AlloyDB under the hood: Replication gets closer to real-time

Anthony Hsu
Software Engineer
Emir Okan
Senior Product Manager
Synchronizing data at the speed of light
AlloyDB is a fully-managed, PostgreSQL-compatible database for demanding transactional workloads. It expands PostgreSQL's scalability and adds a columnar engine for analytical queries that enables you to derive real time insights from your operational data. AlloyDB’s performance improvements allows you to scale up your read and write performance linearly in a single machine, while read pools offer horizontal scaling for reads, supporting up to 20 read nodes.
Replication lag is a major challenge you face when trying to leverage PostgreSQL read replicas. Some workloads aren’t particularly sensitive to lag — for example, a metadata catalog for a streaming service doesn’t change so often that the lag would matter. But other workloads, like order management, can't tolerate a large replication lag, because they might display incorrect product availability and other errors. Applications of this nature are forced to run their read queries on the primary instance, and Postgres being bound to a single primary starts to impose a practical limit to its scalability.
AlloyDB comes with several capabilities designed to increase PostgreSQL read capacity. AlloyDB’s read pools provide a convenient way to scale out reads horizontally behind a single endpoint. By architecting an efficient way that reduces the lag, read pools allow even latency sensitive workloads to offload their read queries, providing horizontal scalability to 1000+ vCPUs of computing capacity. AlloyDB’s intelligent storage system backs all instances in a cluster, allowing new read nodes to be spun up very quickly. Low lag read nodes also enable adding new operational analytics capabilities to your operational database without being limited by the size of your primary.
In this blog post, we discuss the improvements we've made to AlloyDB to keep replication lag low. With these improvements, AlloyDB's regional replicas deliver more than 25x lower replication lag than standard PostgreSQL for high throughput transactional workloads, and bounded replication lag on workloads that previously suffered from unbounded (ever-increasing) replication lag.
Background on PostgreSQL’s physical replication
Let’s start with a quick refresher on Postgres’s streaming physical replication.
In standard Postgres, read-write transactions on the primary generate log records that capture the changes being made to the database. These are written to disk as the Write-Ahead Log (WAL). If read replicas are configured, then WAL sender processes send the logs over the network to the replicas. On each replica, a WAL receiver process receives the logs, and a WAL replayer process continuously applies the changes to the database. Unlike regular query processing, the replay process runs single threaded, serially replaying each log.
Here is a diagram of what this looks like end-to-end:
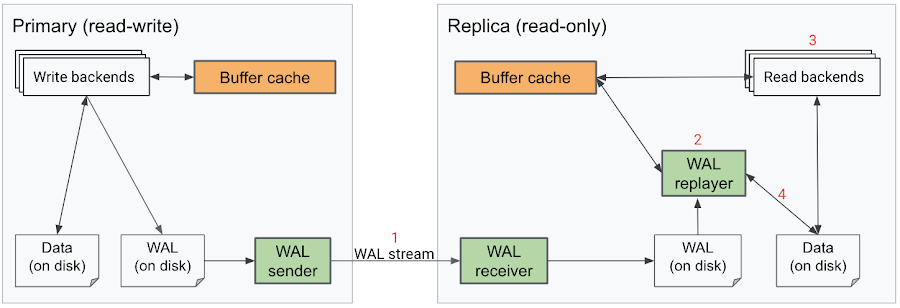
Replication lag (“replay_lag”) measures this whole process end to end, starting from the point when the change made by a transaction (“WAL”) is written to the disk (“flushed”) on the primary, until this change is applied (“replayed”) in the replica. Several steps of this journey have inefficiencies that result in higher replication lag:
Full replication: Since the replica needs to have all the same updates as the primary, all changes in the primary across all databases need to be streamed to the replica and replayed.
Single threaded WAL replay: The single threaded design of WAL replay puts the replica at a disadvantage over the primary. Under a heavy write load, the primary may generate WAL faster than the replica can apply them, causing the replication lag to grow.
Competition with read backends: Heavy read traffic on the replica may also allocate CPU resources from the WAL replayer to read backends, decreasing the ability of the replica to catch up.
I/O bottlenecks during replay: Similarly, replay activity and the read traffic both compete for access to a finite resource: I/O capacity
We’ve innovated across AlloyDB’s architecture to mitigate each of these inefficiencies and ensure fast replication under extreme loads on both the primary and the read pools.
Replication lag improvements in AlloyDB
AlloyDB’s intelligent storage engine, automatic tiered caching, and specific improvements in the replay processes address the above mentioned challenges. AlloyDB’s replay architecture looks similar to standard Postgres’s, but is critically different in ways to make a material difference in the replication lag.
