AlloyDB for PostgreSQL under the hood: Intelligent, database-aware storage

Ravi Murthy
Engineering Director, AlloyDB
Gurmeet (GG) Goindi
Director Product Management, Databases
Today, at Google I/O, we announced AlloyDB for PostgreSQL, a fully-managed, PostgreSQL-compatible database for demanding, enterprise-grade transactional and analytical workloads. Imagine PostgreSQL plus the best of the cloud: elastic storage and compute, intelligent caching, and AI/ML-powered management. Further, AlloyDB delivers unmatched price-performance: In our performance tests, it’s more than 4x faster on transactional workloads, and up to 100x faster analytical queries than standard PostgreSQL, all with simple, predictable pricing. Designed for mission-critical applications, AlloyDB offers extensive data protection and an industry leading 99.99% availability.
Multiple innovations underpin the performance, and availability gains of AlloyDB for PostgreSQL. In the first part of our “AlloyDB for PostgreSQL under the hood” series, we are covering the intelligent, database-aware, horizontally scalable storage layer that’s optimized for PostgreSQL.
Disaggregation of compute and storage
AlloyDB for PostgreSQL was built on the fundamental principle of disaggregation of compute and storage, and is designed to leverage disaggregation at every layer of the stack.
AlloyDB begins by separating the database layer from storage, introducing a new intelligent storage service, optimized for PostgreSQL. This reduces I/O bottlenecks, and allows AlloyDB to offload many database operations to the storage layer through the use of a log-processing system. The storage service itself also disaggregates compute and storage, allowing block storage to scale separately from log processing.
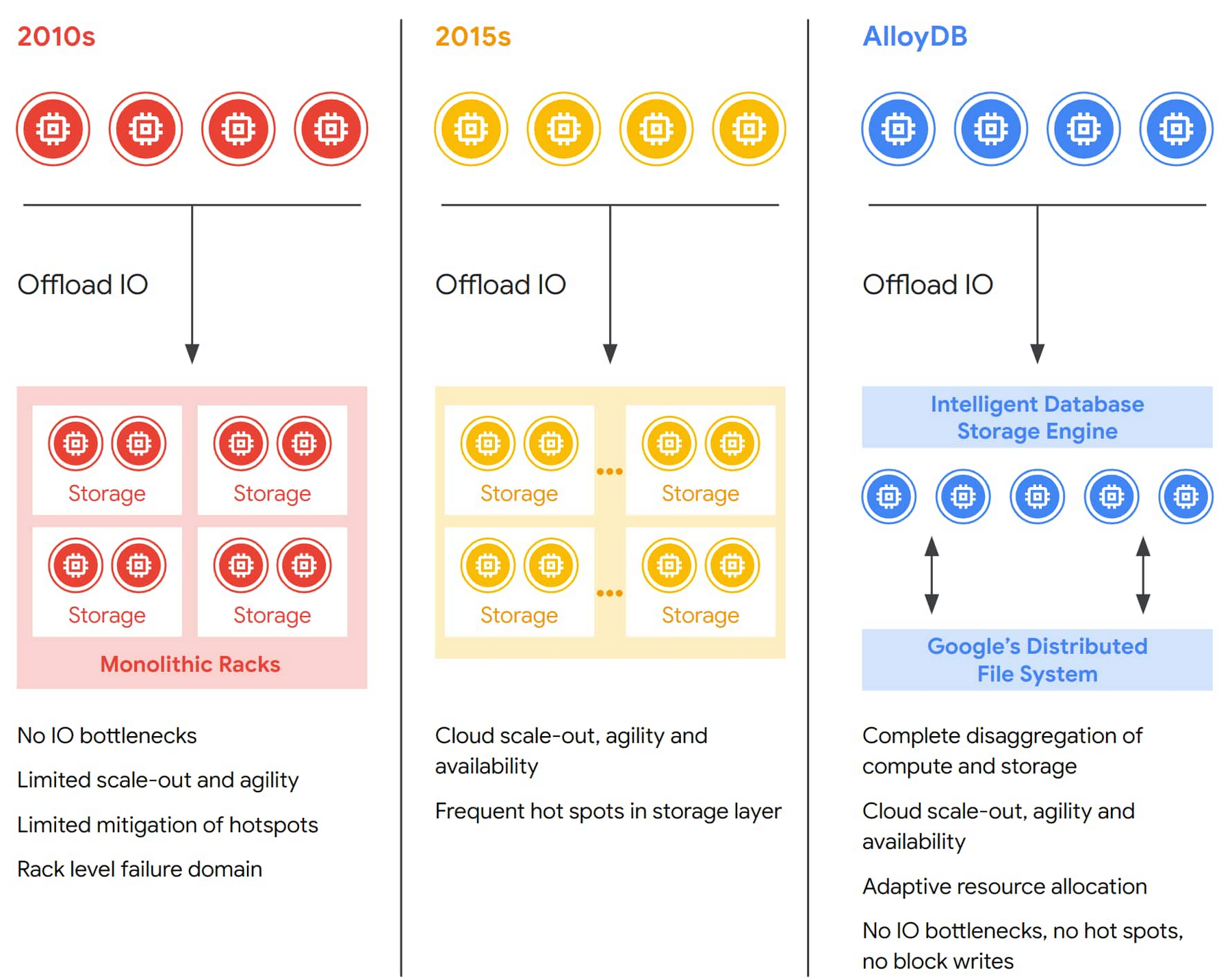
Disaggregation of compute and storage within databases has evolved over the years. In early approaches, though storage could be sized independently from the compute layer, the overall system was still fairly static and lacked elasticity. By building on cloud-scale storage solutions, next-generation database systems improved on storage elasticity, but still suffered from either oversized storage clusters or a lack of IO capacity in case of workload spikes (hotspots).
