Benchmarking for AlloyDB and how to do it
Gleb Otochkin
Cloud Advocate, Databases, Google Cloud
From time to time, I read and participate in conversations about performance tests comparing AlloyDB with different Postgres deployments on premises and in other cloud environments. In some cases, it sounds similar to the "Sensible Fiesta Test" by Jeremy Clarson in the 12th season of Top Gear. When asked the question "Can I afford it?" He stated that if you had £11,000, you certainly could, but if you had only 40p, then probably not. All other tests and results in that challenge (maybe all of them) were equally useless.
Why did that episode pop up in my mind?
Every test should have some goals and metrics to quantify the result and lead to conclusions and decisions. Let’s imagine a farmer testing the usability of a car by checking if it can carry a sack of potatoes for 40 miles. A small car like Fiat 500 will do the same job as a Ford F150 track and be much cheaper. Does that mean we should ditch all trucks and replace them with small city cars? Of course not.
But why are we testing the performance of a beefy 4 CPU 32GB Postgres using pgbench with a default scale 1 dataset, which is about 24 MB in size? Then we do the same test on a comparable AlloyDB and make a conclusion – both can handle a 24 MB dataset without any noticeable difference in performance. Is it the right conclusion? Absolutely. Is it helpful and valuable? Probably not too much, except of course in the case when you want to figure out if you can use a 4 CPU 32 GB server for a 24 MB dataset.
Is there a right approach for benchmark testing?
So what is the right testing approach? Great question and the answer, as you can guess, of course - “It depends …”. The best possible performance test is when you use real data and real workload. But it is not always achievable and it is possible on the initial stage you want to compare the performance of one database deployment to another. There is no universal solution but some approaches make sense. Let’s take one of them. Here are the high level stages:
Define the goals. Do you want to know if the target environment is able to sustain the same or bigger max load than the current implementation? Or your goal is to achieve the certain workload parameters on a system with minimum CPU and memory?
Prepare requirements for the benchmark tests based on your goal and workload on your current system. The workload can be OLTP, Analytical or both. It will help you with future evaluations.
Identify key metrics to measure output and assess test success. For example it can include transactions per second and conditions like max latency.
Choose the right tool for benchmarks. It might not be the ideal but it has to serve the purpose and provide objective results. Even standard pgbench might do the job if used right. But it depends on the goals and what you want to measure.
Choose the baseline system parameters such as CPU, memory and storage. It can be your database server on premises or a managed service platform. Let’s call it a system to not limit it to a single server installation.
Make sure the client machine(s) with the benchmark tool has the same configuration and capacity on the baseline and the target environments and the network topology is similar or it will be hard to compare the results since the network overhead can be significant for some types of tests.
Create the dataset with appropriate size depending on the system parameters.
Run the tests gradually increasing the load on the baseline system until you reach your max key metrics. For example max throughput or max throughput with latency no more than defined.
The duration of the test should be sufficient to get reliable and repeatable results. Having a test running for 5 min is not enough since some short term factors can skew the results.
Repeat the benchmark several times to get the reliable results.
Move to the system you want to compare and run the same sequence there.
The condition for the testing should be close to the original for the baseline and to the planned implementations for proper comparison. I will talk about conditions and impact later but I would emphasize again the importance of the right approach to the testing.
Inside a database instance
Before going forward let’s have a bird view to data processing in a database. Without going too deep in general the life of data in a page or block for a database starts and ends in the memory. It is a bit simplified approach but in general you need to copy the block to the memory to make any changes. And in relational databases with enabled transaction log all changes are written to the log before they are fixed in the data block. Then the block version with the new data eventually makes its way back to the disk where it replaces the old version of the block. But it doesn’t mean that all the block versions disappeared from the memory. The database instance has a cache where the recently used blocks are stored to reduce unnecessary IO. The size and configuration of the cache depends on the database engine but if we talk about standard postgres we have the buffer cache in the shared memory and filesystem cache behind it.
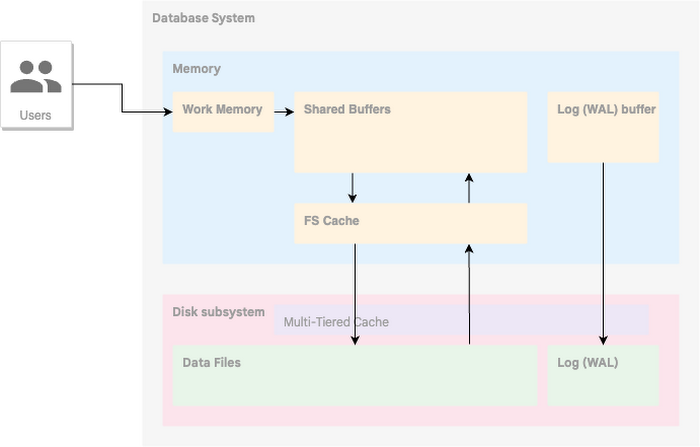
The AlloyDB cache is a bit more complex due to different concepts behind the storage layer but if a block is in the shared buffer it is going to be accessible by all the processes.
