Autoscaling Dataproc for Trino workloads
Shikha Gupta
Solutions Architect
Anant Damle
Solutions Architect
Trino is a popular, open-source, distributed SQL query engine for data lakes and warehouses. It is used by many businesses to analyze large datasets stored in Hadoop Distributed File System (HDFS), Cloud Storage, and other data sources. Dataproc is a managed Hadoop and Spark service that makes it easy to set up and manage clusters. However, Dataproc currently does not support autoscaling for workloads that aren’t based on Yet Another Resource Negotiator, or YARN, such as Trino.
Autoscaling Dataproc for Trino addresses the lack of autoscaling support for non-YARN based workloads, preventing overprovisioning, underprovisioning, and manual scaling efforts. It automatically scales clusters based on workload demand, saving cloud costs, improving query performance, and reducing operational workload. This makes Dataproc a more attractive platform for Trino workloads, enabling real-time analytics, risk analysis, fraud detection, etc. In this blog post, we present a solution that provides autoscaling for Trino when running on a Dataproc cluster.
Trino and Hadoop
Hadoop is an open-source software framework for distributed storage and processing of large datasets across a cluster of computers. It provides a reliable, scalable, and distributed computing platform for big data processing. Hadoop utilizes a YARN centralized resource manager to allocate resources, monitor, and manage the cluster.
Trino can use various data sources like Hadoop, Hive, and other data lakes and warehouses, allowing users to query data in different formats and from different sources using a single SQL interface.
In Trino, resource allocation and management are driven by the Trino Coordinator, which is responsible for query coordination, planning, and resource allocation. Trino dynamically allocates resources (CPU and memory) on a fine-grained level for each query. Trino clusters often rely on external cluster management systems like Kubernetes for resource allocation and scaling. These systems handle cluster resource provisioning and scaling dynamically. Trino does not use YARN for resource allocation when running on Hadoop clusters.
Dataproc and Trino
Dataproc is a managed Hadoop and Spark service, providing a fully managed environment for big data workloads on Google Cloud. Dataproc currently only supports autoscaling for YARN-based applications. This poses a challenge for optimizing the costs of running Trino on Dataproc, as the cluster size should be adjusted based on current processing needs.
Autoscaler for Trino on Dataproc solution provides reliable autoscaling for Trino on Dataproc without compromising workload execution.
Trino challenges
Trino deployment on Dataproc uses Trino’s embedded discovery service. Every Trino node connects with the discovery service on startup and periodically sends a heartbeat signal.
When adding an extra worker to the cluster, the worker registers with the discovery service, allowing the Trino coordinator to start scheduling new tasks for the new workers. But removing a worker from the cluster can be difficult if a worker suddenly shuts down, which can result in complete query failure.
Trino has a graceful shutdown API that can be used exclusively on workers in order to ensure they terminate without affecting running queries. The shutdown API puts the worker in a SHUTTING_DOWN state and the coordinator stops sending new tasks to the workers. In this state, the worker will continue to execute any currently running tasks, but it will not accept any new tasks. Once all of the running tasks have finished executing, the Trino worker will exit.
This Trino worker behavior requires the Trino Autoscaler solution to monitor workers to ensure that they gracefully exit before removing the VMs from the cluster.
Solution approach
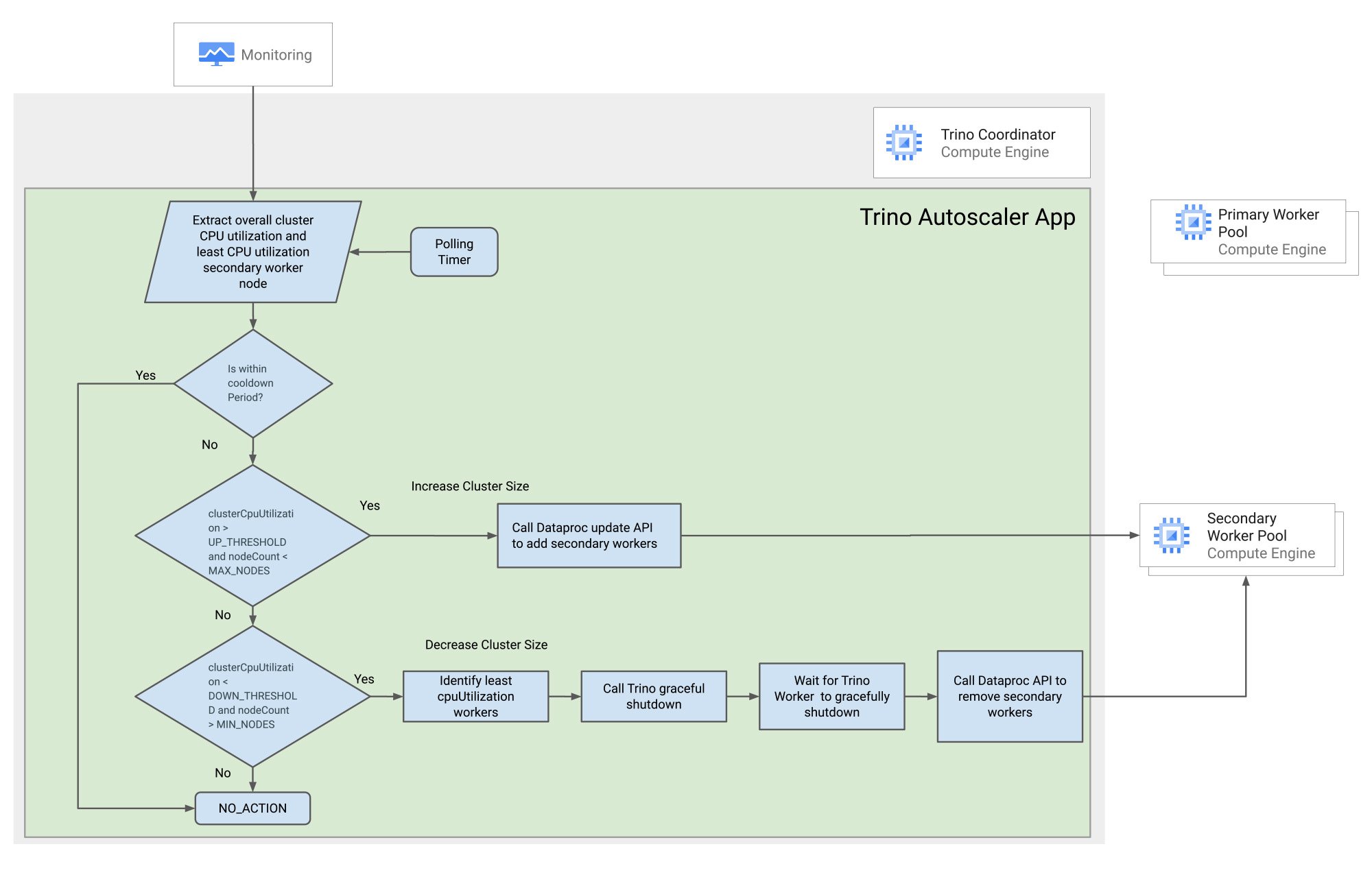
By polling the Cloud Monitoring API, the solution monitors the cluster's CPU utilization and the details of the least CPU-utilized secondary worker nodes. After each scaling action, there is a cooldown period during which no other scaling action is taken. The cluster is scaled up or down based on CPU utilization and worker node count.