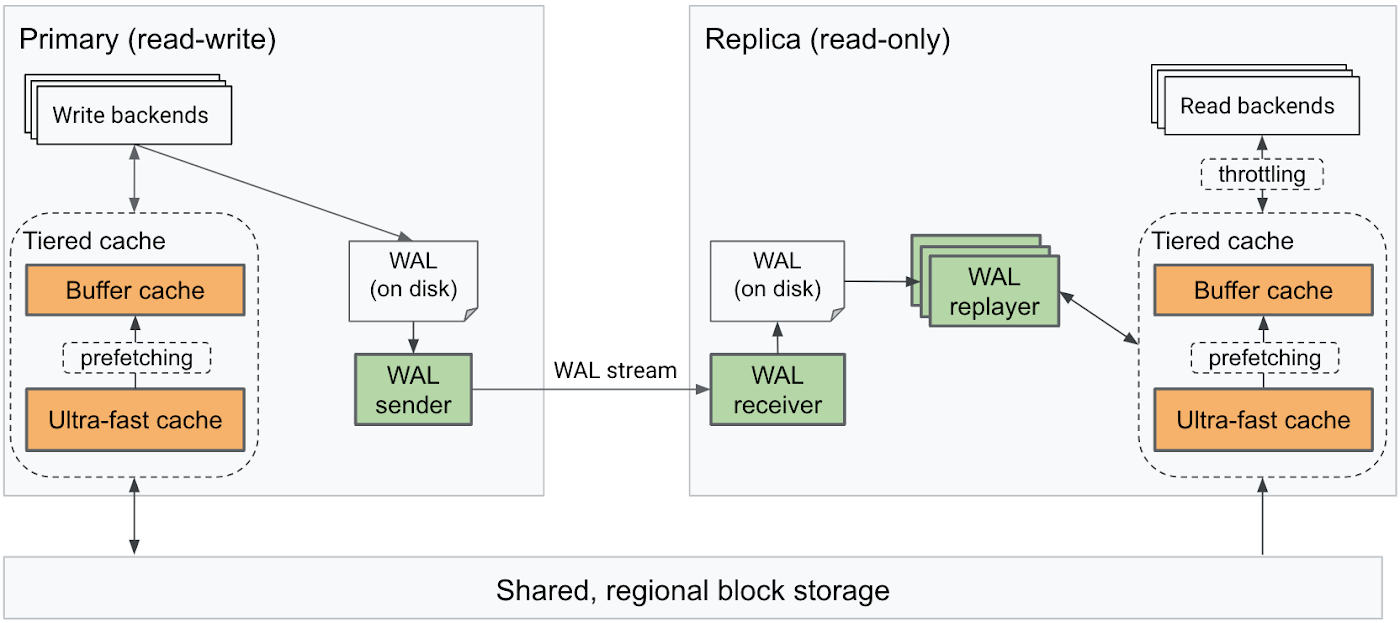
First, we leverage our intelligent storage engine to skip replay of some log records, reducing the replay load. All nodes in an AlloyDB cluster share the same distributed block storage within the Google Cloud region. Since regional storage can be used to serve the up-to-date version of blocks as needed, read nodes only need to focus on keeping the blocks in their caches up-to-date.
Second, we greatly improve the replay speed by parallelizing log replay in the read node. We deploy multiple WAL replayer processes, and intelligently distribute log records to each of them so that multiple workers can replay simultaneously without any conflicts. This allows read nodes to quickly process the huge stream of log records that the primary instance may be sending.
Third, we prioritize resource allocation to the WAL replayer processes, so that simultaneous read query processing on the read node has minimal impact on the replication lag. If the replication lag grows too large, we throttle the read queries on the read node, and thereby ensure that read queries don’t hog CPU time and I/O bandwidth by reading a large number of data blocks from the caches.
Lastly, we intelligently prefetch blocks to avoid I/O bottlenecks by leveraging the numerous improvements we’ve built in our automatic tiered caching. Our tiered cache mechanism automatically moves blocks between the buffer, and ultra fast caches so that the blocks that we anticipate WAL replayer will modify are in a warmer state.
These techniques work in concert to ensure that the data on the read node is as fresh as the primary for a very large range of workloads. However, as a database user, there are some scenarios you should watch out for to keep the replication lag low. In particular, due to the MVCC execution model of Postgres, certain long-running user queries on the read node will prevent the replay process of the read node from making progress until queries finish, leading to occasional spikes in the replication lag. The read node will catch up soon after these transactions complete.