With AlloyDB, the fully disaggregated architecture even at the storage layer allows it to work as an elastic, distributed cluster that can dynamically adapt to changing workloads, adds failure tolerance, increases availability, and enables cost-efficient read pools that scale read throughput horizontally. Multiple layers of caching throughout the stack, which are automatically tiered based on workload patterns, give developers increased performance while retaining the scale, economics, and availability of cloud-native storage. Combined, these aspects of AlloyDB architecture mark the next step of the evolution of disaggregation in databases and contribute to AlloyDB’s exceptional performance and availability.
The trouble with monolithic design
Traditionally, PostgreSQL databases employ a monolithic design, co-locating storage and compute resources in a single machine. In the event that you need more storage capacity or compute performance, you scale the system up by moving to a more powerful server, or adding more disks. When scaling up further is no longer possible or cost-effective (more powerful servers get increasingly expensive), you can use replication to create multiple, read-only copies of the database.
That approach has its limitations: Failover times are longer and less predictable, as they are dependent on database load and configuration. Moreover, read replicas have their own, lagging, and expensive copy of the database, making it more difficult to scale read capacity and manage replica lag. As a result, the elasticity of a monolithic database with tightly coupled storage and compute is limited. By disaggregating compute and storage, AlloyDB is able to overcome many of these limitations.
To further increase the scalability of the database layer beyond the capacity of a single (virtual) machine, AlloyDB allows you to add multiple read-only replica instances to support the primary database instance in read-only query processing without requiring additional database copies: Since the storage layer is distributed across zones and accessible from any server, you can quickly build read replica instances that are inexpensive (since each replica instance doesn’t require its own storage) and up-to-date. Fundamentally, these design principles allow us to create a platform that moves functionality out of the primary database instance monolith, and convert it into a cloud-native implementation that provides better performance, scalability, availability, and manageability.