So how is your client session working with the data when it updates a record? The server process for your session gets a copy of an actual version of the block in the buffer, logs the changes to the transaction log, makes necessary changes in the block and marks changes completed. And if we look outside to the work with the cache it is primarily CPU activity.
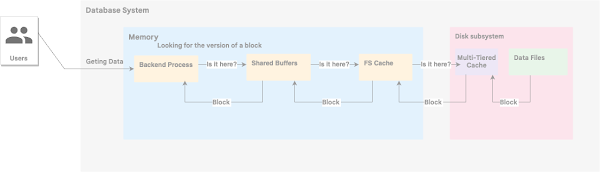
I am not going to sink to a deep dive about internals for AlloyDB database engine, it is not the scope of the blog.If you want to know more about it you can read an excellent blog written by Ravi Murthy about the storage layer for AlloyDB. This chapter aims to show how the settings of a benchmark test can influence the results and potentially make them not fully relevant to the goals of the benchmark test.
Factors and settings during the tests
Let’s start with the dataset size used for testing. The standard pgbench with scale factor 1 produces a dataset roughly 24 MB in size. If your buffer is GB and the filesystem cache is the same size then your data will be almost all the time in the cache. So, basically you test the CPU and kernel on one system versus the other. Will it be useful? Does it represent the planned dataset on your database? It is quite possible then if you have only a 24 MB database you might not need AlloyDB. I would recommend using a scale factor producing a dataset comparable with your current database or projected to the future and it should probably be bigger than effective cache on the instance. For example if you have 16GB memory on the system the scale factor 2000 (parameter “-s 2000”) will create a 34GB dataset which might be sufficient for comprehensive testing not only the CPU but also the storage subsystem.
Speaking about characteristics of your baseline system, you probably need to make it similar to the existing or planned production system in terms of CPU, memory and storage layer. Then you will be able to understand the max load it can sustain and benchmark AlloyDB against it. But I would not try to test minimal basic configuration with 2 vCPU. If we return to the car analogy we know that a heavy truck or semi consumes more fuel just to carry itself because they are more complex and have to have a big heavy frame for example to be able to handle tons of load. The same might be applied to our case. AlloyDB internal services such as multi-tiered cache service, observability agents, health checks and others use CPU cycles and memory to run. So, in a small 2 vCPU instance that overhead might be noticeable. Also if your workload fits to a 2 CPU 16Gb instance you might consider other services like Cloud SQL but keep in mind AlloyDB other features such as vacuum management and intelligent buffering. Network is important too. If your plans are to place the application in the same region connected using AlloyDB Auth Proxy then use the same configuration for the test. If your client VM with the benchmark tool is in another region the network overhead can have a significant impact on the test results. Of course such configuration makes total sense when your future architecture represents such a layout. For example, if you plan to use an application on-prem working with AlloyDB in the cloud.
Speaking about read pools, we might also run some tests for read only load using for example parameter -S for pgbench on the primary instance or on the replica(s) on standalone system and read pools on AlloyDB. It might give you a better picture for mixed workloads.Don’t forget to enable columnar engine on AlloyDB for analytical workload tests. Keep in mind that it is disabled by default. You can test it in automated mode or manually execute tasks to populate the columnar storage in the memory.
And you probably would like to use the index advisor, so it makes sense to enable it too. And a blog about the index advisor and how to work with it is coming, keep your eyes on the cloud blogs.
Summary
Let’s summarize here what I’ve noted and maybe make life easier to those who don’t have time to read through the entire article. To properly run a benchmark testing on the AlloyDB follow these steps.
Define the tests goals
Use right configuration for the baseline system, not minimal available
The client (benchmark) machine(s) should have similar configuration on baseline and target systems
Use sufficiently large dataset or scale factor
Maximize workload on the baseline system
Run each test sufficiently long to get reliable results
Repeat the tests at least 3 times
Use right topology in the cloud, network is important
Enable columnar engine for analytical or hybrid workloads
Enable index advisor if you plan to use it for optimization and use your real workloads for the tests
This is just one of the possible approaches to benchmarking AlloyDB, and depending on your requirements, it may only be the first step in performance evaluation. If you need more guidance on the approach or technical details of benchmark testing, I recommend reading two published guides produced by our AlloyDB team:
As I’ve mentioned earlier the best tests are those that use real workload and real data. Benchmarks cannot replace real testing, but they can give you some idea of what you can expect from the system in certain conditions. Happy testing, and don’t hesitate to reach your Google customer representative if you have any questions.

