What’s new with Splunk Dataflow template: Automatic log parsing, UDF support, and more
Roy Arsan
Applied AI Engineer, Anthropic
Last year, we released the Pub/Sub to Splunk Dataflow template to help customers easily and reliably export their high-volume Google Cloud logs and events into their Splunk Enterprise environment or their Splunk Cloud on Google Cloud (now in Google Cloud Marketplace). Since launch, we have seen great adoption across both enterprises and digital natives using the Pub/Sub to Splunk Dataflow to get insights from their Google Cloud data.
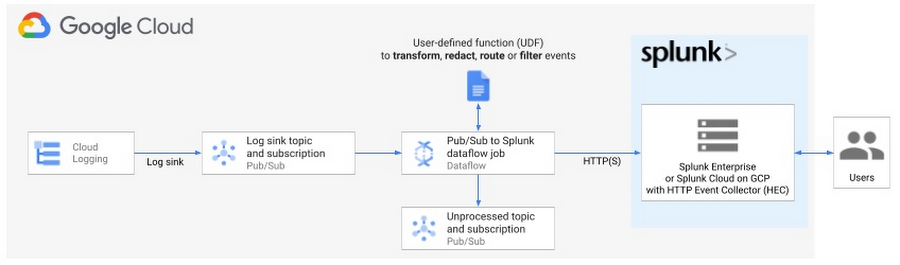
Pub/Sub to Splunk Dataflow template used to export Google Cloud logs into Splunk HTTP Event Collector (HEC)
We have been working with many of the users to identify and add new capabilities that not only addresses some of the feedback but also reduces the effort to integrate and customize the Splunk Dataflow template.
Here’s the list of feature updates which are covered in more detail below:
- Automatic logs parsing with improved compatibility with Splunk Add-on for GCP
- More extensibility with user-defined functions (UDFs) for custom transforms
- Reliability and fault tolerance enhancements
The theme behind these updates is to accelerate time to value (TTV) for customers by reducing both operational complexity on the Dataflow side and data wrangling (aka knowledge management) on the Splunk side.
We have a reliable deployment and testing framework in place and confidence that it [Splunk Dataflow pipeline] will scale to our demand. It’s probably the best kind of infrastructure, the one I don’t have to worry about.
Lead Cloud Security Engineer, Life Sciences company on Google Cloud
We want to help businesses spend less time on managing infrastructure and integrations with third-party applications, and more time analyzing their valuable Google Cloud data, be it for business analytics, IT or security operations. "We have a reliable deployment and testing framework in place and confidence that it will scale to our demand. It’s probably the best kind of infrastructure, the one I don’t have to worry about." says the lead Cloud Security Engineer of a major Life Sciences company that leverages Splunk Dataflow pipelines to export multi-TBs of logs per day to power their critical security operations.
To take advantage of all these features, make sure to update to the latest Splunk Dataflow template (gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk), or, at the time of this writing, version 2021-08-02-00_RC00 (gs://dataflow-templates/2021-08-02-00_RC00/Cloud_PubSub_to_Splunk) or newer.
More compatibility with Splunk
"All we have to decide is what to do with the time that is given us."
— Gandalf
For Splunk administrators and users, you now have more time to spend analyzing data, instead of parsing and extracting logs & fields.
Splunk Add-on for Google Cloud Platform
By default, Pub/Sub to Splunk Dataflow template forwards only the Pub/Sub message body, as opposed to the entire Pub/Sub message and its attributes. You can change that behavior by setting template parameter includePubsubMessage to true, to include the entire Pub/Sub message as expected by Splunk Add-on for GCP.
However, in prior versions of Splunk Dataflow template, in the case of includePubsubMessage=true, Pub/Sub message body was stringified and nested under the field message, whereas Splunk Add-on expected a JSON object nested under data field.