AlloyDB design overview
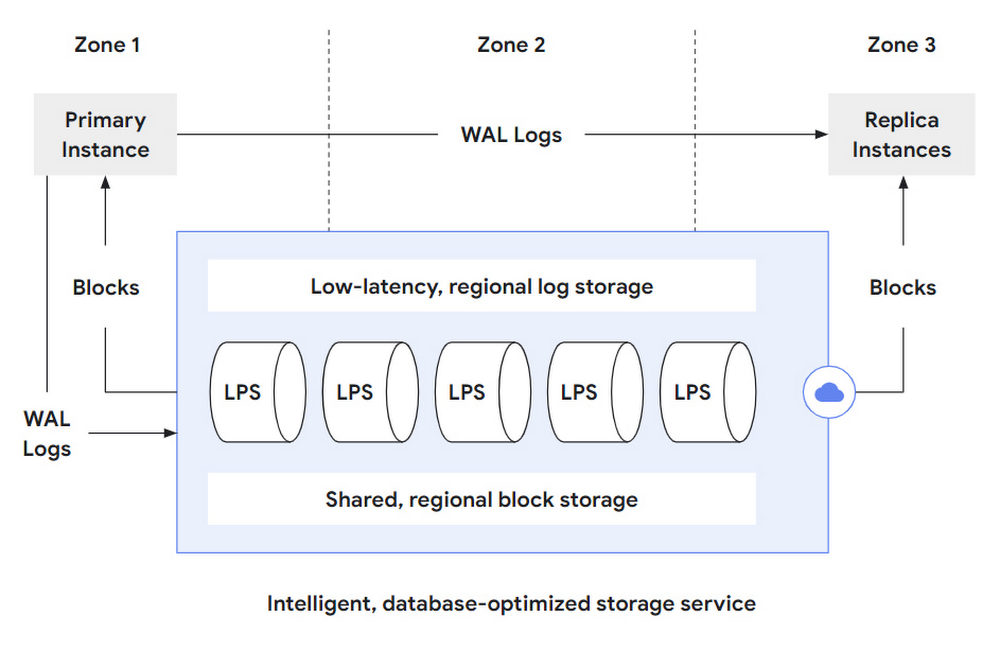
The AlloyDB storage layer is a distributed system comprised of three major parts:
A low-latency, regional log storage service for very fast write-ahead log (WAL) writing
A log processing service (LPS) that processes these WAL records and produces “materialized” database blocks
Failure-tolerant, sharded, regional block storage that ensures durability even in case of zonal storage failures.
Figure 2 below shows a high-level conceptual overview of the log processing service and its integration with the PostgreSQL database layer and durable storage. The primary database instance (of which there is only one) persists WAL log entries, reflecting database modification operations (such as INSERT/DELETE/UPDATE) to the low-latency regional log store. From there, the log processing service (LPS) consumes these WAL records for further, asynchronous processing. Because the log processing service is fully aware of the semantics of the PostgreSQL WAL records and the PostgreSQL storage format, it can continuously replay the modification operations described by these WAL records. Each log record is processed only once in each zone, resulting in an up-to-data database block that is materialized to a sharded, regional storage system. From there, these blocks can then either be served back to the primary database instance (in the case of a restart or simply when a block falls out of cache) or to any number of replica instances that might be in any of the zones within the region where the storage service operates.
To keep the local caches of the replica instances up-to-date, AlloyDB also streams WAL records from the primary to the replica instances to notify them about recent changes. Without this information about changing blocks, cached blocks in the replica instances could become arbitrarily stale.
What are the key benefits of this approach? Let's consider some of the implications of this design in further detail:
Full compute/storage disaggregation even within the storage layer. LPS can scale out based on workload patterns, and transparently add more compute resources to process logs when needed to avoid hotspots. Since the log processors are purely compute-attached to a shared regional storage, they can flexibly scale out/in without needing to copy any data.
Storage-layer replication: By synchronously replicating all blocks across multiple zones, the storage layer automatically protects the system from zonal failures without any impact on or modifications to the database layer.