Considerations
- Cluster sizing decisions are made based on overall CPU utilization, and the node to be removed is based on the secondary worker node using the least CPU.
- Increasing or decreasing cluster size only adds or removes secondary worker nodes, which are preemptive VMs by default, and avoids any interruption to HDFS workloads.
- The application runs on the coordinator node, and autoscaling is disabled by default in Dataproc.
- The addition of new workers will only help new job submissions; existing jobs continue to run on bound workers.
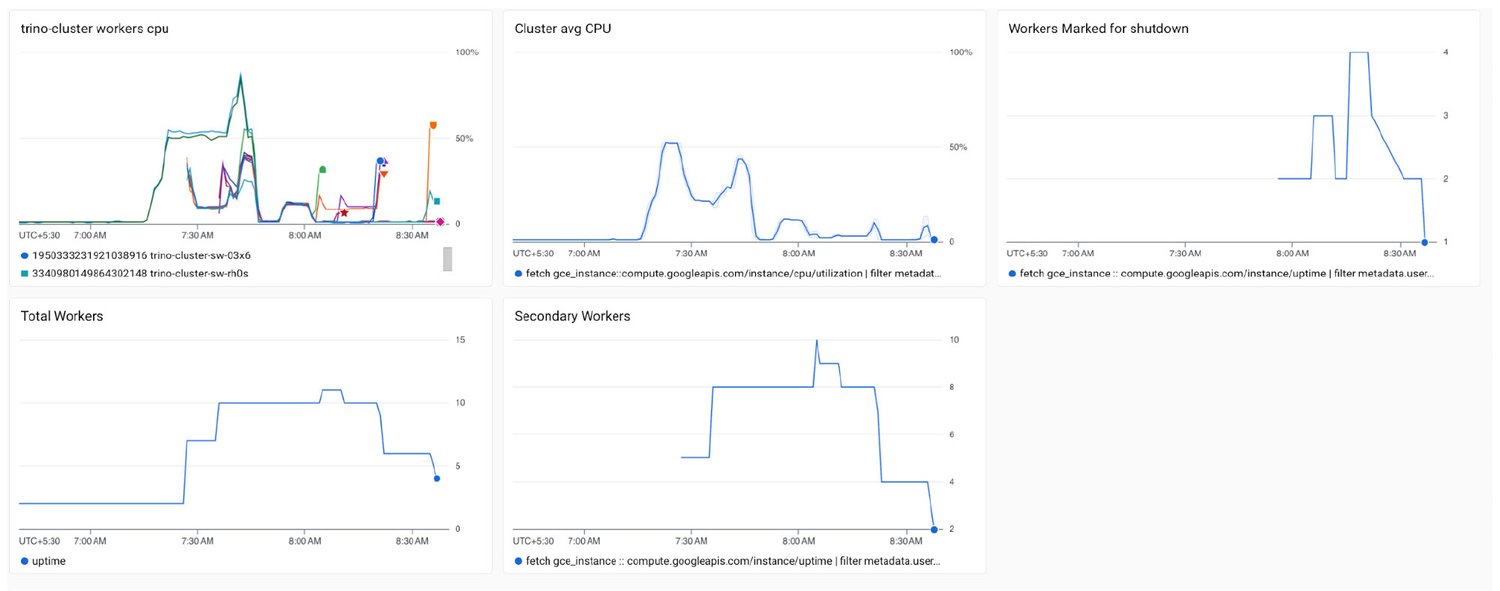
The above graphs show the results of running the solution, indicating the increase or decrease in the number of workers based on whether the average CPU utilization is increasing or decreasing. The solution clearly labels the workers in the process of shutting down.
Conclusion
Automatic scaling of your Dataproc cluster based on workload can ensure that you only use the resources you need. Autoscaling can lead to significant cost savings, especially for workloads that experience variable demand.
In addition to optimizing cost, the autoscaling solution can help improve performance by scaling up your cluster during times of high demand, ensuring that your queries are processed quickly and efficiently. This can come in handy for time-sensitive workloads, such as real-time analytics.
To get started, follow our step-by-step guide.

