How Streak built a graph database on Cloud Spanner to wrangle billions of emails
Fred Wulff
VP of Engineering, Streak
[Editor’s note: Streak makes a CRM add-on for Gmail, and recently adopted Cloud Spanner to take advantage of its scalability and SQL capabilities to implement a graph data model. Read on to learn about their decision, what they love about the system, and the ways in which it still needs work.]
Streak is a customer relationship management (CRM) tool built directly into Gmail. It is used for sales, marketing, hiring, and just about anything else you can think of. We built it because out of the box, email is actually a really crummy team sharing system. By adding a layer of organization on top of email, Streak lets you add email threads directly into its spreadsheet view, making it useful as a workflow tool with capabilities including task creation, email template management, and easy data entry.
Streak has been integrated with G Suite (originally Google Apps For Your Domain) since its inception so when choosing a cloud, it made sense to colocate our server stack with Google Cloud. Likewise, Streak was on Google App Engine from the start, and we slowly added other GCP services as the offerings improved or as our use cases became more complex. In addition to App Engine, we use Google Kubernetes Engine to run a bunch of our compute workload, including both application servers and our offline processes like indexers and task queue consumers. We use Cloud Dataflow for both streaming event processing and logs ETL, and BigQuery for all of our analytics queries. We use Cloud Pub/Sub for interacting with the Gmail watch API, as well as Stackdriver (logging, tracing, monitoring, errors) and OpenCensus to dig into any operational issues as they arise.
Then, on the database front, we recently started using Cloud Spanner, Google Cloud’s scalable relational database service. Before that, we stored most of our business data in Cloud Datastore, Google Cloud’s NoSQL document database. Partially, that was historical, since Cloud Datastore was GCP’s only managed database when we wrote the Streak backend. And we’ve been very happy with how easy Cloud Datastore is to maintain. Between Google App Engine and Cloud Datastore, we’ve never had to have an explicit infrastructure on-call rotation.
But as more users rely on Streak to collaborate with larger and larger teams, we were feeling the pain of not having a fully relational database. We found ourselves having to manually join data in our application, which increased application latency and increased the time developers spent coding workarounds and debugging that complexity.
We found we needed two things out of our database: a scalable relational store and a graph store that could power next-gen Streak features. At the same time, we wanted a single database that could handle both use cases and wouldn’t increase our operational burden. This meant finding a managed service to give us more query flexibility, so we decided to give Cloud Spanner a try.
Of course, we didn’t want to migrate our existing stack to a new data platform without first testing it out (never a smart strategy). But since most of our existing data model required transactional updates with other entities, pulling out a single entity to test was challenging. We did have a feature in our pipeline that necessitated a graph data store and that was removed from our other data: our email metadata indexing system.
How your client software handles email metadata indexing can make or break the useability of a system. Think about how many times somebody forgets to reply-all or that you receive a forwarded thread with thirty emails in reverse-chronological order. Within our own inboxes, we rely on Gmail’s UI to nicely organize email threads, but that organization breaks down when working with a team or across organizational boundaries.
We decided to fix that in the Streak product by organizing metadata (i.e., headers but not message content) from users’ email by using Cloud Spanner as a graph database. Using a graph database lets us answer questions like “What are all the emails on this thread in the inboxes of everybody on my team?” and “Who on my team has previously talked with the organization that this prospect works at?”
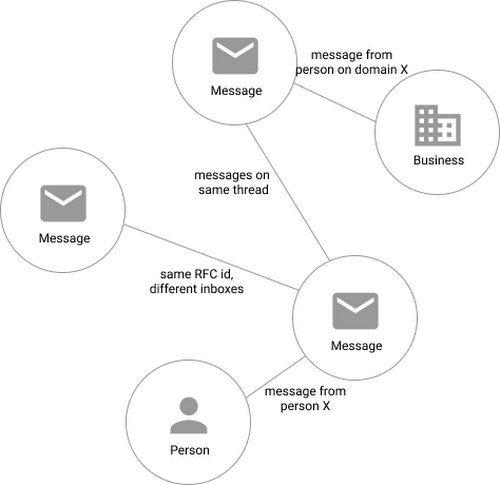
In our model, the nodes of the graph are either an email message, a person (email address) or a company (a domain). Then we have four different types of “edges”— properties by which nodes in a graph connect to one another:
Message to message (thread): messages that are on the same thread have an edge between them. The reason we do this is because we want to show users a list of threads to answer their questions, not messages, so we need to be able to get the spanning set of messages.