Efficient IO paths / no full-page writes: For update operations, the compute layer only communicates the WAL records to the storage layer, which is continuously replaying them. In this design, there is no need to checkpoint the database layer, or any reason to send complete database blocks to the storage layer (e.g., to safeguard against the torn pages problem). This allows the database layer to focus on query processing tasks, and allows the network between the database and storage layer to be used efficiently.
Low-latency WAL writing: The use of low-latency, regional log storage allows the system to quickly flush WAL log records in case of a transaction commit operation. As a result, transaction commit is a very fast operation and the system achieves high transaction throughput even in times of peak load.
Fast creation of read replica instances: Since the storage service can serve any block in any zone, any number of read replica instances from the database layer can attach to the storage service and process queries without needing a “private” copy of the database. The creation of a read replica instance is very fast as data can be incrementally loaded from the storage layer on demand — there’s no need to stream a complete copy of the database to a replica instance before starting query processing.
Fast restart recovery: Since the log processing service continuously replays WAL log records during online operations, the amount of write-ahead log that needs to be processed during restart recovery is minimal. As a consequence, system restarts are accelerated significantly (because WAL-related recovery work is kept to a minimum).
Storage-layer backups: Backup operations are completely handled by the storage service, and do not impact the performance and resources of the database layer.
Life of a write operation
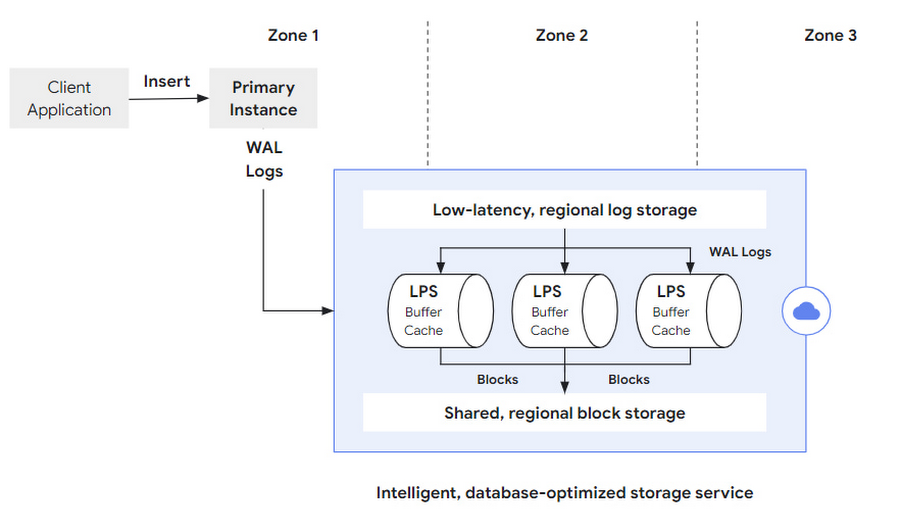
Let’s further explore the design of the system by tracing the path of a database modification operation (Figure 3). It begins with the client that issues, for example, a SQL INSERT statement over the client’s TCP connection to the primary instance on the database layer. The primary instance processes the statement (updating its data and index structures in-memory) and prepares a WAL log record that captures the semantics of the update operation. Upon transaction commit, this log record is first synchronously saved to the low-latency regional log storage, and then asynchronously picked up by the log processing service in the next step.
Note that the storage layer is intentionally decomposed into separate components, optimizing for the separate tasks performed by the storage layer — log storage, log processing, and block storage. To reduce transaction commit latency, it is important to durably store the log records as fast as possible and achieve transaction durability. Because WAL log writing is an append-only operation, AlloyDB specifically optimizes for this use case with a high-performance, low-latency storage solution. In the second phase, WAL log records need to be processed by applying them to the previous version of the block they refer to. To do this, the storage layer’s LPS subsystem performs random block lookups and applies PostgreSQL’s redo-processing logic in a high performance and scalable way.
