Unlocking the power of semi-structured data with the JSON Type in BigQuery
Nagesh Susarla
Software Engineer
Eric Schmidt
Product Manager
Enterprises are generating data at an exponential rate, spanning traditional structured transactional data, semi-structured data like JSON and unstructured data like images and audio. The diversity and volume of data presents complex architectural challenges for data processing, data storage and query engines, requiring developers to build custom transformation pipelines to deal with semi-structured and unstructured data.
In this post we will explore the architectural concepts that power BigQuery’s support for semi-structured JSON, which eliminates the need for complex preprocessing and provides schema flexibility, intuitive querying and the scalability benefits afforded to structured data. We will review the storage format optimizations, performance benefits afforded by the architecture and finally discuss how they affect the billing for queries that use JSON paths.
Integration with the Capacitor File Format
Capacitor, a columnar storage format, is the backbone of BigQuery’s underlying storage architecture. Based on over a decade of research and optimization, this format stores exabytes of data, serving millions of queries. Capacitor is optimized for storing structured data. Capacitor uses techniques like Dictionary, Run Length Encoding (RLE), Delta encoding etc. to store the column values optimally. To maximize RLE, it also employs record-reordering. Usually, row order in the table does not have significance, so Capacitor is free to permute rows to improve RLE effectiveness. Columnar storage lends itself to block oriented vectorized processing which is employed by an embedded expression library.
To natively support semi-structured formats like JSON, we developed the next generation of the BigQuery Capacitor format optimized for sparse semi-structured data.