Performance results
AlloyDB customers are already benefiting from the reduced replication lag and the scale out capabilities it unlocks for their applications. Character.ai, a conversational AI service, provides consumers with their own deeply personalized superintelligence.
“Scaling a rapidly growing consumer product constantly presents new challenges. We used to hit a wall with PostgreSQL's limits even on the largest database instances, resulting in CPU bottlenecks, latency spikes, lock contentions and unbounded replication lag in read replicas. After migrating to AlloyDB, we've been able to confidently offload our read traffic to read pools, and even with a significant increase in user engagement, we have eliminated these bottlenecks while serving twice the query volume at half the query latency. With AlloyDB's full PostgreSQL compatibility and low-lag read pools, we have a robust foundation to scale towards 1 billion daily active users." - James Groeneveld, Research Engineer, Character.ai
Let’s see how AlloyDB compares with standard Postgres 14 under two demanding scenarios: 1) high write throughput and 2) simultaneous high write throughput on the primary and intense read load on the read node.
For these evaluations, we ran TPC-C-like and pgbench workloads and measured the replication lag along with the transaction throughput during a one-hour run. We used 16 vCPU instances and tested with (1) a 100% cached dataset (entirely in Postgres shared buffers) and (2) 30% cached dataset (only 30% of data fit in shared buffers). We ran each experiment 5 times and used the average in our graphs below.
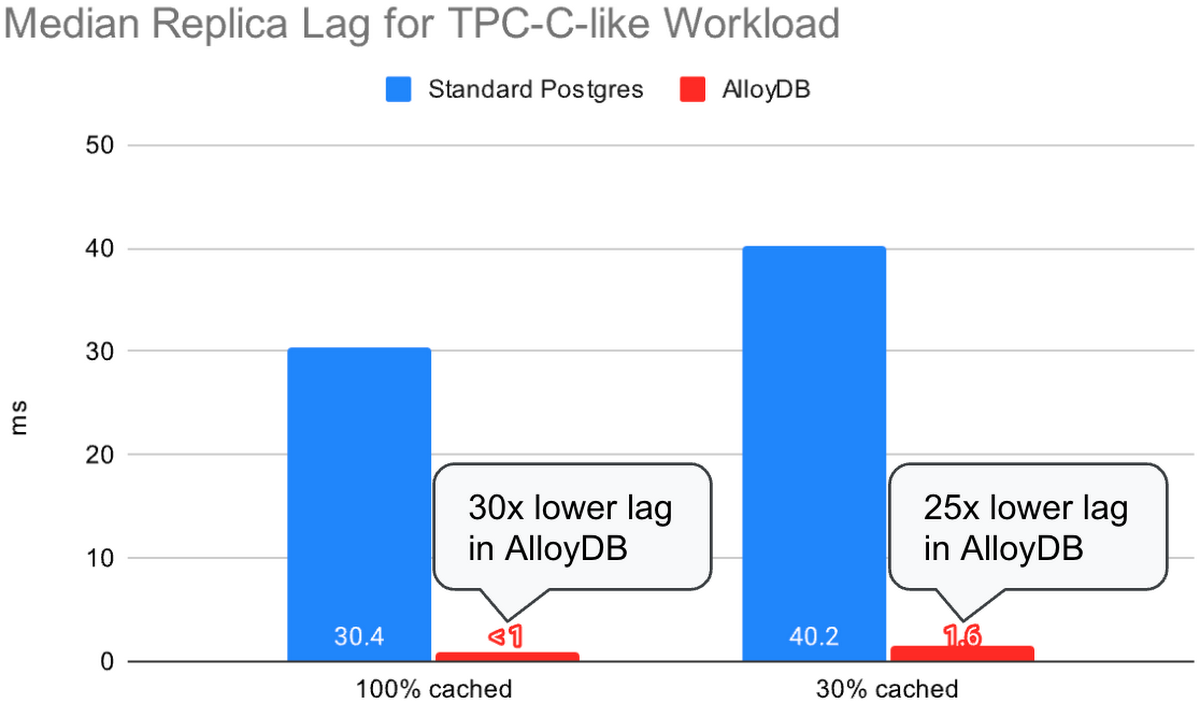
For the first experiment, we ran a TPC-C-like workload on the primary while keeping the replica idle (no read queries running on it). We adjusted the number of clients to keep the transactions per minute (TPM) about the same for both the standard Postgres and AlloyDB runs. We did this to measure the improvement in replication lag when moving from standard Postgres to AlloyDB while keeping the workload the same. For the 100% cached test, we adjusted the number of clients to achieve a TPM of about 350k for both the standard Postgres and AlloyDB. For the 30% cached test, we used a TPM of about 115k.