To ensure regional durability for the materialized blocks, multiple instances of the log processing service (LPS) run in each of the zones of the region. Every log record has to be processed and the resulting buffers need to be durably stored in a sharded, regional block storage (see below) to eventually remove the log record from regional log storage.
Life of a read operation
Similarly, reads begin with a SQL query that’s sent to a database server; this can either be the primary instance or one of the (potentially many) replica instances used for read-only query processing (both of these paths are visualized in Figure 4). The database server performs the same query-parsing, planning and processing as a conventional PostgreSQL system. If all the required blocks are present in its memory-resident buffer cache, there’s no need for the database to interact with the storage layer at all. To allow for very fast query processing, even in cases where the working set does not fit into the buffer cache, AlloyDB integrates an ultra-fast block cache directly into the database layer. This cache extends the capacity of the buffer cache significantly, thereby further accelerating the system in those cases.
However, if a block is missing in both of the caches, a corresponding block fetch request is sent to the storage layer. Apart from the block number to retrieve, this request specifies a log-sequence number (LSN) at which to read the data. The use of a specific LSN here ensures that the database server always sees a consistent state during query processing. This is particularly important when evicting blocks from the PostgreSQL buffer cache and subsequently reloading them, or when traversing complex, multi-block index structures like B-trees that might be (structurally) modified concurrently.
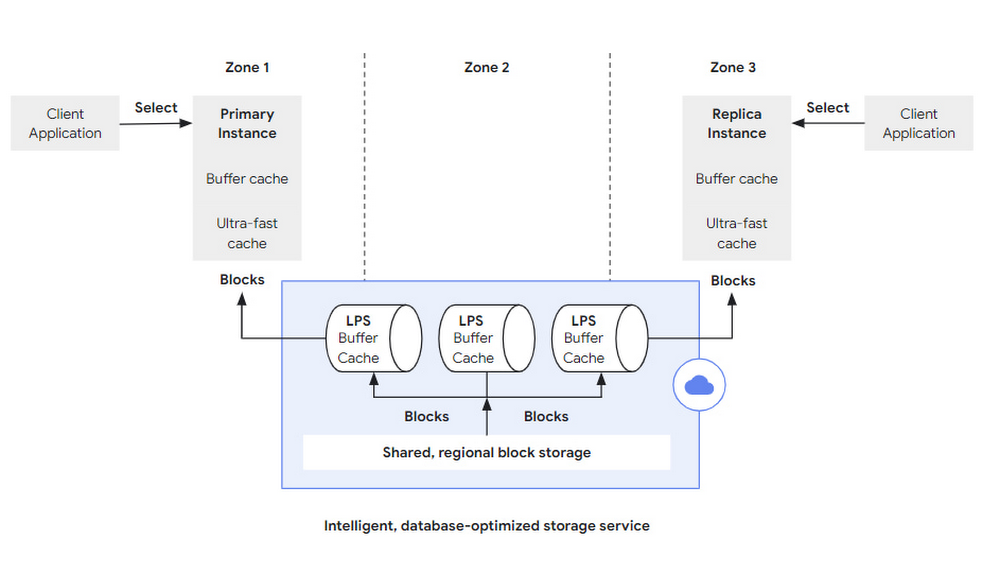
On the storage layer, the log processing service is also responsible for serving the block fetch requests. Every LPS has its own instance of the PostgreSQL buffer cache — if the requested block is already in the LPS buffer cache, it can be returned to the database layer immediately without any I/O operation. If the requested block is not present in the cache, the LPS retrieves the block from the sharded, regional storage and sends it back to the database layer. The log processing service must also do some bookkeeping to track which blocks have log records that have not been processed. When a request for such a block arrives (an event we expect to be rare since the database layer only requests blocks that have been evicted from cache and then referenced, and the LPS consistently consume pending WAL to produce the latest view for every database block), the read request must be stalled until redo processing for that log record has been completed. Consequently, to avoid such stalls, it is very important that WAL processing on the LPS layer is efficient and scalable, so it can handle even the most demanding enterprise workloads. We discuss this in more detail in the next section.
