Transform SQL into SQLX for Dataform
Christian Yarros
Strategic Cloud Engineer, Google
Kidus Adugna
Cloud Technical Resident
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialIntroduction
Developing in SQL poses significant problems when compared to other languages and frameworks. It's not easy to reuse statements across different scripts, there's no way to write tests to ensure data consistency, and dependency management requires external software solutions. Developers will typically write thousands of lines of SQL to ensure data processing occurs in the correct order. Additionally, documentation and metadata are afterthoughts because they need to be managed in an external catalog.
Google Cloud offers Dataform and SQLX to solve these challenges.
Dataform is a service for data analysts to test, develop, and deploy complex SQL workflows for data transformation in BigQuery. Dataform lets you manage data transformation in the Extraction, Loading, and Transformation (ELT) process for data integration. After extracting raw data from source systems and loading into BigQuery, Dataform helps you transform it into a well-defined, tested, and documented suite of data tables.
SQLX is an open source extension of SQL and the primary tool used in Dataform. As it is an extension, every SQL file is also a valid SQLX file. SQLX brings additional features to SQL to make development faster, more reliable, and scalable. It includes functions including dependencies management, automated data quality testing, and data documentation
Teams should quickly transform their SQL into SQLX to gain the full suite of benefits that Dataform provides. This blog contains a high-level, introductory guide demonstrating this process.
The steps in this guide use the Dataform on Google Cloud console. You can follow along or implement these steps with your own SQL scripts!
Getting Started
Here is an example SQL script we will transform into SQLX. This script takes a source table containing reddit data. The script cleans, deduplicates, and inserts the data into a new table with a partition.
1. Create a new SQLX file and add your SQL
In this guide we’ll title our file as comments_partitioned.sqlx.
As you can see below, our dependency graph does not provide much information.
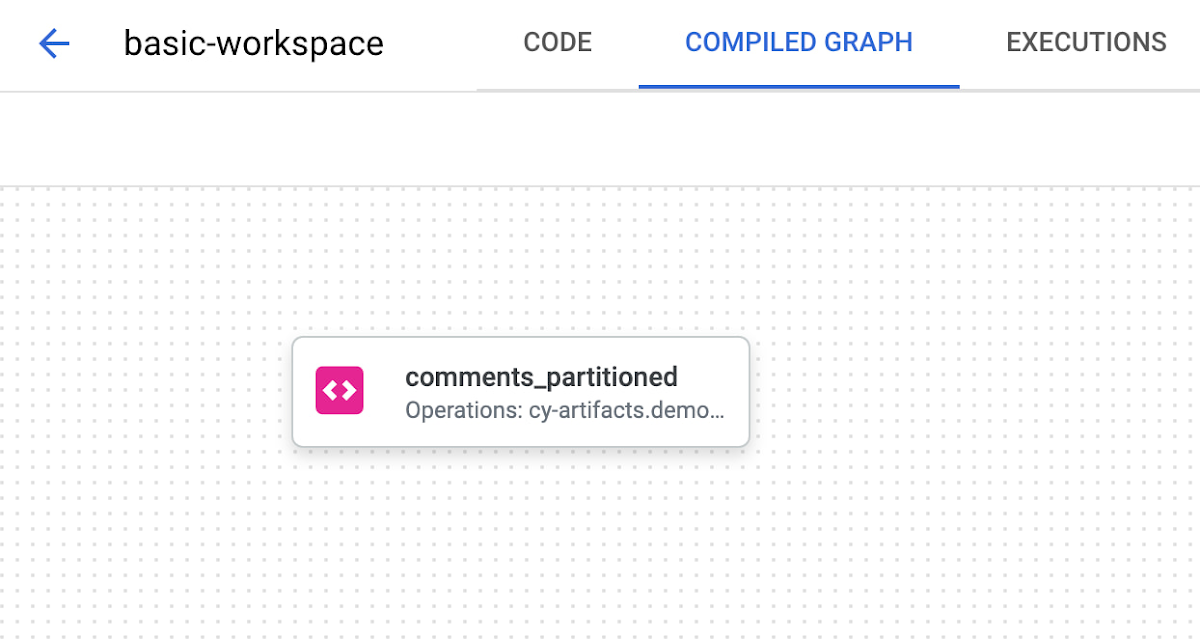
2. Refactor SQL to remove DDL and use only SELECT
In SQLX, you only write SELECT statements. You specify what you want the output of the script to be in the config block, like a view or a table as well as other types available. Dataform takes care of adding CREATE OR REPLACE or INSERT boilerplate statements.
