Keep calm and query on: Running your databases in GCP
Mike Pope
Technical Editor, GCP Platform-wide docs
A fundamental piece of many applications is a database, and that’s true for many cloud-based solutions too. Running a database in the cloud is in many ways similar to running a database on-premises, but there are important differences—and advantages.
Our team—database solutions architects here at Google Cloud—works to help you understand every aspect of databases in the cloud: deploying, migrating, and managing. We want to help you choose the right way to run your database on Google Cloud Platform (GCP).
When you run a database on GCP, you can choose between managed services or running on infrastructure we manage for you. Managed services can remove some of the operational overhead required to operate a database, while running it yourself gives you full control over how your database is deployed. With both options, you get reliability, security, and elasticity built in, with the ability to get global connectivity using Google’s network.
Our team works continually to help users understand every aspect of databases in the cloud: deploying, migrating, and managing. Here are some examples of our recent solutions for using cloud databases, from deployment to monitoring.
Deploying IBM Db2
The first step for cloud-based databases is, of course, to get your database up and running. IBM Db2 is a common enterprise database, so we recently published a comprehensive solution document that describes how to deploy IBM Db2 on GCP: Deploying highly available IBM Db2 11.1 on Compute Engine with automatic client reroute and a network tiebreaker. The solution starts with setting up Compute Engine instances (VMs) to run Db2. As you can tell from the title, it goes well beyond the basics of deployment—it walks you through how to create a highly available deployment in a cluster with transaction replication and automated failover, as shown here:
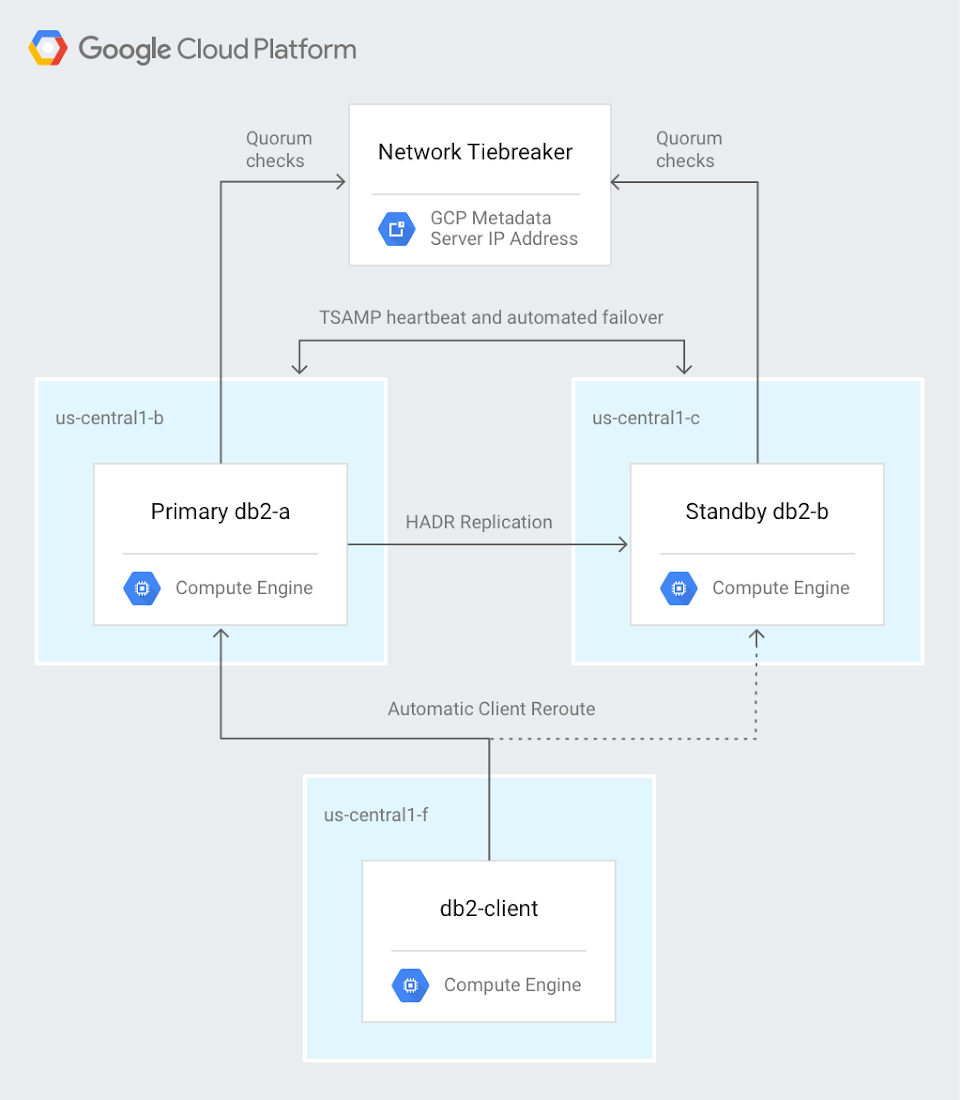
And the solution doesn't just stop when you've set everything up. The goal is high availability, so to make sure everything is working, author Ron Pantofaro shows you how to temporarily disable the primary cluster node. You can then verify that the database fails over properly and that the standby node takes over.
