, for example to enable replication in either direction for disaster recovery during a migration cutover.
To support this, you can configure each database to have a non-overlapping key value range. When you define a range for the other database, you can tell the Spanner sequence to skip over that range with the skipped range syntax.
For example, after the bulk migration of our music tracking application, we’ll replicate data from PostgreSQL to Spanner to reduce the amount of time it takes to cut over. Once we’ve updated and tested the application on Spanner, we’ll cut over from PostgreSQL to Spanner, making it the system of record for updates and new primary keys. When we do, we‘ll reverse the flow of data between databases and replicate data back to the PostgreSQL instance just in case we need to revert if there’s a problem.
In this scenario, since SERIAL keys in PostgreSQL are 32-bit signed integers, while our keys in Spanner are larger 64-bit numbers, we will do the following steps:
1. In PostgreSQL, alter the key column to be a 64-bit column, or bigint,
2. Since the sequence singers_singer_id_seq used by singer_id is still of type int, its maximum value is already 231-1. To be safe, we can optionally set a CHECK constraint to the table in the source PostgreSQL database to ensure that singer_id values are always smaller or equal to 231-1:
3. In Spanner, we’ll alter the sequence to skip the range [1, 231-1].
4. Deploy and test your usage, including from PostgreSQL to Spanner and vice versa.
Using this technique, PostgreSQL will always generate keys in the 32-bit integer space, while Spanner’s keys are restricted to the 64-bit integer space, larger than all of the 32-bit numbers and wide enough for future growth. This ensures that both systems can independently generate keys that are guaranteed not to conflict.
Migrating UUIDs
UUID primary keys are generally easier to migrate than sequential integer keys. UUIDs, v4 in particular, are effectively unique regardless of where they are generated. (The math behind this is an interesting application of the birthday problem in statistics.) As a result, UUID keys generated elsewhere will integrate easily with new UUID keys generated in Spanner and vice versa.
The high-level strategy for migrating UUID keys is as follows:
-
Define your UUID keys in Spanner using string columns with a default expression,
GENERATE_UUID()orspanner.generate_uuid()in the PostgreSQL dialect. -
Export data from the source system, serializing the UUID keys as strings.
-
Import the keys into Spanner as-is.
-
Optionally enable foreign keys.
In Spanner, you define a UUID primary key column as a STRING or TEXT type, and assign GENERATE_UUID() as its default value. During migration, you bring all values of existing rows from the source database to Spanner, including key values. (See this migration guide for more details.) After migration, as new rows are inserted, Spanner calls GENERATE_UUID() to generate new UUID values for them. For example, the primary key FanClubId will get a UUIDv4 value when we insert a new row into the table, FanClubs:
Migrating your own primary keys
Bit-reversed sequences and UUIDs provide unique values that won’t hotspot at scale when used as a primary key in Spanner. But they don’t provide any guarantees on the ordering of their values… by design! However, some applications rely on the order of the keys to determine recency or to sequence newly created data. Databases manually sharded for scale typically rely on a global counter, coordinated outside of any independent database instances.
To use ordered keys generated externally in Spanner you create a composite key that combines a uniformly distributed value, such as a shard ID or a hash, as the first component and a sequential number as the second component. This preserves the ordered key values, but won’t hotspot at scale.
In this example, we are migrating a MySQL table with an AUTO_INCREMENT primary key, students, to Spanner. The downstream application generates student IDs, and the IDs are shared to end users (students, faculty, etc.)
In Spanner, we add a generated column containing a hash of the StudentId column:
Get started today
We recently introduced new capabilities that help users implement best practices for primary keys in Spanner using the SQL concepts they already know. The strategies detailed above minimize downstream application changes and maximize performance and availability in Spanner when migrating auto-incrementing and UUID from other relational databases.
You can learn more about what makes Spanner unique and how it’s being used today. Or try it yourself for free for 90-days or for as little as $65 USD/month for a production-ready instance that grows with your business without downtime or disruptive rearchitecture.


