Data democratization with Dataplex: Implementing a data mesh architecture
Suhrid Saran
Senior Solution Architect, Data and Analytics, Virtusa
Saurabh Dubey
Partner Engineer, Google Cloud
Editor’s note: Today’s blog post was written in collaboration with Google Cloud Premier Partner Virtusa, which specializes in building cloud-native, microservices-based, pre-built solutions and APIs on Kubernetes, as well as machine learning and data-oriented applications, as well as offering managed cloud services and cloud operations design.
In the ever-evolving world of data engineering and analytics, traditional centralized data architectures are facing limitations in scalability, agility, and governance. To address these challenges, a new paradigm, called “data mesh,” has emerged, which allows organizations to take a decentralized approach to data architecture. This blog post explores data mesh as a concept and delineates the ways that Dataplex, a data fabric capability within the BigQuery suite, can be used to realize the benefits of this decentralized data architecture.
Data mesh is an architectural framework that promotes the idea of treating data as a product and decentralizes data ownership and infrastructure. It enables teams across an organization to be responsible for their own data domains, allowing for greater autonomy, scalability, and data democratization. Instead of relying on a centralized data team, individual teams or data products take ownership of their data, including its quality, schema, and governance. This distributed responsibility model leads to improved data discovery, easier data integration, and faster insights.
The illustration in Figure 1 is an overview of data mesh’s fundamental building blocks.
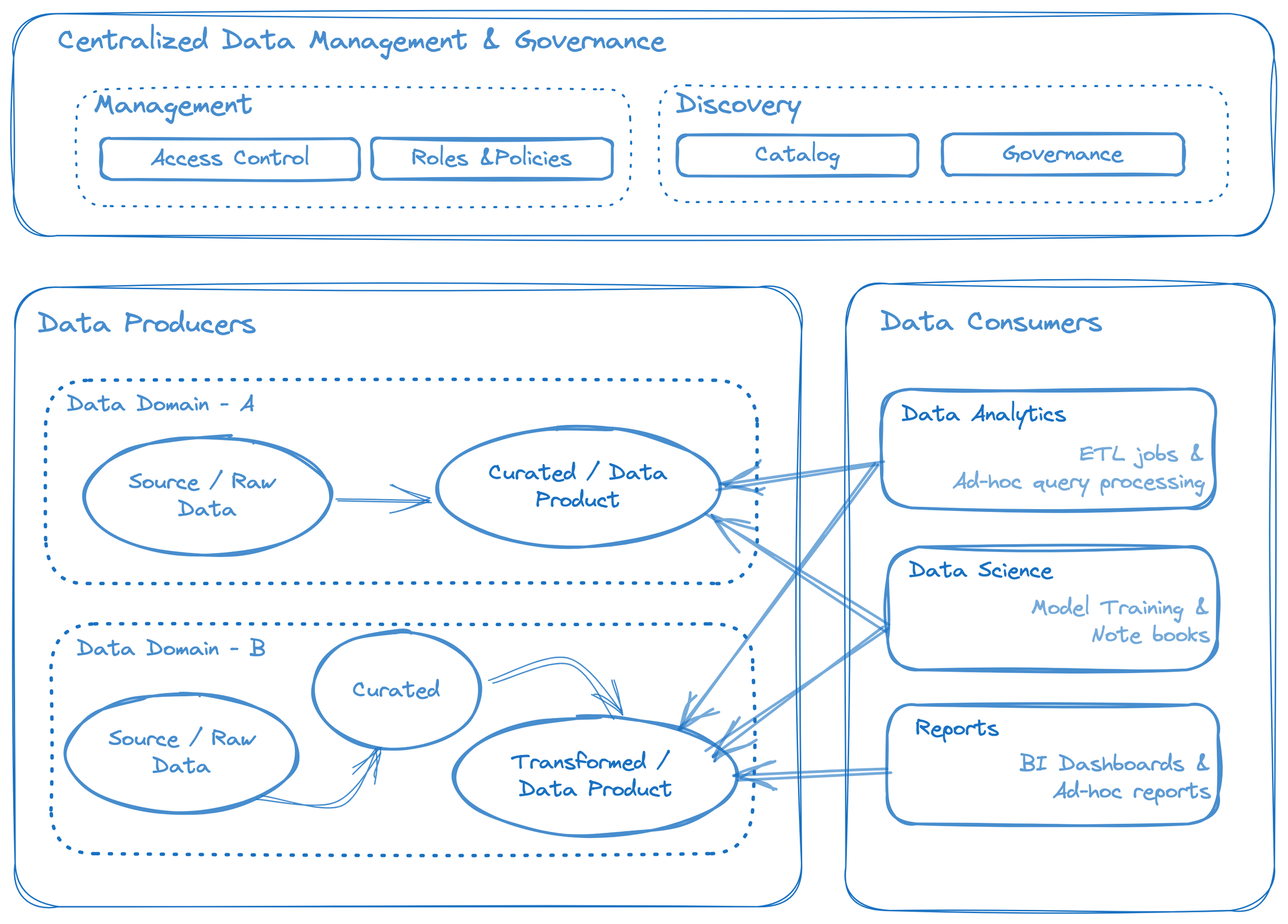
Figure 1: Representation of a data mesh concept
Let’s discuss the core principles of data mesh architecture, then understand how they change the way we manage and leverage data.
