Memorystore for Redis vector search and LangChain integrations for gen AI
Kyle Meggs
Sr. Product Manager, AI Infrastructure
Ping Xie
Software Engineer
In the increasingly competitive generative AI space, developers are looking for scalable and cost-effective means of differentiation and ways to improve user experience. Last week, we announced several enhancements to Memorystore for Redis, evolving it into a core building block for developers who are creating low-latency generative AI applications.
First, we launched native Memorystore support for vector store and vector search, so you can leverage Memorystore as a ultra-low latency data store for your gen AI applications and use cases such as Retrieval Augmented Generation (RAG), recommendation systems, semantic search, and more. With the introduction of vectors as first-class data types in Memorystore for Redis 7.2, we’ve augmented one of the most popular key-value stores with the functionality needed to build gen AI applications with Memorystore’s ultra-low and predictable latency.
Second, we launched open-source integrations with the popular LangChain framework to provide simple building blocks for large language model (LLM) applications. We launched LangChain integrations for:
- Vector store: Memorystore's vector store capabilities directly integrate with LangChain's vector stores, simplifying retrieval-based tasks and enabling powerful AI applications.
- Document loaders: Memorystore becomes a high-performance backend for document loaders within LangChain. Store and retrieve large text documents with lightning speed, enhancing LLM-powered question answering or summarization tasks.
- Memory storage: Memorystore now serves as a low-latency “memory” for LangChain chains, storing users’ message history with a simple Time To Live (TTL configuration). “Memory”, in the context of LangChain, allows LLMs to retain context and information across multiple interactions, leading to more coherent and sophisticated conversations or text generation.
With these enhancements, Memorystore for Redis is now positioned to provide blazing-fast vector search, becoming a powerful tool for applications using RAG, where latency matters (and Redis wins!). In addition, just as Redis is often used as a data cache for databases, you can now also use Memorystore as an LLM cache to provide ultra fast lookups — and significantly reduce LLM costs. Please check out this Memorystore CodeLab for hands-on examples of using these LangChain integrations.
For gen AI, performance matters
Several products in Google Cloud’s Data Cloud portfolio — BigQuery, AlloyDB, Cloud SQL, and Spanner — offer native support as vector stores with integrations with LangChain. So why choose Memorystore? The simple answer is performance, since it stores all the data and embeddings in memory. A Memorystore for Redis instance can perform vector search at single-digit millisecond latency over tens of millions of vectors. So for real-time use cases and when the user experience depends on low latencies and producing answers quickly, Memorystore is unrivaled for speed.
To provide the low-latencies for vector search that our users have come to expect from Memorystore, we made a few key enhancements. First, we engineered our service to leverage multi-threading for query execution. This optimization allows queries to distribute across multiple CPUs, resulting in significantly higher query throughput (QPS) at low latency — especially when extra processing resources are available.
Second, because we understand that search needs vary, we are providing two distinct search approaches to help you find the right balance between speed and accuracy. The HNSW (Hierarchical Navigable Small World) option delivers fast, approximate results — ideal for large datasets where a close match is sufficient. If you require absolute precision, the 'FLAT' approach guarantees exact answers, though it may take slightly longer to process.
Below, let’s dive into a common use case of retrieval augmented generation (RAG) and demonstrate how Memorystore’s lightning-fast vector search can ground LLMs in facts and data.
Then, we’ll provide an example of how to combine Memorystore for Redis with LangChain to create a chatbot that answers questions about movies.
Use case: Memorystore for RAG
RAG has become a popular tool for “grounding” LLMs in facts and relevant data, to improve their accuracy and minimize hallucinations. RAG augments LLMs by anchoring them with the fresh data that was retrieved based on a user query (learn more here). With Memorystore’s ability to search vectors across both FLAT and HNSW indexes and native integration with LangChain, you can quickly build a high-quality RAG application that retrieves relevant documents at ultra-low latency and feeds them to the LLM such that user questions are answered with accurate information.
Below we demonstrate two workflows using LangChain integrations: data loading in preparation for RAG, and RAG itself, to engineer improved LLM experiences.