Storage layer elasticity
So far, we’ve discussed the log processing service as a single process (in each zone). For demanding enterprise workloads though, having only a single LPS process potentially creates a scalability problem, as the LPS both needs to continuously apply WAL records as well as serve read requests from both primary and multiple replica instances.
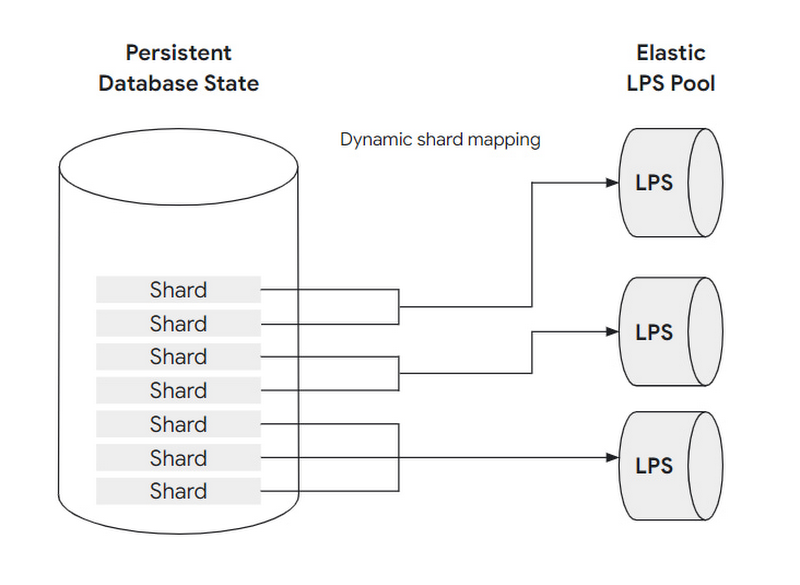
To address this problem, database persistence is horizontally partitioned into groups of blocks called shards. Both shards and LPS resources scale horizontally and independently.
Every shard is assigned to exactly one LPS at any time, but each LPS can handle multiple shards. The shard-to-LPS mapping is dynamic, allowing the storage layer to elastically respond to increased access patterns by scaling the number of LPS resources, and reassigning shards. This not only allows the storage layer to scale throughput, but to also avoid hot spots.
Let's consider two examples here: In the first case, the overall system load increases, and virtually all shards receive more requests than before. In this case, the storage layer can increase the number of LPS instances, e.g. by doubling them. The newly created log processing server instances then offload the existing instances by taking over some of their shards. As this shard re-assignment does not involve any data copying or other expensive operations, it is extremely fast and invisible to the database layer.
Another example where shard reassignment is very helpful is a case where a small set of shards suddenly become very popular in the system (e.g. information about a certain product family stored in the database is requested frequently after a super-bowl commercial). Again, the storage layer can dynamically react - in the most extreme case by assigning each of the shards observing the workload spike to a dedicated LPS instance that is exclusively handling the shard's load. Consequently, with re-sharding and LPS elasticity in place, the system can provide high performance and throughput even in case of workload spikes, and also reduces its resource footprint if the workload reduces again. For both the database layer and the end user, this dynamic resizing and storage layer elasticity is completely automatic and requires no user actions.
Storage layer replication and recovery
The goal of AlloyDB is to provide data durability and high system availability even in case of zonal failures, e.g., in case of a power outage or a fire in a data center. To this end, the storage layer of every AlloyDB instance is distributed across three zones. Each zone has a complete copy of the database state, which is continuously updated by applying WAL records from the low-latency, regional log storage system discussed above.