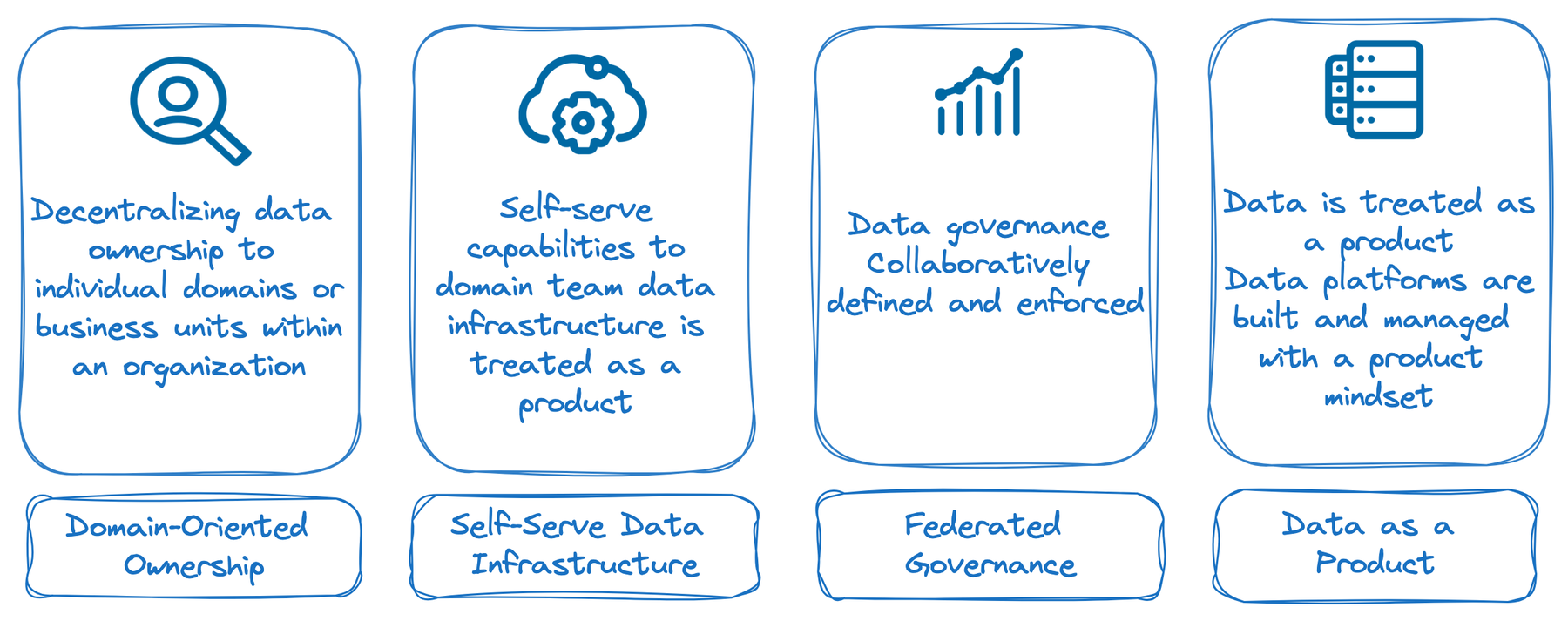
Figure 2: Core principals of data mesh architecture
Domain-oriented ownership: Data mesh emphasizes decentralizing data ownership and the allocation of responsibility to individual domains or business units within an organization. Each domain takes responsibility for managing its own data, including data quality, access controls, and governance. By doing so, domain experts are empowered, fostering a sense of ownership and accountability. This principle aligns data management with the specific needs and knowledge of each domain, ensuring better data quality and decision-making.
