The big picture: How Google Photos scaled rapidly on Spanner
Dave Perra
Software Engineer, Photos
Tracy Ferrell
Devices & Services SRE Lead
Mobile photography has become ubiquitous over the past decade, and it’s now easier than ever to take professional quality photos with the push of a button. This has resulted in explosive growth in the number of photo and video captures, and a huge portion of these photos and videos contain private, cherished, and beloved memories — everything from small, everyday moments to life’s biggest milestones. Google Photos aims to be the home for all these memories, organized and brought to life so that users can share and save what matters.
With more than one billion users and four trillion photos and videos — and with the responsibility to protect personal, private, and sensitive user data — Google Photos needs a database solution that is highly scalable, reliable, secure, and supports large scale data processing workloads conducive to AI/ML applications. Spanner has proved to be exactly the database we needed.
A picture says a thousand words
Google Photos offers a complete consumer photo workflow app for mobile and web. Users can automatically back up, organize, edit, and share their photos and videos with friends and family. All of this data can be accessed and experienced in delightful ways thanks to machine learning-powered features like search, suggested edits, suggested sharing, and Memories. With Photos storing over 4 trillion photos and videos, we need a database that can handle a staggering amount of data with a wide variety of read and write patterns.
We store all the metadata that powers Google Photos in Spanner, including both media-specific and product-specific metadata for features like album organization, search, and clustering. The Photos backend is composed of dozens of microservices, all of which interact with Spanner in different ways, some serving user-facing traffic, and others handling batch traffic. Photos also has dozens of large batch-processing Flume pipelines that power our most expensive workloads: AI/ML processes, data integrity management, and other types of full account or database-wide processing.
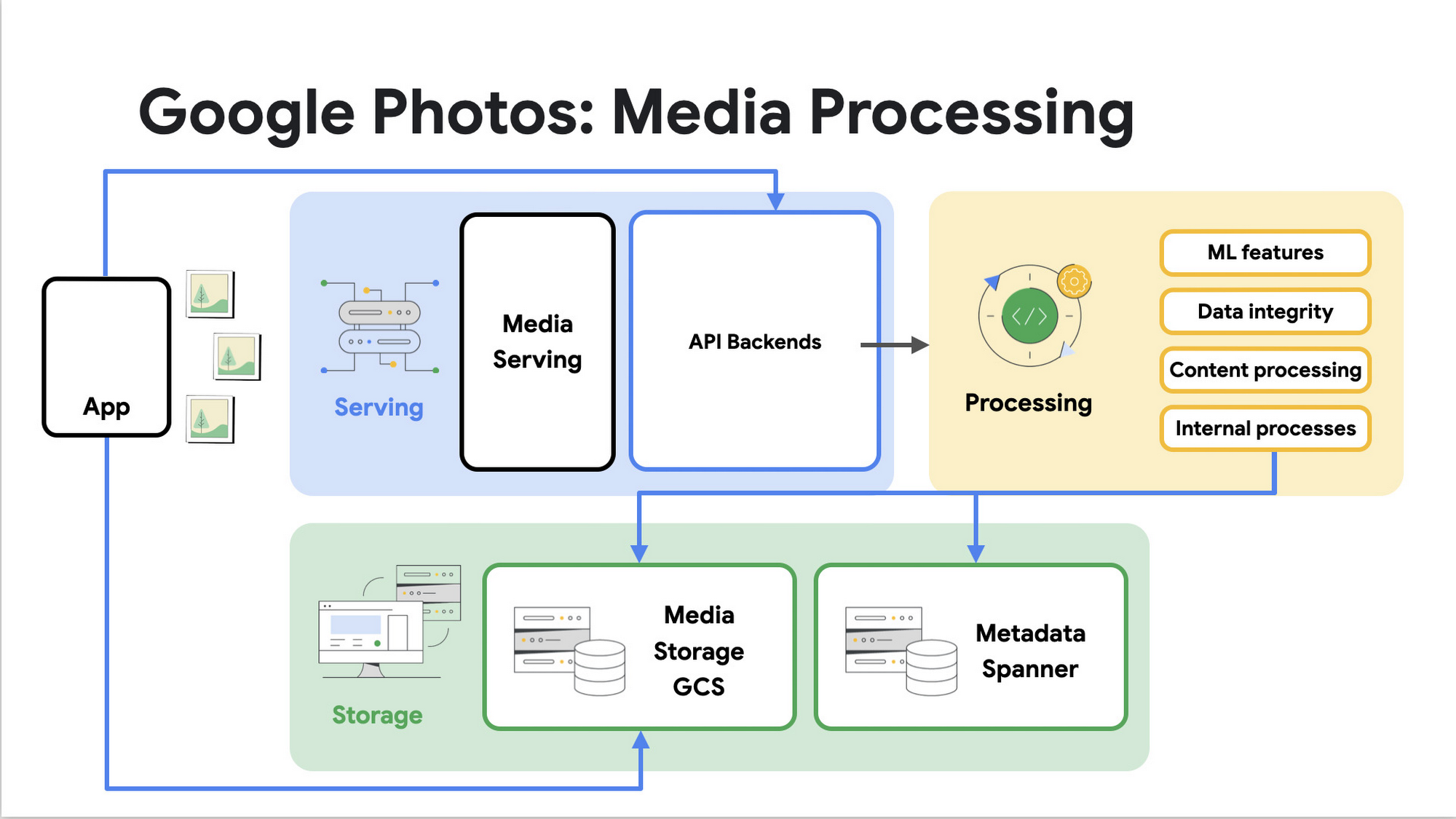
High level architecture for media processing in Google Photos using Spanner
Despite Google Photos’ size and complexity, Spanner has a number of features that make our integration easy to maintain. Thanks to Spanner’s traffic isolation, capacity management, and automatic sharding capabilities, we are able to provide a highly reliable user experience even with unpredictably bursty traffic loads. Balancing our online and offline traffic is also manageable thanks to Spanner’s workload tunable replication capabilities.
Photos enables users to access all of their photos at any time, reliably across the globe. Photos relies on Spanner to automatically replicate data with 99.999% availability. Spanner’s sharding capabilities give us low latency worldwide, help us smooth our computational workloads, and make it easy for us to support the ever increasing set of regulatory requirements concerning data residency.
The system has to be reliable and available for user uploads, while simultaneously ensuring that ML-based features not only perform well, but also don’t impact interactive traffic. Spanner’s sharding flexibility allows both these use cases to be satisfied in the same database. We have read-only and read/write shards to separate these use cases. We need to serve our active online users quickly because we know they expect their photos to be instantaneously displayed and shareable.