For the same workload (TPM), AlloyDB achieved a median replication lag more than 25 times lower than standard Postgres.
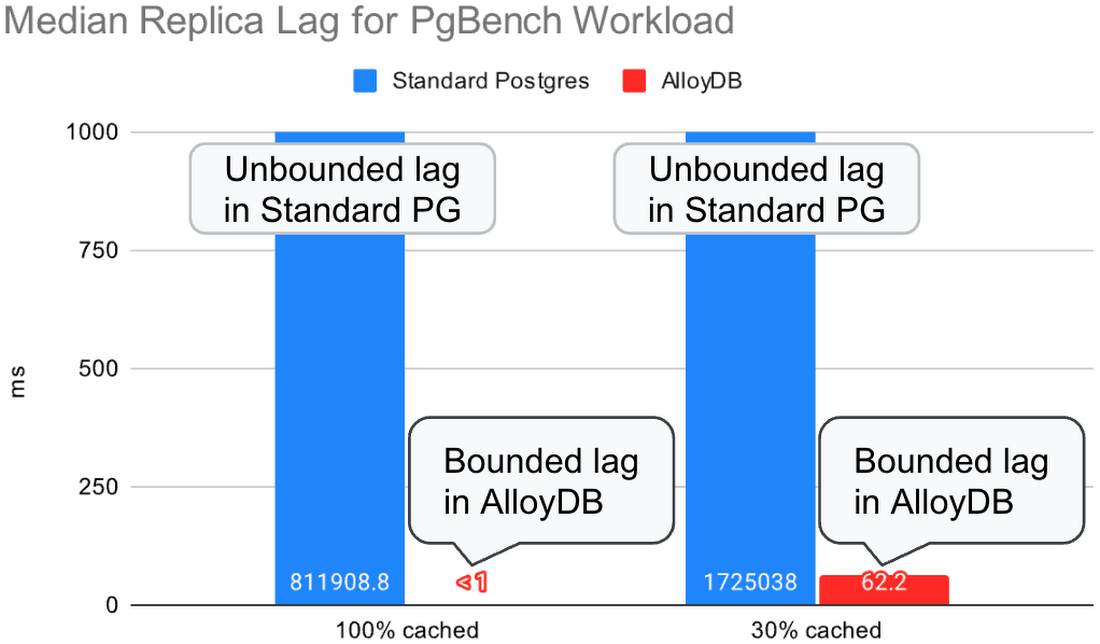
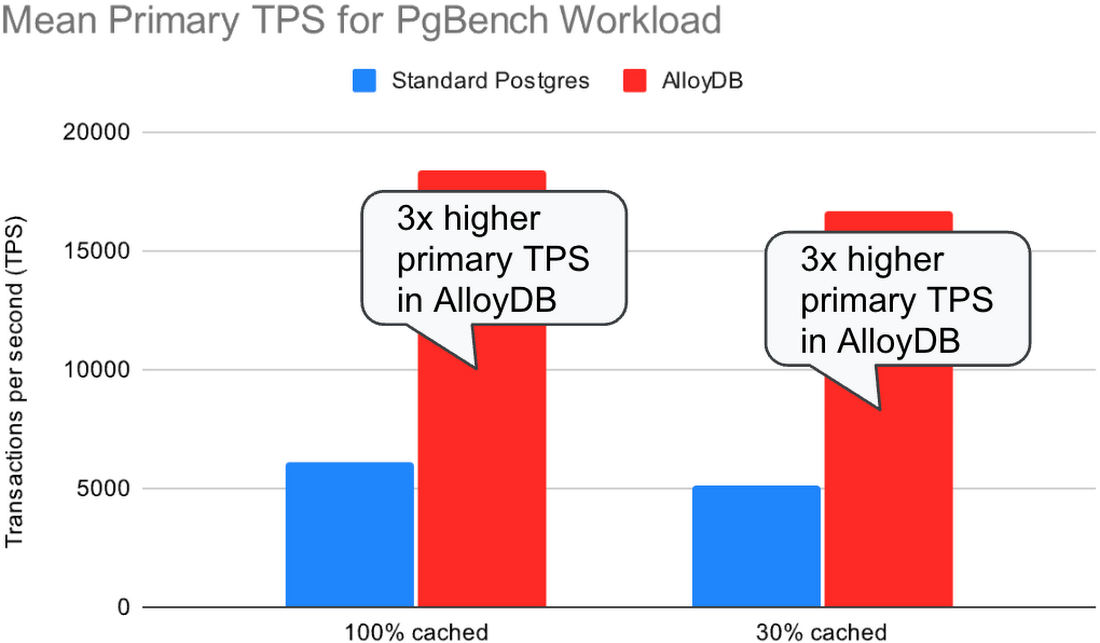
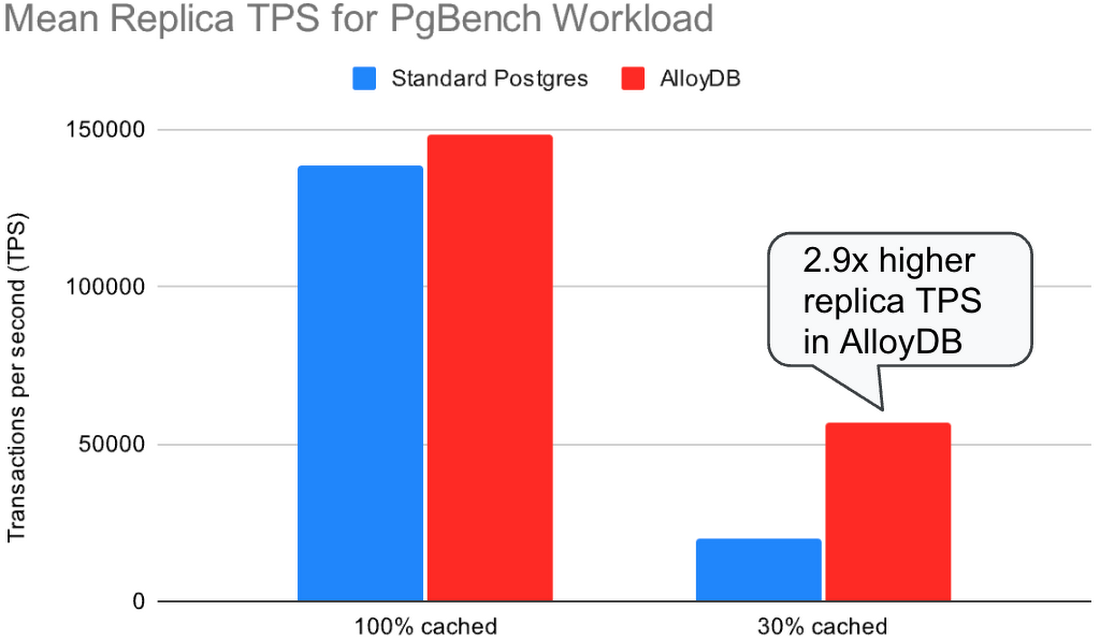
In our second experiment, we ran a TPC-B-like pgbench workload on the primary while concurrently running a select-only pgbench workload on the replica. The read queries on the replica compete for the CPU and disk resources with the replay process. We ran with hot_standby_feedback=on to avoid query cancellations and stalled log replay on the replica due to conflicting log records. In this experiment, we used the same number of clients (128 primary clients + 128 replica clients) for both standard Postgres and AlloyDB and let them execute queries as fast as they could.
In standard Postgres, the replica cannot keep up with the log stream while concurrently processing the read queries, and the replication lag grows without bound. The increasing replication lag also decreases throughput on the primary due to table and index bloat – as vacuum cannot remove the old row versions the lagging replica may still need for its read queries.
In AlloyDB, the replica is able to keep up with the log stream while still processing a similar amount of concurrent read queries. The replication lag remains bounded while the primary processes 3 times as many transactions per second as in standard Postgres.
Conclusion
Many PostgreSQL-based applications can’t tolerate high replication lag and may not be able to make use of replicas, putting a limit to their scalability. Improvements in AlloyDB deliver near real-time latency in read pools, even in cases where standard Postgres can have unbounded replication lag. In our AlloyDB benchmarks, we’ve seen median replica lags of under 100 ms while maintaining a primary TPS many times that of standard Postgres.
Our low lag replicas unlock new levels of horizontal scalability by allowing even some of the most latency-sensitive workloads to offload much of their read queries to read pools, providing horizontal scalability to 1000+ vCPUs of computing capacity.
To learn more, check out the Google Cloud Next breakout session DBS210, PostgreSQL the way only Google can deliver it: A deep dive into AlloyDB. To try out AlloyDB for yourself, visit cloud.google.com/alloydb. New customers also get $300 in free credits to run, test, and deploy workloads. Sign up to try AlloyDB for free.