On ingestion, JSON data is shredded into virtual columns to the extent possible. JSON keys are typically only written once per column instead of once per row. Other non data characters such as colons and whitespace are not part of the data stored in the columns. Placing the values in columns allows us to apply the same encodings that are used for structured data such as Dictionary encoding, Run Length Encoding and Delta encoding. This greatly reduces storage and thus IO costs at query time. Additionally, JSON nulls and arrays are natively understood by the format leading to optimal storage of virtual columns. Fig. 1 shows the virtual columns for records R1 and R2. The records are fully shredded into nested columns.
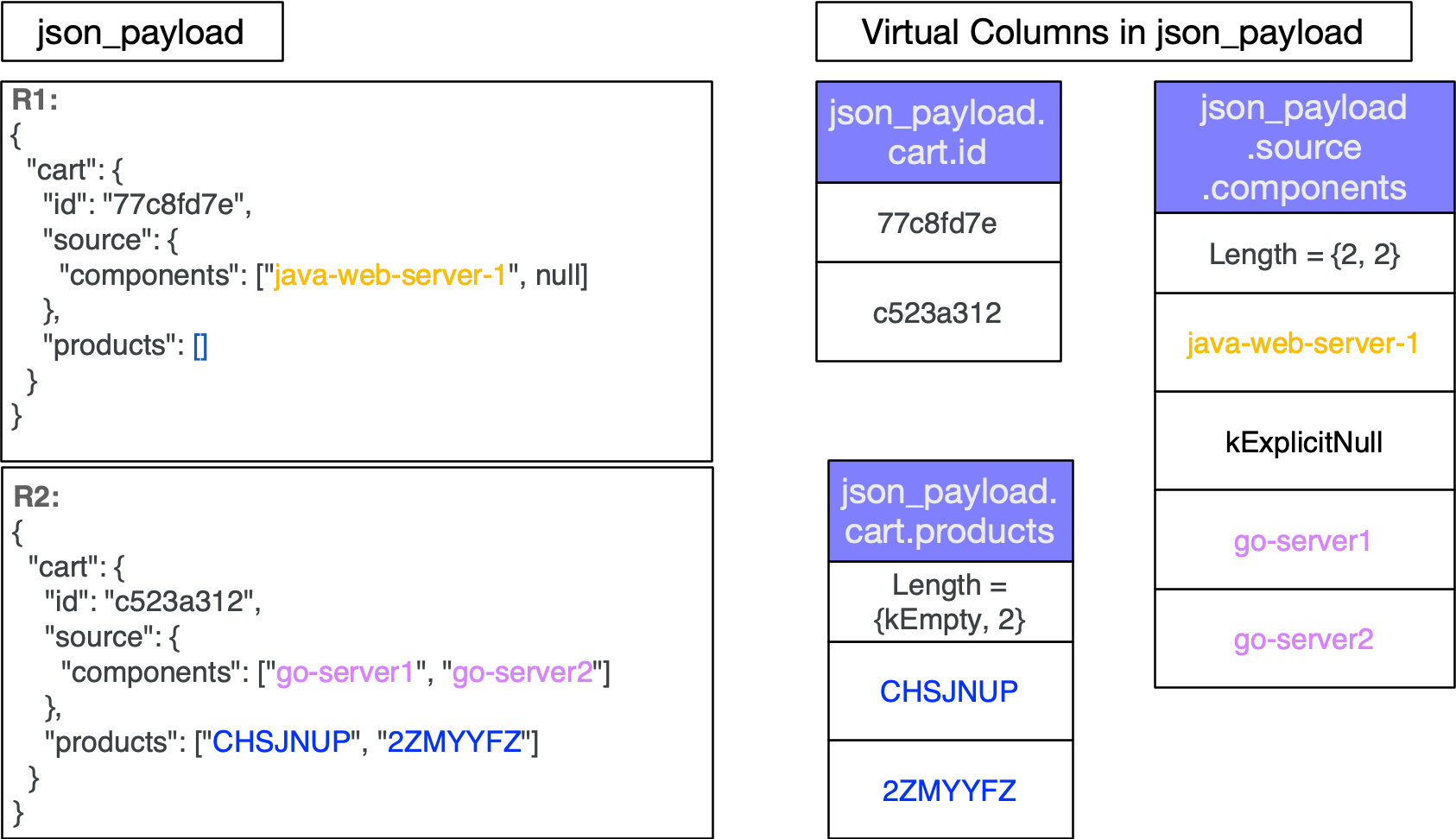
Figure 1: Shows the virtual columns for given records R1 and R2
BigQuery’s native JSON data type maintains the nested structure of JSON by understanding JSON objects, arrays, scalar types, JSON nulls ('null') and empty arrays
Capacitor, the underlying file-format of the native JSON data type, uses record-reordering to keep similar data and types together. The objective of record-reordering is to find an optimal layout where Run Length Encoding across the rows is maximized resulting in smaller virtual columns. In the event of a particular key having different types, say integer and string across a range of rows in the file, record-reordering results in grouping the rows with the string data type together and the rows with the integer type together resulting in run length encoded spans of missing values in both virtual columns thus producing smaller columns. To illustrate the column sizes, Fig. 2 shows a single key `source_id` that is either an integer or a string across the source JSON data. This produces two virtual columns based on the types. It showcases how reordering and applying RLE results in small virtual columns. For simplicity, we use `kMissing` to denote a missing value.
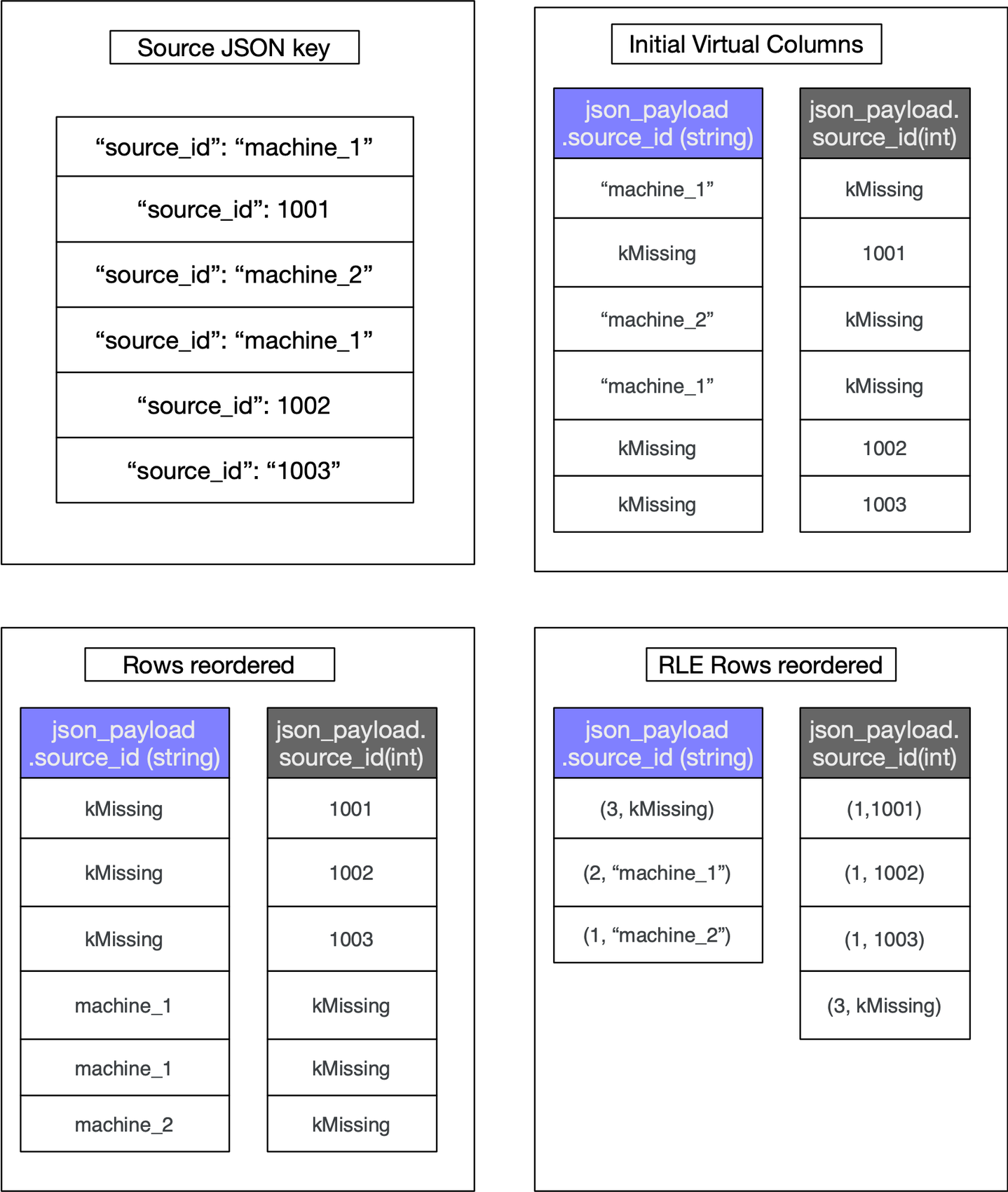
Figure 2 : Shows the effect of row reordering on column sizes.