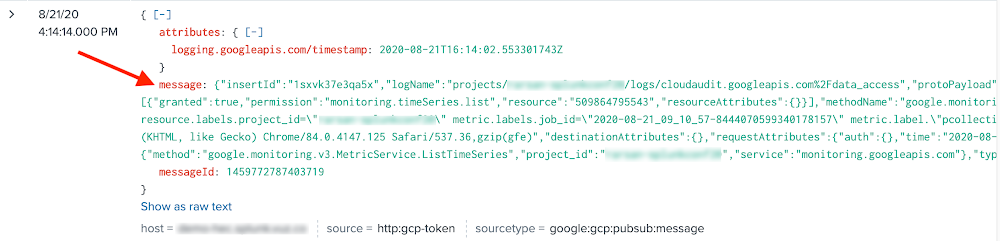
Message body stringified prior to Splunk Dataflow version 2021-05-03-00_RC00
This led customers to either customize their Splunk Add-on configurations (via props & transforms) to parse the payload, or use spath to explicitly parse JSON, and therefore maintain two flavors of Splunk searches (via macros) depending on whether data was pushed by Dataflow or pulled by Add-on...far from ideal experience. That’s no longer necessary as Splunk Dataflow template now serializes messages in a manner compatible with Splunk Add-on for GCP. In other words, the default JSON parsing, built-in Add-on fields extractions and data normalization work out-of-the-box:
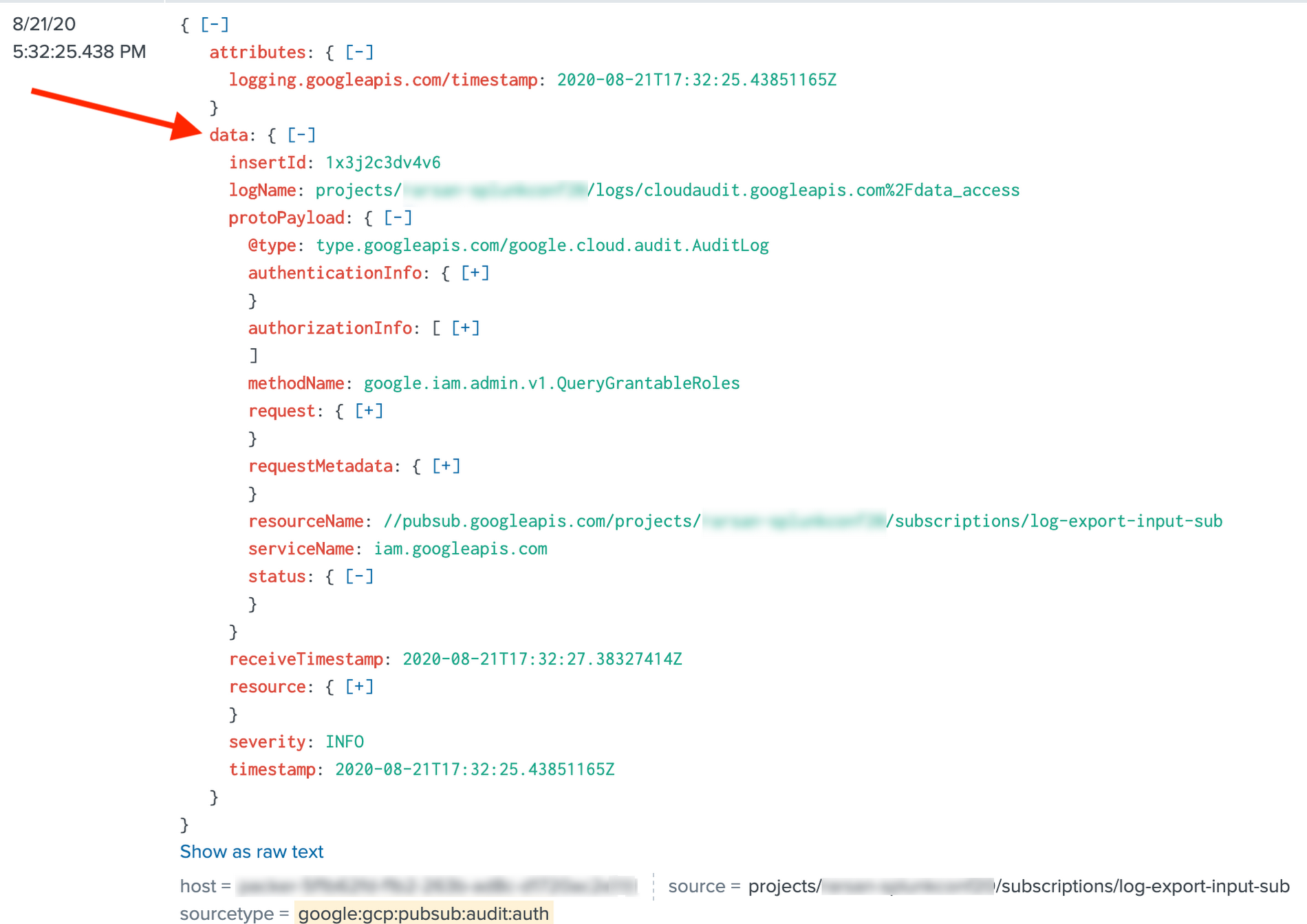
Message body as JSON payload as of Splunk Dataflow version 2021-05-03-00_RC00
Customers can readily take advantage of all the sourcetypes in Splunk Add-on including Common Information Model (CIM) compliance. Those CIM models are required for compatibility with premium applications like Splunk Enterprise Security (ES) and IT Service Intelligence (ITSI) without any extra effort on the customer, as long as they have set includePubsubMessage=true in their Splunk Dataflow pipelines.