Message to message (same RFC id): A core value proposition of Streak is being able to see the “unified” version of a thread that shows each person on a team’s version of the email thread. To make sure we are getting each user’s version of a thread when we issue a query, there needs to be an edge between a message in the queryer’s inbox and the same message in their team’s inbox. In case you’re curious, Streak uses the RFC message id to determine that two messages across inboxes are actually the same.
Email address to message: a message has an edge to an email address if it was either the from, to, cc, or bcc on the message. This edge is crucial for queries that start with: “Show me all threads between this person and our team.”
Domain to message: a message has an edge to a domain if the domain is present in any of the from, to, cc, or bcc addresses on the message. This edge is similarly used for queries that start with “Show me all threads between this company and our team.”
Using Cloud Spanner’s distributed SQL capabilities and scalability to build a graph database also let us answer the important follow-up question: “Which threads have I been granted permission to view?” And while a lot of these questions could be answered per-user by a traditional relational database, scale limitations have to be taken into consideration, especially as we plan for 10x or more data volume growth as both our user base grows and as their inboxes accumulate more emails. A graph database model is simply a better fit for Streak’s collaboration model with many-to-many mappings between users and teams, and will allow us to query the data in any number of configurations, without worrying about scale limitations or having to manually shard a relational database. Cloud Spanner gives us queryability and scalability.
Taking the Cloud Spanner plunge
With so many advantages to it, we went ahead and began building out our metadata system with Cloud Spanner as a back-end.
Adopting Cloud Spanner has been great. Here are some of the high points:
The fast distributed queries and transactions are absolutely real. We have global indexes across our entire dataset and we haven’t had to spend very much time at all thinking about co-locating data. In particular, we only use interleaved tables for values that would be repeated fields in Cloud Datastore, and that hasn’t been a problem for us yet.
We haven’t had any reliability problems whatsoever, despite averaging 20K writes/sec in steady state.
Once we optimized our queries on realistic data, Cloud Spanner scaled up in a surprisingly predictable way. You need to run queries after you've populated data, do the explain to figure out how the query planner is executing the query, and add indexes/modify queries to make sure they're performant.
Compared to the hoops some traditional relational databases make you jump through, Cloud Spanner’s online schema changes and index builds are magical. There is no downtime for these operations.
That doesn’t mean that deploying Cloud Spanner hasn’t been without its hiccups. In the “less great” camp, there are a few items to note.
The observability tooling is still pretty immature. It can be hard to tell what queries are driving CPU usage (à la pgbouncer or similar tools). We’re making do with OpenCensus tracing (there’s integration in the Cloud Spanner client libraries) and watching closely as we roll out new queries, but we’re looking forward to tighter integration with more robust monitoring tools.
The Cloud Spanner query planner can be a bit unintuitive—you definitely need to be comfortable with explaining and iterating on your queries with real data.
It’s not cheap (in an absolute sense). You pay a pretty hefty premium for Cloud Spanner compute compared to other databases, but you obviously get a lot of features too. It’s all baked into the price.
There isn’t a fully fleshed out local development/testing story yet. We’re doing okay with a separate instance for development, but it definitely adds friction and cost to the dev pipeline.
Overall, the experience has been encouraging, and we’re planning to move 20 TB of existing data in Cloud Datastore to Cloud Spanner as well. We built out an ORM library for Java on top of Cloud Spanner called Ratchet and are testing a framework for dual-writing entities to both Cloud Datastore and Cloud Spanner to support the rest of the migration. We now store about 40 TB of email metadata in Cloud Spanner, which makes us a large user of Cloud Spanner.
In short, if you’re starting to outgrow your NoSQL database, and want to move to a managed SQL database, give Cloud Spanner a try. You definitely want to model out your costs and try out a proof of concept, both to see how it works on your workload and to get familiar with the quirks of the system. But you don’t need to spend much time worrying about the reliability of the product: it’s there. Don’t hesitate to reach out to me with questions.