Self-serve data infrastructure: In a data mesh architecture, data infrastructure is treated as a product that provides self-serve capabilities to domain teams. Instead of relying on a centralized data team or platform, domain teams have the autonomy to choose and manage their own data storage, processing, and analysis tools. This approach allows teams to tailor their data infrastructure to their specific requirements, accelerating their workflows and reducing dependencies on centralized resources.
Federated computational governance: Data governance in a data mesh is not dictated by a central authority; rather, it follows a federated model. Each domain team collaboratively defines and enforces data governance practices that align with their specific domain requirements. This approach ensures that governance decisions are made by those closest to the data, and it allows for flexibility in adapting to domain-specific needs. Federated computational governance promotes trust, accountability, and agility in managing data assets.
Data as a product: Data in a data mesh is treated as a product, and data platforms are built and managed with a product mindset. This means focusing on providing value to the end users (domain teams) and continuously iterating and improving the data infrastructure based on feedback. When teams adopt a product thinking approach, data platforms become user-friendly, reliable, and scalable. They evolve in response to changing requirements and deliver tangible value to the organization.
Understanding Dataplex
Dataplex is a cloud-native, intelligent data fabric platform designed to simplify and streamline the management, integration, and analysis of large and complex data sets. It offers a unified approach to data governance, data discovery, and data lineage, enabling organizations to gain more value from their data.

Figure 3: Google Cloud Dataplex capabilities
Key features and benefits of Dataplex include data integration from various sources into a unified data fabric; robust data governance capabilities that help ensure security and compliance; intelligent data discovery tools for enhanced data visibility and accessibility; scalability and flexibility to handle large volumes of data in real-time; multi-cloud support for leveraging data across different cloud providers; and efficient metadata management for improved data organization and accessibility.