Data loading
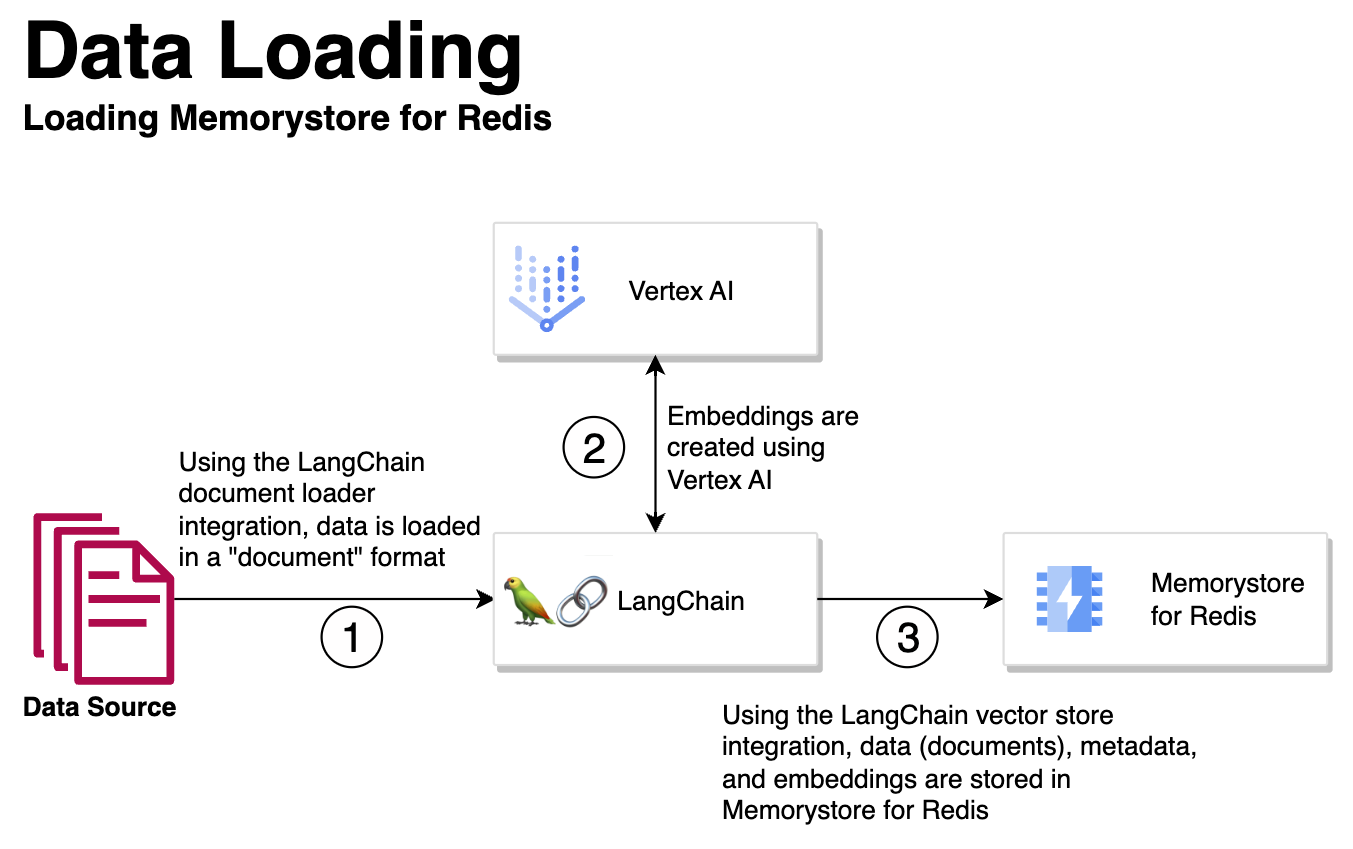
Memorystore's vector store integration with LangChain seamlessly handles the generation of embeddings and then stores them within Memorystore, streamlining the entire RAG workflow.
-
Using the LangChain Document Loader integration, data is loaded in a LangChain “document” format.
-
Data sources can include files, PDFs, knowledge base articles, data already in a database, data already in Memorystore, etc
-
Vertex AI is used to create embeddings for the loaded documents
-
Using the LangChain Vector Store integration, the embeddings from step #2, as well as metadata and the data itself, are loaded into Memorystore for Redis
Now that Memorystore for Redis is loaded with the embeddings, metadata, and the data itself, you can leverage RAG to perform ultra-fast vector search and ground your LLMs with relevant facts and data.
