More flexibility for your Dataflow jobs with new controls for latency versus cost
Yi Ding
Software Engineer, Google Dataflow Streaming
Yuriy Zhovtobryukh
Senior Product Manager, Google
Dataflow Streaming Engine users know that there’s no such thing as an "average" streaming use case. Some customers have strict latency requirements that must be met even during traffic spikes. Others are more concerned with cost and want to run their streaming pipelines as efficiently as possible. The question is: Do you prefer lower peak latency or lower streaming costs for your workload?
For example, with a network threat detection use case, being able to identify and react to cyberattacks in real-time is crucial. In such real-time scenarios, it’s preferable to keep latency as low as possible by provisioning resources more aggressively. In contrast, other use cases like product analytics can tolerate a 30-60 sec delay, so keeping the costs in check by provisioning resources more conservatively is likely the correct decision.
An autoscaler’s algorithm significantly influences peak latency and pipeline costs. A more aggressive autoscaling strategy helps maintain low latency by promptly adding resources to process data when traffic increases. On the other hand, a less aggressive autoscaling approach aims to minimize costs by managing resources conservatively. The impact can be substantial. Consider the following typical streaming job, ingesting Pub/Sub events to BigQuery:
This specific Pub/Sub to BigQuery Dataflow pipeline demonstrates how a user can choose to reduce latency by 82% or reduce cost by 24.5% by changing the autoscaling hint value to 0.3 for minimal latency or to 0.7 for minimal cost.
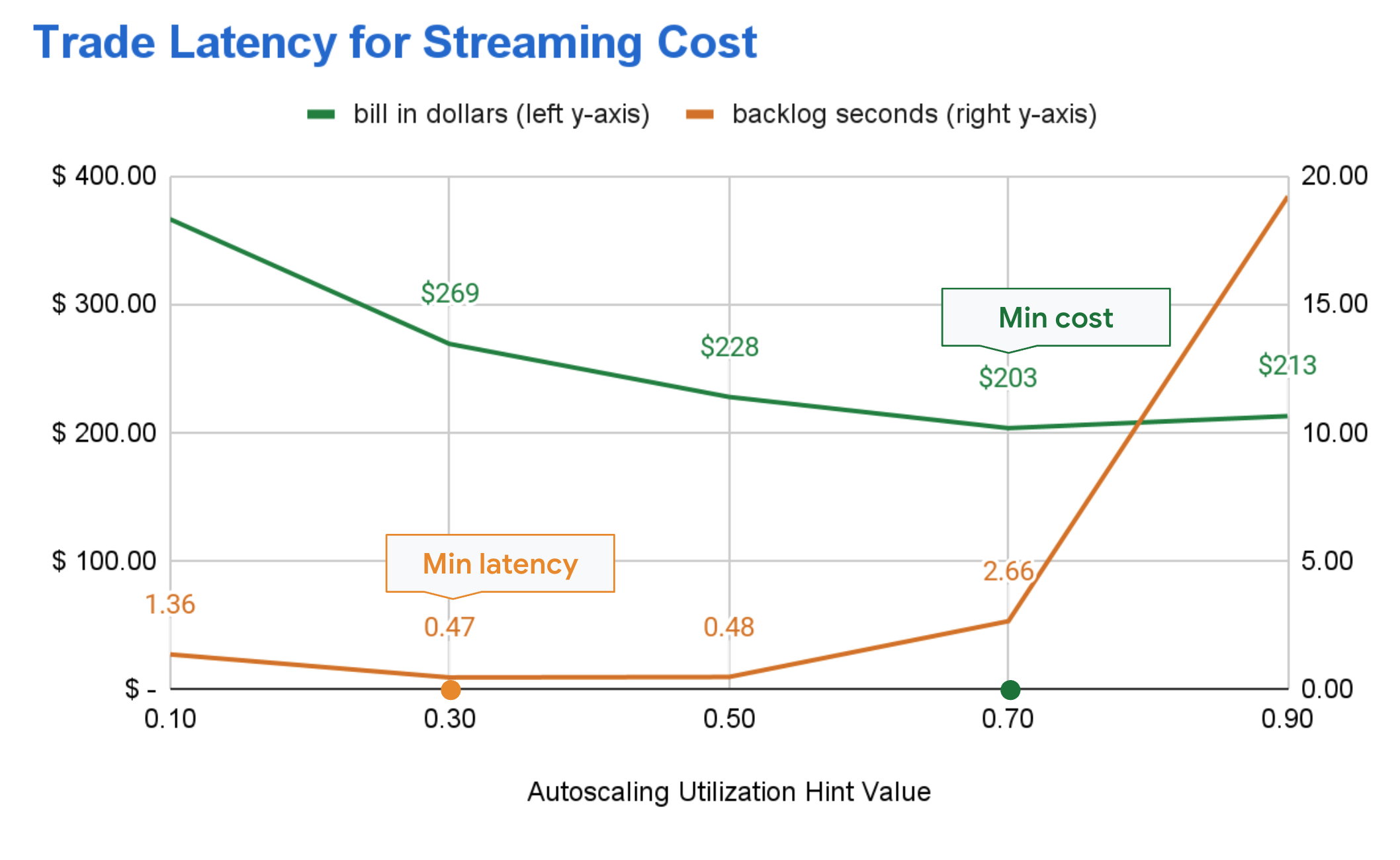
Your specific streaming pipeline’s curve may have a very different shape than this one test pipeline’s, but the core idea still applies: by changing the autoscaling utilization hint value, Dataflow streaming users can set and modify their preferences for lower latency or cost.