Capacitor was specifically designed to handle well structured datasets. This was challenging for JSON data which takes a variety of shapes with a mix of types. Here are some of the challenges that we overcame while building the next generation of Capacitor that natively supported the JSON data type.
- Adding/Removing keys
JSON keys are treated as optional elements thus marking them as missing in the rows that don't have the keys. - Changing Scalar Types
Keys that change scalar types such as string, int, bool and float across rows are written into distinct virtual columns. - Changing Types with non-scalar types
For non-scalar values such as object and array, the values are stored in an optimized binary format that's efficient to parse.
At ingestion time, after shredding the JSON data into virtual columns, the logical size of each virtual column is calculated based on the data size [https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#data_type_sizes] for specific types such as INT64, STRING, BOOL. Thus the size of the entire JSON column is the sum of the data sizes of each virtual column stored in it. This cumulative size is stored in metadata and becomes the upper bound logical estimated size when any query touches the JSON column.
These techniques produce individual virtual columns that are substantially smaller when compared to the original JSON data. For example, storing a migrated version of bigquery-public-data.hacker_news.full discussed below as a JSON column compared to STRING, leads to a direct saving of 25% for logical uncompressed bytes.
Improved Query Performance with JSON native data types
With the JSON data stored in a STRING column, if you wanted to filter on certain JSON paths or only project specific paths, the entire JSON STRING row would have to be loaded from storage, decompressed and then each filter and projection expression evaluated one row at a time.
In contrast, with the native JSON data type, only the necessary virtual columns are processed by BigQuery. To make projections and filter operations as efficient as possible, we added support for compute and filter pushdown of JSON operations. Projections and filter operations are pushed down to the embedded evaluation layer that can perform the operations in a vectorized manner over the virtual columns making these very efficient in comparison to the STRING type.
When the query is run, customers are only charged based on the size of the virtual columns that were scanned to return the JSON paths requested in the SQL query. For example, in the query shown below, if payload is a JSON column with keys `reference_id` and `id`, only the specific virtual columns representing the JSON keys namely `reference_id` and `id` are scanned across the data.
Note: The estimate always shows the upper bound of the total JSON size rather than specific information about the virtual columns being queried.
With the JSON type, on-demand billing reflects the number of logical bytes that had to be scanned. Since each virtual column has a native data type such as INT64, FLOAT, STRING, BOOL, the data size calculation is a summation of sizes of each column `reference_id` and `id` that was scanned and follows the standard bigquery data type size [https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types#data_type_sizes]
With BigQuery Editions, optimized virtual columns lend to queries that require far less IO and CPU in comparison to storing the JSON string unchanged since you're scanning specific columns rather than loading the entire JSON blob and extracting the paths from the JSON string.
With the new type, BigQuery is now able to process just the paths within the JSON that are requested by the SQL query. This can substantially reduce query cost.
For instance running a query to project a few fields such as `$.id` and `$.parent` from a migrated version of the public dataset `biquery-public-data.hacker_news.full` containing both STRING and JSON type of the same data shows a reduction of processed bytes from 18.28GB to 514MB which is a 97% reduction.
The following query was used for creating a table from the public dataset that contains both a STRING column in `str_payload` and a JSON column in `json_payload` and saved to a destination table.
Summary
The improvements to the Capacitor file format have enabled the flexibility required by today’s semi-structured data workloads. Shredding the JSON data into virtual columns along with enhancements such as compute and filter pushdown has shown promising results. Since the JSON data is shredded, only the virtual columns matching the requested JSON paths are scanned by BigQuery. Compute and filter pushdowns make it possible for the runtime to do work closest to the data evaluation layer in a vectorized manner thus exhibiting better performance. Lastly these choices have made it possible to improve compression and reduce the IO/CPU usage (smaller columns = less IO) as a result, reducing the slot usage for fixed-rate reservations and the bytes billed for on-demand usage.
Beyond the storage and query optimizations, we've also invested in programmability and ease of use by providing a range of JSON SQL Functions. Also see the latest blog post about the new JSON SQL functions that were released recently.
Next Steps
Convert to the JSON native data type in BigQuery today!
To convert your table with a STRING JSON column into a table with a native JSON column, run the following query and save the results to a new table, or select a destination table.
Documentation for the JSON Functions and more can be found at https://cloud.google.com/bigquery/docs/reference/standard-sql/json_functions.