Retrieval augmented generation
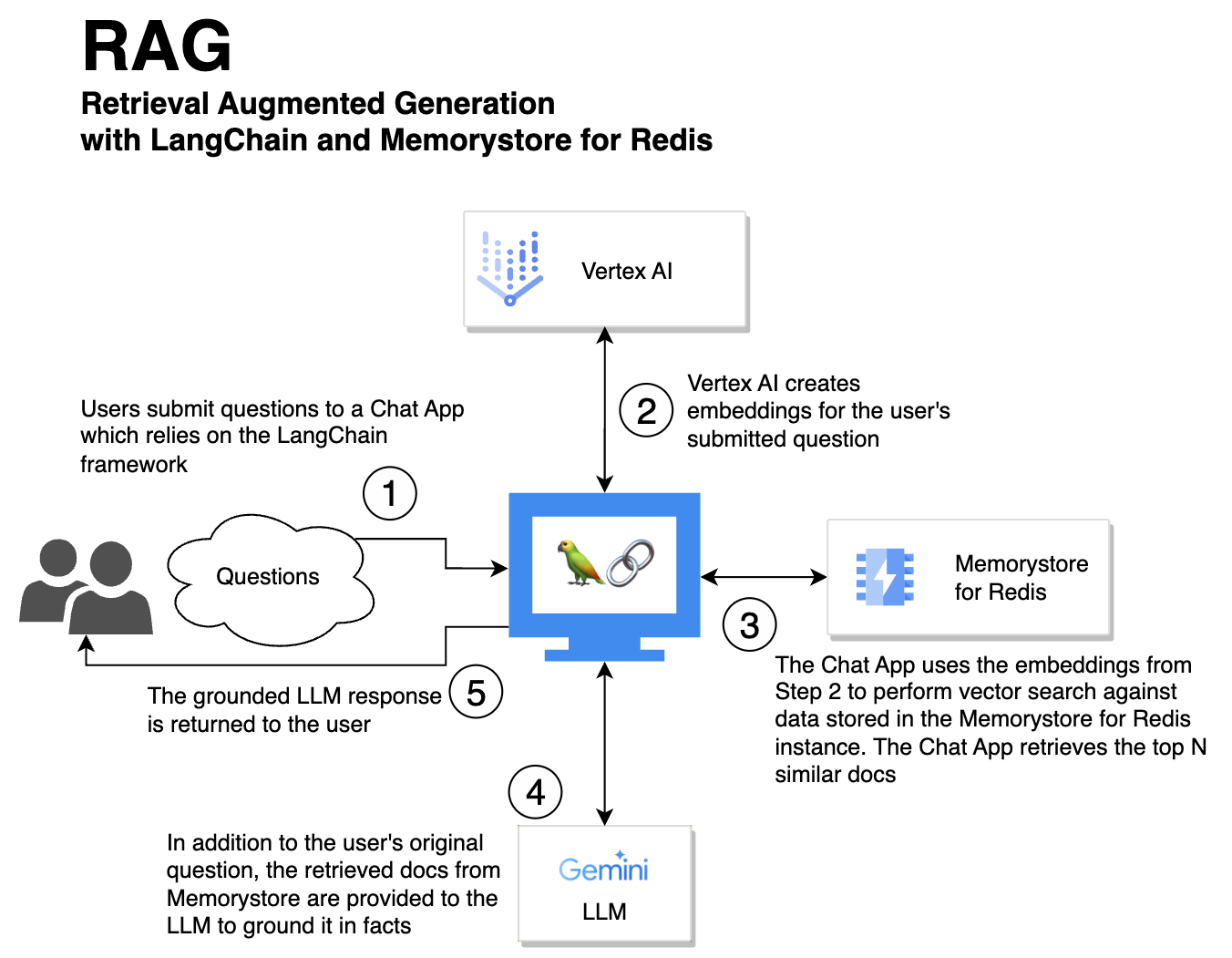
A user’s question is submitted to a chat app, which leverages Memorystore for Redis vector search to feed relevant documents to an LLM, to help ensure the LLM’s answer is grounded and factual.
- A user submits a query to a chat application that leverages the LangChain framework.
- Vertex AI is used to create embeddings for the submitted query.
- The chat application uses the embeddings from Step #2 to perform vector search against data stored in Memorystore for Redis. The chat app retrieves the top N similar docs.
- The retrieved docs are provided to the LLM along with the original user query. The retrieved docs provide relevant facts and grounding for the LLM.
- The LLM’s well-grounded answer is provided back to the original user.
Because of Memorystore’s ultra-fast vector search capabilities, the vector search performed in step 3 is extremely fast, speeding up the entire system by lowering the chat latency and improving the user experience.
Putting it all together: Build a movie chatbot
Now, let’s create a chatbot using Memorystore for Redis and LangChain that answers questions about movies based on a Kaggle Netflix dataset. The three steps below are an abridged version of the full codelab here, which details the additional prerequisite steps of provisioning a Memorystore for Redis instance, a Compute Engine VM in the same VPC, and how to enable the Vertex AI APIs.
Step 1: Dataset preparation
We start by downloading a dataset of Netflix movie titles. The dataset includes movie descriptions, which are then processed into LangChain documents.
Step 2: Connecting services
Next, we leverage an embeddings service with Vertex AI and connect to Memorystore for Redis. These services are essential for handling the semantic search and data storage needs of our chatbot:
Step 3: Chatbot integration
The final step involves integrating the processed data with our chatbot framework. We use the Redis vector store to manage movie documents and create a conversational retrieval chain. This chain leverages the embeddings and chat history to answer user queries about movies:
This streamlined process illustrates the core steps in building a conversational AI for movie inquiries, from data preparation to querying the chatbot. For those interested in all of the technical details and full code, please review the complete notebook.
Get started today
With the launch of Memorystore for Redis 7.2 in preview with its new vector search capabilities and LangChain integrations, Memorystore is now positioned to become a critical building block in your gen AI applications. We invite you to explore this new functionality and let us know how you're harnessing the power of Memorystore for your innovative use cases!