3. Add a config object containing metadata
The config object will contain the output type, description, schema (dataset), tags, columns and their descriptions, and the BigQuery-related configuration. Check out the example below.
4. Create declarations for any source tables
In our SQL script, we directly write reddit_stream.comments_stream. In SQLX, we’ll want to utilize a declaration to create relationships between source data and tables created by Dataform. Add a new comments_stream.sqlx file to your project for this declaration:
We’ll utilize this declaration in the next step.
5. Add references to declarations, tables, and views.
This will help build the dependency graph. In our SQL script, there is a single reference to the declaration. Simply replace reddit_stream.comments_stream with ${ref("comments_stream")}.
Managing dependencies with the ref function has numerous advantages.
The dependency tree complexity is abstracted away. Developers simply need to use the
reffunction and list dependencies.It enables us to write smaller, more reusable and more modular queries instead of thousand-line-long queries. That makes pipelines easier to debug.
You get alerted in real time about issues like missing or circular dependencies
6. Add assertions for data validation
You can define data quality tests, called assertions, directly from the config block of your SQLX file. Use assertions to check for uniqueness, null values or any custom row condition. The dependency tree adds assertions for visibility.
Here are assertions for our example:
These assertions will pass if comment_id is a unique key, if comment_text is non-null, and if all rows have total_words greater than zero.
7. Utilize JavaScript for repeatable SQL and parameterization
Our example has a deduplication SQL block. This is a perfect opportunity to create a JavaScript function to reference this functionality in other SQLX files. For this scenario, we’ll create the includes folder and add a common.js file with the following contents:
Now, we can replace that code block with this function call in our SQLX file as such:
${common.dedupe("t1", "comment_id")}
In certain scenarios, you may want to use constants in your SQLX files. Let’s add a constants.js file to our includes folder and create a cost center dictionary.
We can use this to label our output BigQuery table with a cost center. Here’s an example of using the constant in a SQLX config block:
8. Validate the final SQLX file and compiled dependency graph
After completing the above steps, let’s have a look at the final SQLX files:
comments_stream.sqlx
comments_partitioned.sqlx
Let's validate the dependency graph and ensure the order of operations looks correct.
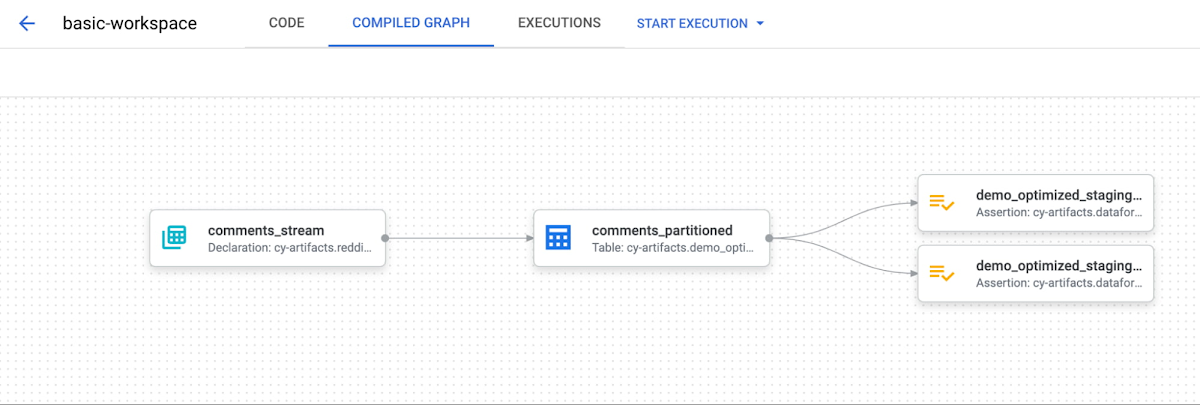
Now it’s easy to visualize where the source data is coming from, what output type comments_partitioned is, and what data quality tests will occur!
Next Steps
This guide outlines the first steps of transitioning legacy SQL solutions to SQLX and Dataform for improved metadata management, comprehensive data quality testing, and efficient development. Adopting Dataform streamlines the management of your cloud data warehouse processes allowing you to focus more on analytics and less on infrastructure management. For more information, check out Google Cloud’s Overview of Dataform. Explore our official Dataform guides and Dataform sample script library for even more hands-on experiences.