Steps to implement data mesh using Dataplex
Step 1: Create a data lake and define the data domain.
In this step, we set up a data lake on Google Cloud and establish the data domain, which refers to the scope and boundaries of the data that will be stored and managed in the data lake. A data lake is a centralized repository that allows you to store structured, semi-structured, and unstructured data in its native format, making it a flexible and scalable solution for big data storage and analytics.
The following diagram illustrates domains as Dataplex lakes, each owned by distinct data producers. Within their respective domains, data producers maintain control over creation, curation, and access. Conversely, data consumers have the ability to request access to these lakes (domains) or specific zones (subdomains) to conduct their analysis.
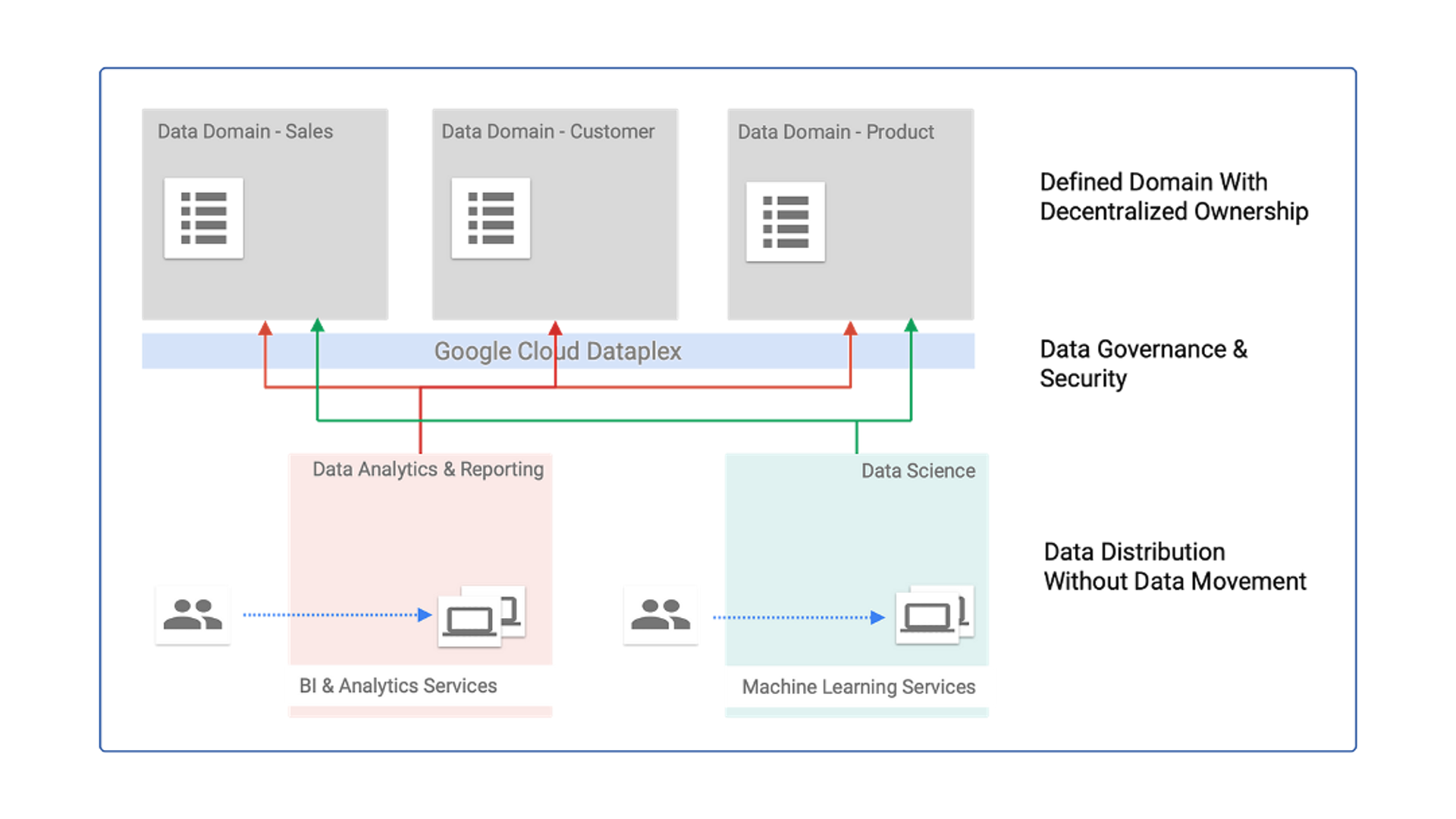
Figure 4: Decentralized data with defined ownership
Step 2: Create zones in your data lake and define the data zones.
In this step, we divide the data lake into zones. Each zone serves a specific purpose and has well-defined characteristics. Zones help organize data based on factors like data type, access requirements, and processing needs. Creating data zones provides better data governance, security, and efficiency within the data lake environment.
Common data zones include the following:
-
Raw zone: This zone is dedicated to ingesting and storing raw, unprocessed data. It is the landing zone for new data as it enters the data lake. Data in this zone is typically kept in its native format, making it ideal for data archival and data lineage purposes.
-
Curated zone: The curated zone is where data is prepared and cleansed before it moves to other zones. This zone may involve data transformation, normalization, or deduplication to ensure data quality.
-
Transformed zone: The transformed zone holds high-quality, transformed, and structured data that is ready for consumption by data analysts and other users. Data in this zone is organized and optimized for analytical purposes.
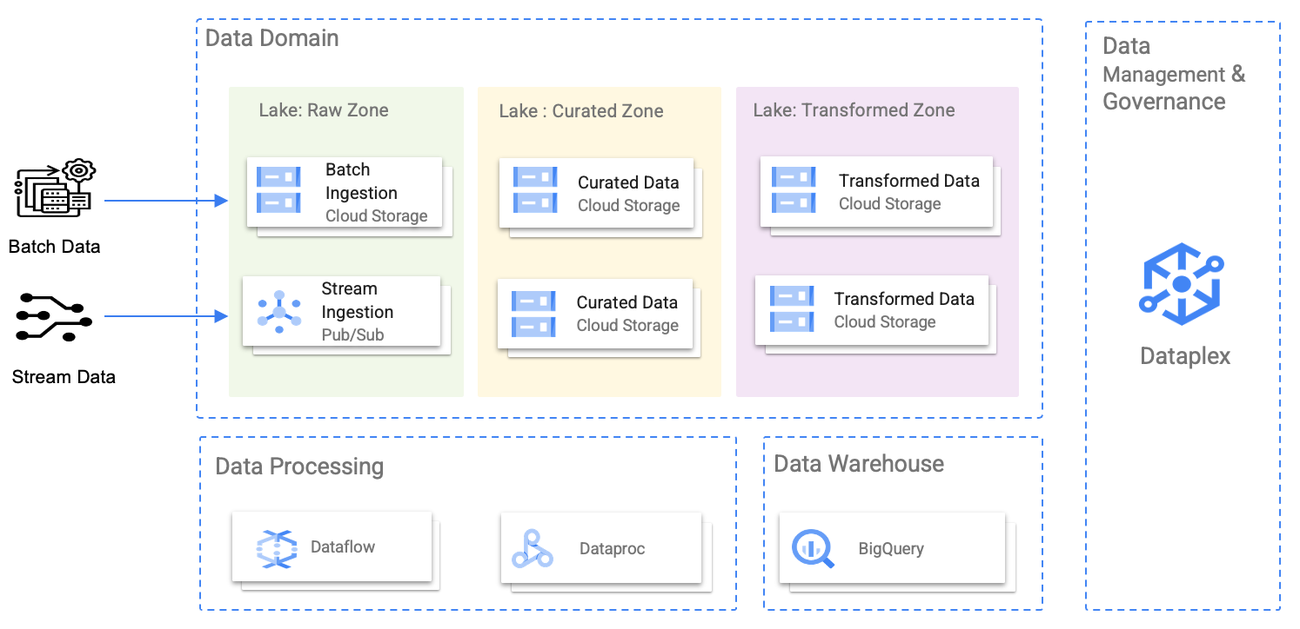
Figure 5: Data zones inside a data lake
Step 3: Add assets to the data lake zones.