Find the optimum for your specific streaming pipelines
At the core of autoscaler decision-making is the CPU utilization of the workers performing the pipeline’s computations. Dataflow’s streaming autoscaler tends to scale up when the current worker’s utilization exceeds the acceptable upper bound for worker CPU utilization, and scale down when current worker utilization drops below the utilization lower bound. You can set the autoscaling utilization hint to a higher or lower value using a Dataflow service option. Setting this value allows you to encode the decision about cost vs. latency for your use case.
The hard part is to find the optimum hint value for a specific streaming pipeline. As a rule of thumb, you should consider reducing the autoscaling utilization hint to achieve lower latency when the pipeline:
-
Scales up too slowly: The autoscale lags behind traffic spikes and backlog seconds start to grow.
-
Scales down too much: Current worker CPU utilization is low and the backlog grows.
Conversely, you should consider increasing the autoscaling utilization hint to reduce cost when you observe excessive upscaling and want to reduce costs if high worker utilization and higher latency are acceptable for the use case.
There are no “universal” minimum cost or latency autoscaling utilization hint values. The shape of the cost-latency curve (like the one you see in the example graph above) is specific to a particular streaming job. Also, the optimum values may change or “drift” over time as the properties of the pipeline change due to, for example, variations in the traffic pattern.
Dataflow’s autoscaling UI provides insights on when it’s worth adjusting the autoscaling behavior. You can modify the autoscaling hint value in real time without having to stop the job to address the changing data load and meet your business requirements. The current worker utilization metric is an important heuristic that you may want to align the autoscaling hint value to start with.
Monitor the impact of changes
To make it easier for you to evaluate and fine-tune the autoscaling performance to your preferences, we’ve also introduced additional dashboards and metrics in the Dataflow autoscaling UI.
In particular, you may want to start by observing the following four graphs:
-
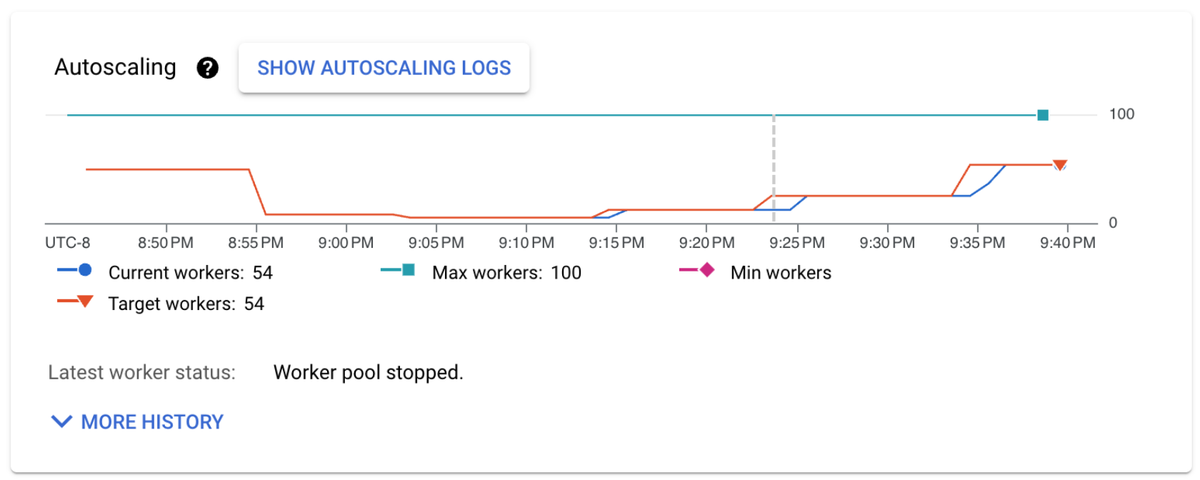
Autoscaling: shows current and target worker counts and displays time-series autoscaling data, along with min / max and target number of workers
-
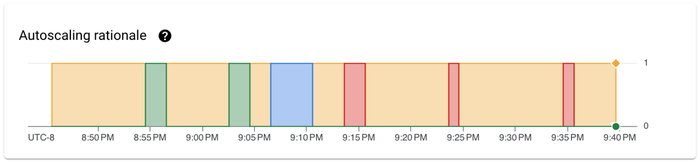
Autoscaling rationale: explains the factors driving autoscaling decisions (upscale, downscale, no change)
-
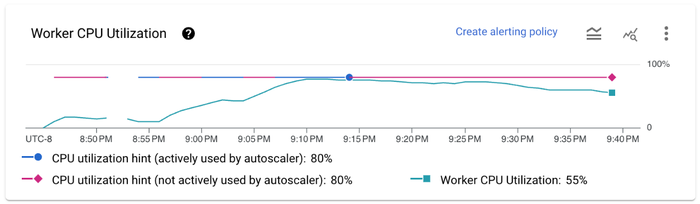
Worker CPU utilization: shows current user worker CPU utilization and customer hint value (when it is actively used in the autoscaling decision1). This is an important factor in the autoscaling decisions.
-
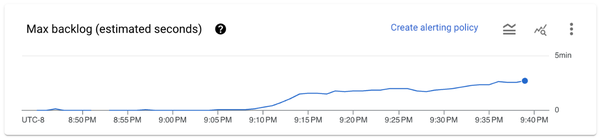
Max backlog estimated seconds chart gives an indication of pipeline latency. This is another major factor in the autoscaling decisions2.
Thank you for reading this far! We are thrilled to bring these capabilities to our Dataflow Streaming Engine users and see different ways you use Dataflow to transform your business. Get started with Dataflow right from your console. Stay tuned for future updates and learn more by contacting the Google Cloud Sales team.
1. It is important to note that Customer Hint for Autoscaling is just one of the factors impacting autoscaler decisions. The autoscaler algorithm can override it due to other factors. Read more here
2. When backlog is high, the autoscaling utilization hint would be ignored by autoscaling policy to keep latency low. Read more here