Note on updating existing pipelines with includePubsubMessage:
If you’re updating your pipelines from includePubsubMessage=false to includePubsubMessage=true and you are using a UDF function, make sure to update your UDF implementation since the function’s input argument is now the PubSub message wrapper rather that the underlying message body, that is the nested data field. In your function, assuming you save the JSON-parsed version of the input argument in obj variable, the body payload is now nested in obj.data. For example, if your UDF is processing a log entry from Cloud Logging, a reference to obj.protoPayload needs to be updated to obj.data.protoPayload.
Splunk HTTP Event Collector
We also heard from customers who wanted to use Splunk HEC ‘fields’ metadata to set custom index-time field extractions in Splunk. We have therefore added support for that last remaining Splunk HEC metadata field. Customers can now easily set these index-time field extractions on the sender side (Dataflow pipeline) rather than configuring non-trivial props & transforms on the receiver (Splunk indexer or heavy forwarder). A common use case is to index metadata fields from Cloud Logging, namely resource labels such as project_id and instance_id to accelerate Splunk searches and correlations based on unique Project IDs and Instance IDs. See example 2.2 under 'Pattern 2: Transform events’ in our blog about getting started with Dataflow UDFs for a sample UDF on how to set HEC fields metadata using resource.labels object.
More extensibility with utility UDFs
"I don’t know, and I would rather not guess."
— Frodo
For Splunk Dataflow users who want to tweak the pipeline’s output format, you can do so without knowing Dataflow or Apache Beam programming, or even having a developer environment setup. You might want to enrich events with additional metadata fields, redact some sensitive fields, filter undesired events, or set Splunk metadata such as destination index to route events to.
When deploying the pipeline, you can reference a user-defined function (UDF), that is a small snippet of JavaScript code, to transform the events in-flight. The advantage is that you configure such UDF as a template parameter, without changing, re-compiling or maintaining the Dataflow template code itself. In other words, UDFs offer a simple hook to customize the data format while abstracting low-level template details.
When it comes to writing a UDF, you can eliminate guesswork by starting with one of the utility UDFs listed in Extend your Dataflow template with UDFs. That article also includes a practical guide on testing and deploying UDFs.
More reliability and error handling
"The board is set, the pieces are moving. We come to it at last, the great battle of our time."
— Gandalf
Last but not least, the latest Dataflow template improves pipeline fault tolerance and provides a simplified Dataflow operator troubleshooting experience.
In particular, Splunk Dataflow template’s retry capability (with exponential backoff) has been extended to cover transient network failures (e.g. Connection timeout), in addition to transient Splunk server errors (e.g. Server is busy). Previously, the pipeline would immediately drop these events in the dead-letter topic. While this avoids data loss, it added unnecessary burden for the pipeline operator who is responsible to replay these undelivered messages stored in the dead-letter. The new Splunk Dataflow template minimizes this overhead by attempting retries whenever possible, and only dropping messages into the dead-letter topic when it’s a persistent issue (e.g. Invalid Splunk HEC token), or when the maximum retry elapsed time (15 min) has expired. For a breakdown of possible Splunk delivery errors, see Delivery error types in our Splunk Dataflow reference guide.
Finally, as more customers adopt UDFs to customize the behavior of their pipelines per previous section, we’ve invested in better logging for UDF-based errors such as JavaScript syntax errors. Previously, you could only troubleshoot these errors by inspecting the undelivered messages in the dead-letter topic. You can now view these errors in the worker logs directly from the Dataflow job page in Cloud Console. Here’s an example query you can use in Logs Explorer:
You can also set up an alert policy in Cloud Monitoring to alert you whenever such UDF error happens so you can review the message payload in the dead-letter topic for further inspection. You can then either tweak the source log sink (if applicable) to filter out these unexpected logs, or revise your UDF function logic to properly handle these logs.
What’s next?
"Home is behind, the world ahead, and there are many paths to tread through shadows to the edge of night, until the stars are all alight."
— J. R. R. Tolkien
We hope this gives you a good overview of recent Splunk Dataflow enhancements. Our goal is to minimize your operational overhead for logs aggregation & export, so you can focus on getting real-time insights from your valuable logs.
To get started, check out our reference guide on deploying production-ready log exports to Splunk using Dataflow. Take advantage of the associated Splunk Dataflow Terraform module to automate deployment of your log export, as well as these sample UDF functions to customize your logs in-flight (if needed) before delivery to Splunk.
Be sure to keep an eye out for more Splunk Dataflow enhancements in our GitHub repo for Dataflow Templates. Every feature covered above is customer-driven, so please continue to submit your feature requests as GitHub repo issues, or directly from your Cloud Console as support cases.
Acknowledgements
Special thanks to Matt Hite from Splunk both for his close collaboration in product co-development, and for his partnership in serving joint customers.