In this step, we focus on adding assets to the different data lake zones. Assets refer to the data files, data sets, or resources that are ingested into the data lake and stored within their respective zones. By adding assets to the zones, you populate the data lake with valuable data that can be utilized for analysis, reporting, and other data-driven processes.
Step 4: Secure your data lake.
In this step, we implement robust security measures to safeguard your data lake and the sensitive data it holds. A secure data lake is crucial for protecting sensitive information, helping to ensure compliance with data regulations, and maintaining the trust of your users and stakeholders.
The security model in Dataplex enables you to control access for performing the following tasks:
-
Managing a data lake, which involves tasks such as creating and associating assets, defining zones, and setting up additional data lakes
-
Retrieving data linked to a data lake via the mapped asset (e.g., BigQuery data sets and storage buckets)
-
Retrieving metadata associated with the data linked to a data lake
The administrator of a data lake manages access to Dataplex resources (including the lake, zones, and assets) by assigning the necessary basic and predefined roles. Metadata roles possess the capability to access and examine metadata, including table schemas. With data roles granted, it gives the privilege to read or write data in the underlying resources referenced by the assets within the data lake.
Advantages of building a data mesh
Improved data ownership and accountability: One of the primary advantages of a data mesh is the shift in data ownership and accountability to individual domain teams. By decentralizing data governance, each team becomes responsible for the quality, integrity, and security of their data products.
Agility and flexibility: Data meshes empower domain teams to be autonomous in their decision-making, allowing them to respond swiftly to evolving business needs. This agility enables faster time to market for new data products and iterative improvements to existing ones.
Scalability and reduced bottlenecks: A data mesh eliminates scalability bottlenecks by distributing data processing and analysis across domain teams. Each team can independently scale its data infrastructure based on its specific needs, ensuring efficient handling of increasing data volumes.
Enhanced data discoverability and accessibility: Data meshes emphasize metadata management, enabling better data discoverability and accessibility. With comprehensive metadata, teams can easily locate and understand available data assets.
Empowerment and collaboration: By distributing data knowledge and decision-making authority, domain experts are empowered to make data-driven decisions aligned with their business objectives.
Scalable data infrastructure: With the rise of cloud technologies, data meshes can take advantage of scalable cloud-native infrastructure. Leveraging cloud services, such as serverless computing and elastic storage, enables organizations to scale their data infrastructure on-demand, ensuring optimal performance and cost-efficiency.
Comprehensive and robust data governance: Dataplex offers an extensive solution for data governance, ensuring security, compliance, and transparency throughout the data lifecycle. With fine-grained access controls, encryption, and policy-driven data management, Dataplex enhances data security and facilitates adherence to regulatory requirements. The platform provides visibility into the entire data lifecycle through lineage tracking, promoting transparency and accountability. Organizations can enforce standardized governance policies, ensuring consistency and reliability across their data landscape. Dataplex's tools for data quality monitoring and centralized data catalog governance further contribute to effective data governance practices.
Learn more
By embracing the principles of decentralization, data ownership, and autonomy, businesses can unlock a range of benefits, including improved data quality, greater accountability, and enhanced agility, scalability, and decision-making. Embracing this innovative approach can position organizations at the forefront of the data revolution, driving growth, innovation, and a competitive advantage. Learn more about Google Cloud’s open generative AI partner ecosystem. To get started with Google Cloud and Virtusa and to learn more about building a data mesh using Dataplex, contact us today.