Migrating an existing database to GCP
In many cases, you aren't deploying a database from scratch. Instead, you want to migrate an existing database to GCP. Just migrating a database from one platform to another can have its challenges. But what if you also want to change from a NoSQL database to a relational one?
In his solution Migrating from DynamoDB to Cloud Spanner, SA Sami Zuhuruddin recently tackled this interesting and challenging transition. He describes how to move your data from Amazon DynamoDB, which is a NoSQL database, to Cloud Spanner, which is a fully relational, fault-tolerant SQL database with transaction support.
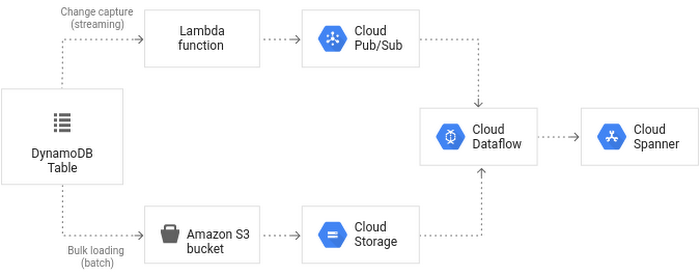
When you read Sami's solution, you'll see why you'll want to follow his expert guidance for this task. The process goes through a number of intermediate steps that include Amazon S3, Google Cloud Storage, AWS Lambda, Cloud Pub/Sub, and Cloud Dataflow before arriving at Cloud Spanner. Sami explains the data model on both sides of the migration, including keys, data types, and indexes. You’ll see which user permissions you need in order to perform each step. The solution walks you through the entire process, including verification at the end. Here’s a look at the architecture involved:
Backing up a database
It's just as important in the cloud as it is on-premises to back up your databases. Two recent solutions discuss ways to do this.
In Using Microsoft SQL Server backups for point-in-time recovery on Compute Engine, SA Ron Pantofaro turns his hand from deployment to backup and shows you how to configure backup for a SQL Server instance that's running on Compute Engine. You’ll see how to back up both the data and the database logs to Cloud Storage. He also describes how to restore a backup in case you ever need to do that (though we hope not). This isn't the end of the job, though. From there, you’ll see how to schedule your backups and how to prune backups that you no longer need.
Of course, you might be using a different database. In Performing MySQL Hot Backups with Percona XtraBackup and Cloud Storage, the SA team shows a similar set of tasks—backing up, restoring, scheduling, and pruning—but for MySQL databases.
Adding tracing to your GCP-based database
One of the benefits of running a database in GCP is that you can take advantage of services like Stackdriver to gather tracing information. In his community tutorial Client-side tracing of Cloud Memorystore for Redis workloads with OpenCensus, SA Karthi Thyagarajan discusses how to add tracing that lets you measure data-retrieval latency. This solution uses a data store consisting of Cloud Memorystore backed by Cloud Storage. As he says, this lets you "focus on the key aspects of client-side tracing without getting hung up on things like database deployments and related configuration."
You can download the Java client app that Karthi created as a Java client app that you can get from GitHub, which already contains the logic for reading from the data store and generating trace output. After you've got the data store set up, you run the client app to read data. You can see some of the benefits of the instrumentation you've set up—you go to the Stackdriver console and visually compare the latencies of cached and non-cached reads: