Unlock insights faster from your MySQL data in BigQuery
Mehran Nazir
Product Manager, Google Cloud
Frank Guan
Product Marketing Lead, Google Cloud
Data practitioners know that relational databases are not designed for analytical queries. Data-driven organizations that connect their relational database infrastructure to their data warehouse get the best of both worlds: a production database unhassled by a barrage of analytical queries, and a data warehouse that is free to mine for insights without the fear of bringing down production applications. The remaining question is how do you create a connection between two disparate systems with as little operational overhead as possible.
Dataflow Templates makes connecting your MySQL data warehouse with BigQuery as simple as filling out a web form. No custom code to write, no infrastructure to manage. Dataflow is Google Cloud’s serverless data processing for batch and streaming workloads that makes data processing fast, autotuned, and cost-effective. Dataflow Templates are reusable snippets of code that define data pipelines — by using templates, a user doesn’t have to worry about writing a custom Dataflow application. Google provides a catalog of templates that help automate common workflows and ETL use cases. This post will dive into how to schedule a recurring batch pipeline for replicating data from MySQL to BigQuery.
Launching a MySQL-to-BigQuery Dataflow Data Pipeline
For our pipeline, we will launch a Dataflow Data Pipeline. Data Pipelines allow you to schedule recurring batch jobs1 and feature a suite of lifecycle management features for streaming jobs that make it an excellent starting point for your pipeline. We’ll click on the “Create Data Pipeline” button at the top.
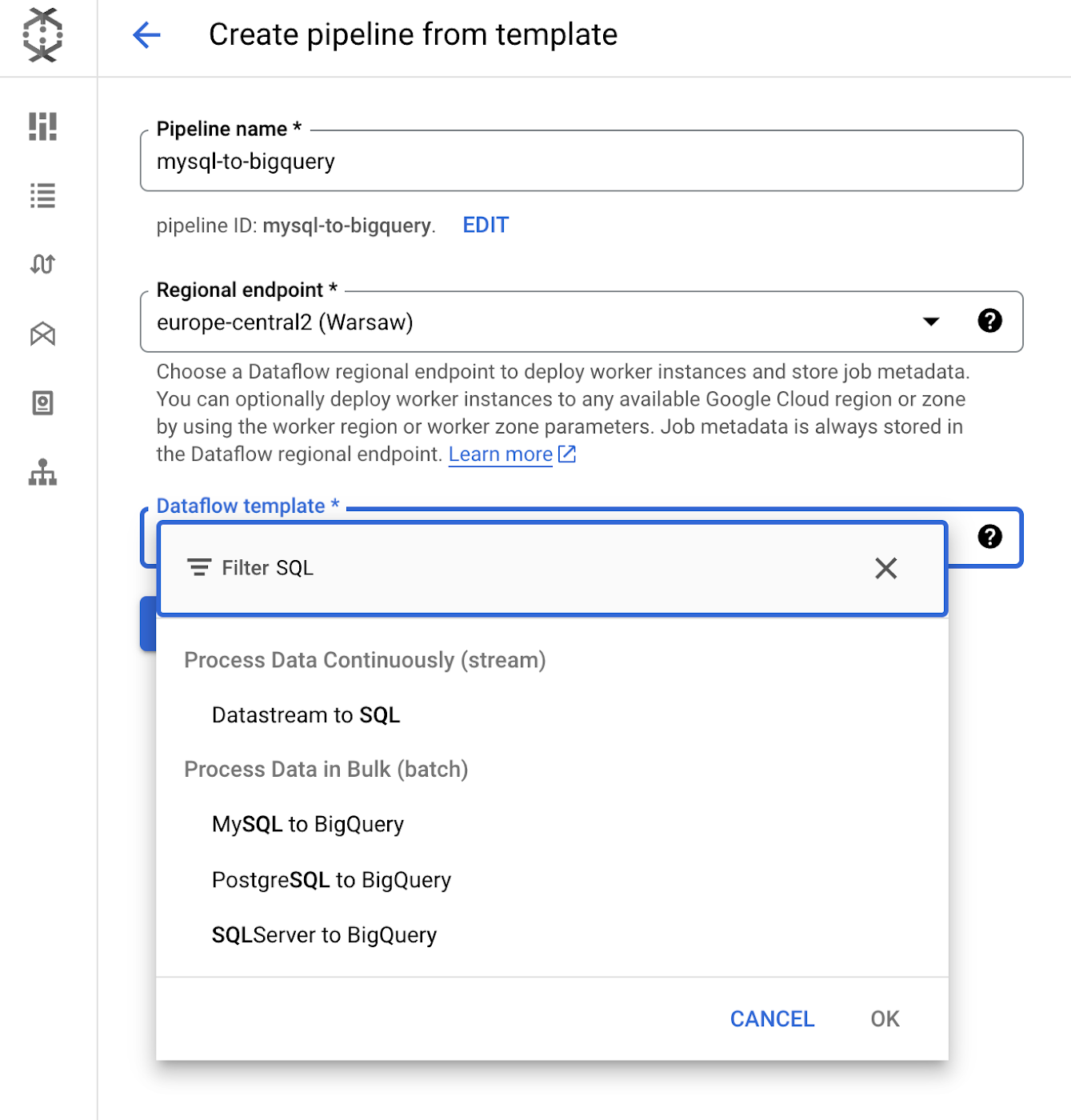
We will select the MySQL to BigQuery pipeline. As you can see, if your relational database is Postgres or SQL Server, we also have templates for those systems as well.
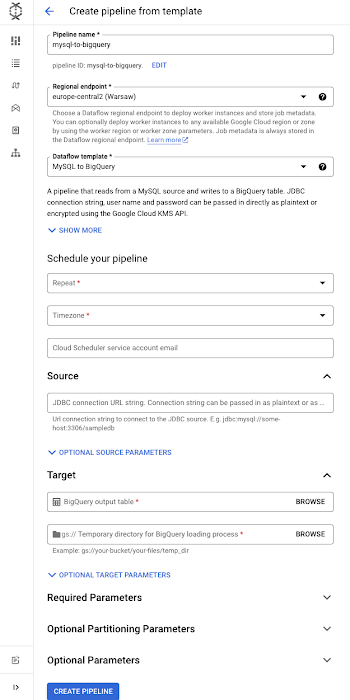
The form will now expand to provide a list of parameters for this pipeline that will help execute the pipeline:
Required parameters
Schedule: The recurring schedule for your pipeline (you can schedule hourly, daily, or weekly jobs, or define your own schedule with unix cron)
Source: The URL connection string to connect to the Jdbc source. If your database requires SSL certificates, you can append query strings that enable SSL mode and the GCS locations of certificates. These can be encoded using Google Cloud Key Management Service.
Target: BigQuery output table
Temp Bucket: GCS bucket for staging files
Optional parameters
Jdbc source SQL query, if you want to replicate a portion of the database.
Username & password, if your database requires authentication. You can also pass in an encoded string from Google Cloud KMS, if you desire.
Partitioning parameters
Dataflow-related parameters, including options to modify autoscaling, number of workers, and other configurations related to the worker environment. If you require an SSL certificate and you have truststore and certificate files, you will use the “extra files to stage” parameter to pass in their respective locations.
Once you’ve entered your configurations, you are ready to hit the Create Pipeline button.
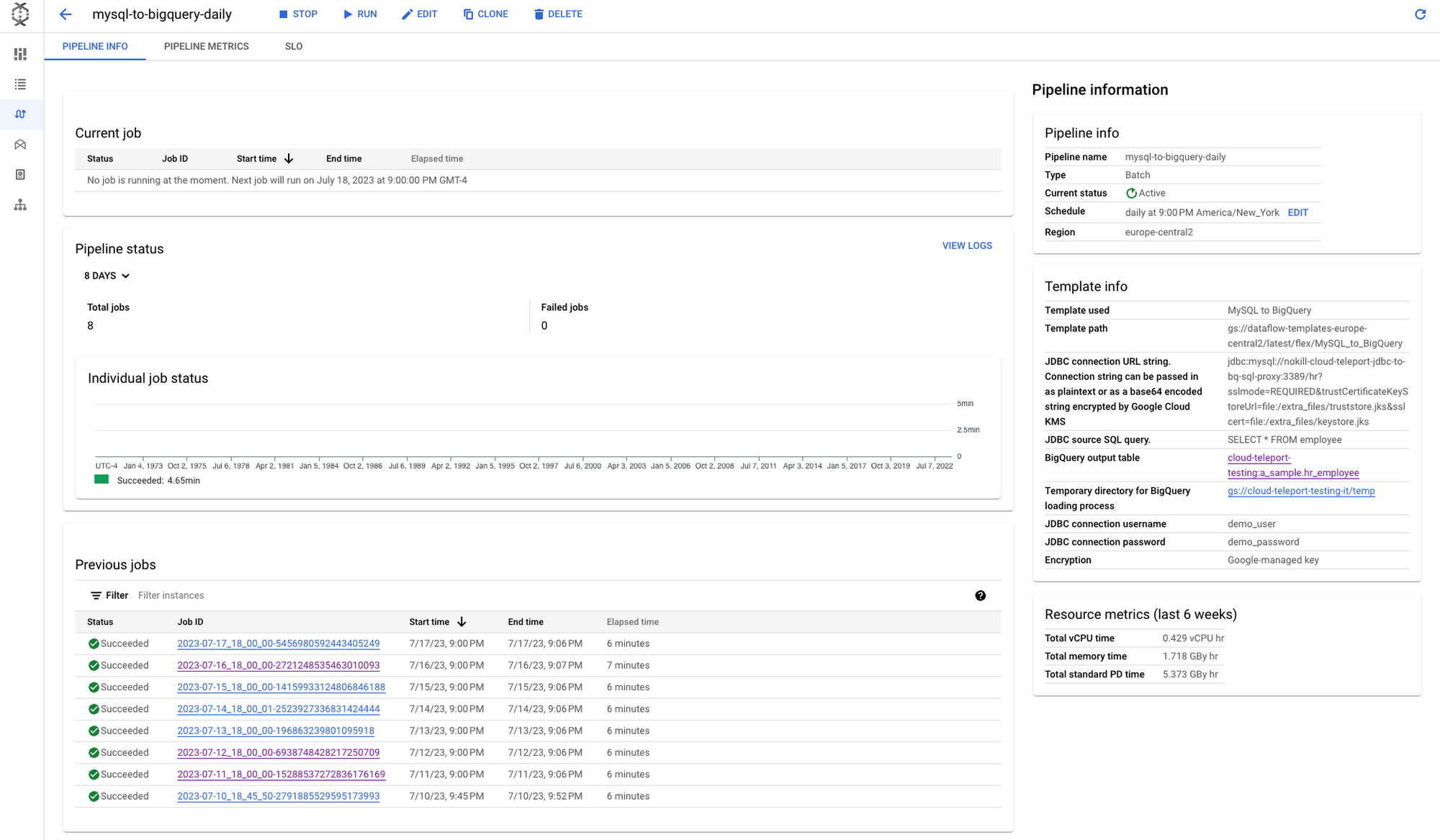
Creating the pipeline will take you to the Pipeline Info screen, which will show you a history of executions of the pipeline. This is a helpful view if you are looking for jobs that ran long, or identifying patterns that happen across multiple executions. You’ll find a list of jobs related to the pipeline in a table view near the bottom of the page. Clicking on one of those job IDs will allow you to inspect a specific execution in more detail.
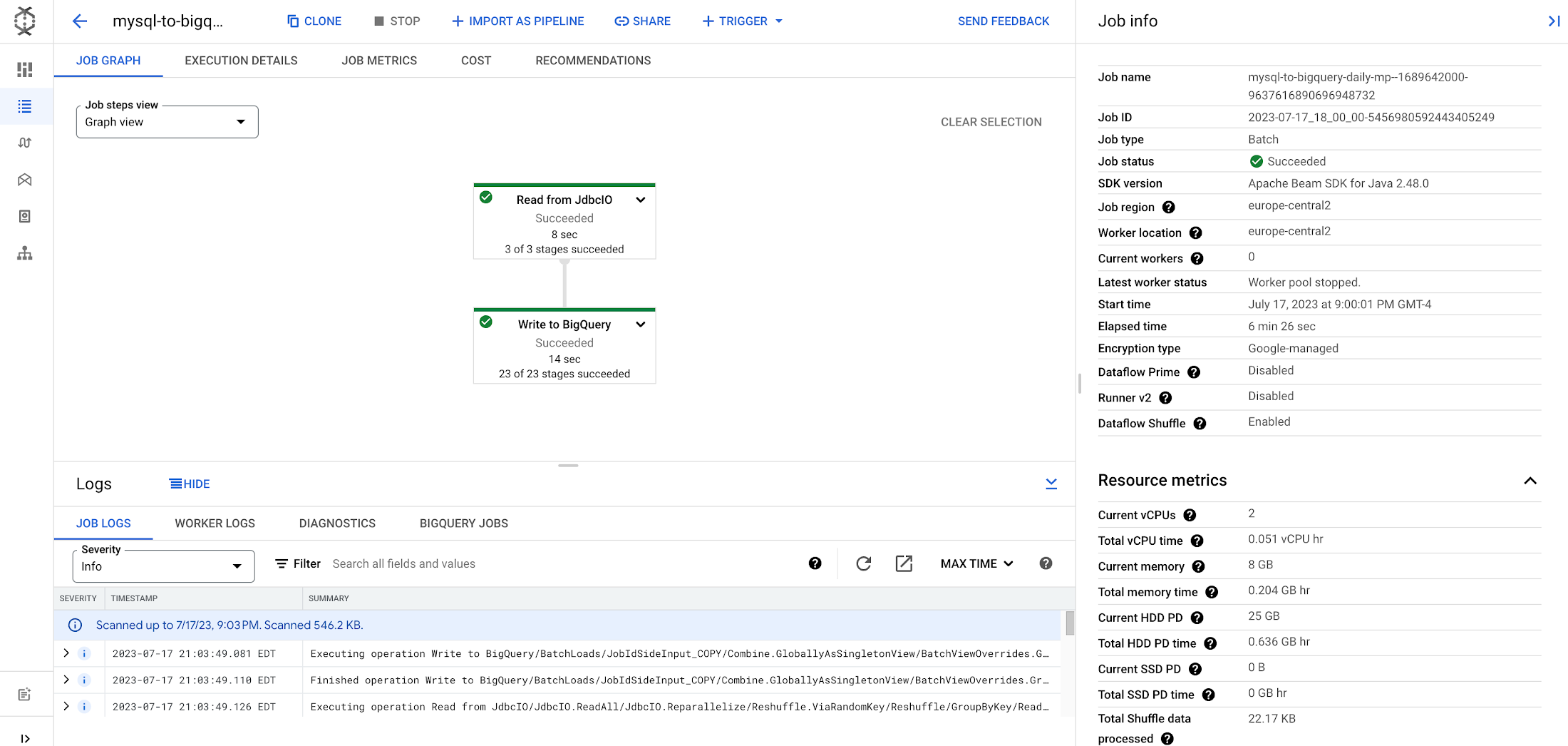
The Dataflow monitoring experience features a job graph showing a visual representation of the pipeline you launched, and includes a logging panel at the bottom that displays logs collected from the job and workers. You will find information associated with the job on the right hand panel, as well as several other tabs that allow you to understand your job’s optimized execution, performance metrics, and cost.
Finally, you can go to the BigQuery SQL workspace to see your table written to its final destination. If you prefer a video walkthrough of this tutorial, you can find that here. You’re all set for unlocking value from your relational database — and it didn’t take an entire team to set it up!
What’s next
If your use case involves reading and writing changes in continuous mode, we recommend checking out our Datastream product, which serves change-data-capture and real-time replication use cases. If you prefer a solution based on open-source technology, you can also explore our Change Data Capture Dataflow template that uses a Debezium connector to publish messages to Pub/Sub, then writes to BigQuery.
Happy Dataflowing!
1. If you do not need to run your job on a scheduled basis, we recommend using the “Create Job from Template” workflow, found on the “Jobs” page