Photos also has strict consistency and concurrency needs. That’s not surprising when you consider the variety of first- and third-party clients that upload media, processing pipelines performing updates, and various feature needs – many of which involve cross-user sharing. It’s Spanner’s high write throughput, consistency guarantees, and resource management tools that have allowed Photos to build and scale these features and pipelines by 10x with minimal re-architecture. Our use of Spanner has proven Spanner’s ability to scale rapidly without compromise — something rare in traditional, vertically scalable SQL databases.
Equally as important, Spanner has significantly increased our operational efficiency. We now save a lot of time and energy on tactical placement, location distribution, redundancy, and backup management. Replica management is a simple matter of configuration management, and we rely on Spanner to manage the changes. In addition, automated index verifications, automatic sharding, and guaranteed data consistency across all regions, save us a lot of manual work.
Trust paints the whole picture
Our users entrust us with their private and precious data, and we take that responsibility very seriously. Privacy, security, and safety are incredibly important to Google Photos — they are core principles that are considered in every feature and user experience that we build. Spanner’s secure access controls help significantly by eliminating unilateral data access, managing the risk of internal or external data breaches, and ensuring that data privacy is respected throughout our backend.
Reliability and trust are the cornerstones of Google Photos. It’s critical that users can access their data whenever they want it, and that fundamental product features like backup and sharing remain highly available even during peak load (holidays, for example). The Photos team continues to heavily focus on reliability improvements to ensure that we’re delivering the experience that our users have come to expect from Google. Thanks to Spanner’s ongoing investment in this area, Photos has been able to continuously raise this bar — which is particularly notable given Photos’ own rapid growth rate. Running multiple replicas is a key aspect of how our system runs reliably, and Spanner’s strong external consistency features and continuous index verifications ensure that data remains correct. In addition, Spanner offers robust backup and recovery systems which provide us even more confidence that our datastores will remain correct and complete.
Picture perfect
The numbers speak for themselves. Spanner supports a staggering amount of traffic across many regions, over a billion users, and metadata for more than four trillion images. We’ve already experienced 10x growth since launching our Spanner database, and we’re confident that Spanner can support another 10-fold increase in the future. Going forward, we’re confident in Spanner’s robust, easy-to-use nature to help us scale to the next billion users and drive even more incredible experiences for our users.

Learn more
Read the blog “SIGOPS Hall of Fame goes to Spanner paper — here’s why that matters” by Chris Taylor, Distinguished Software Engineer, on the recent award and the evolution of Spanner.
Learn more about Cloud Spanner and create a 90-day Spanner free trial instance.