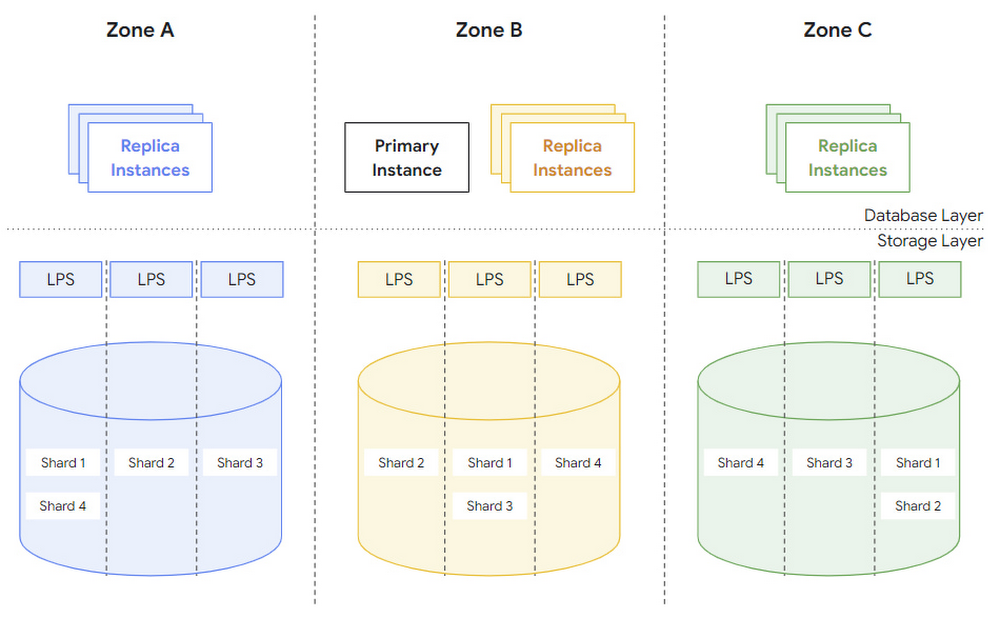
Figure 6 shows the full system across three zones with multiple log-processing servers (LPS) and potentially multiple shards per server. Note that a copy of each shard is available in each zone.
With this architecture, block lookup operations can be performed with minimal overhead. Each zone has its own copy of the complete database state, so block lookup operations by the database layer don't need to cross zonal boundaries. Moreover, the storage layer continuously applies WAL records in all zones and the database layer provides the target version LSN for each block it requests (see above), so there is no need to establish a read quorum during lookup operations.
In the event that an entire zone becomes unavailable, the storage layer can replace the failed zone by integrating a new zone from the same region, and populating it with a copy of the complete database state. As visualized in Figure 6, this is done by making sure that a copy of each shard is available in the new zone, and by running the log processing service to continuously update the shards with the latest WAL records. As such, the storage layer internally handles all zone failovers without any orchestration or auxiliary activities of the database layer.
Besides these built-in capabilities of the storage layer, AlloyDB also integrates both manual and automatically scheduled backup operations to safeguard against application-level or operator failures (like accidentally dropping a table).
What AlloyDB’s intelligent storage can do for you
To summarize, AlloyDB for PostgreSQL disaggregates the compute and storage layers of the database, and offloads many database operations to the storage layer through the use of the log processing system. The fully disaggregated architecture even at the storage layer allows it to work as an elastic, distributed cluster that can dynamically adapt to changing workloads, adds failure tolerance, increases availability, and enables cost efficient read pools that scale read throughput linearly. Offloading also allows for much higher write throughput for the primary instance as it can fully focus on query processing and delegate maintenance tasks to the storage layer. Combined, these aspects of AlloyDB’s intelligent, database-aware storage layer contribute to the exceptional performance and availability of AlloyDB.
To try AlloyDB out for yourself, visit cloud.google.com/alloydb. And be sure to stay tuned for our next post on AlloyDB’s Columnar Engine.
The AlloyDB technical innovations described in this and subsequent posts would not have been possible without the exceptional contributions of our engineering team.
August 16th update: Added clarifications to point out that WAL log records are replayed continuously, and typically only applied once.



