Dataflow Prime: bring unparalleled efficiency and radical simplicity to big data processing
Evren Eryurek PhD
Director Product Management, Google Cloud
Haakon Ringberg
Senior Engineering Director, Google Cloud
The speed with which businesses are able to respond to change is the difference between those that successfully navigate the future and those that get left behind. Answering “What has happened” isn’t enough - businesses now need to know “What is happening now” and “What might happen”, and take proactive action in response. Addressing these business questions in real time allows your team to rapidly respond to changing business needs, and provide timely, pertinent and delightful experiences for your end customers.
We built Dataflow so that you can build data platforms that answer these questions and more. Dataflow is a no-ops, serverless data processing platform that enables you to collect and enrich the vast amounts of data that your applications and users generate.
Some customers use Dataflow to process data in real time to make it useful and insightful for your business users. Others use streaming analytics reference patterns to integrate ML into data pipelines. Many customers also use Dataflow (using Dataflow Templates) to integrate streaming and batch data into data lakes so that their business users can gain near real time insights and drive decisions.
Whatever the use case may be, Dataflow’s no-ops, fully managed platform based on open APIs (Apache Beam) lets users vastly simplify their data architectures and deliver insights with ML.
Announcing Dataflow Prime
We are excited to announce Dataflow Prime, a new platform based on a serverless, no-ops, auto-tuning architecture that is easy to onboard, use and operate. We built Dataflow Prime to bring unparalleled resource utilization and radical operational simplicity to big data processing.
Dataflow Prime builds on Dataflow and brings new user benefits with innovations in resource utilization and distributed diagnostics. The new capabilities in Dataflow significantly reduce the time spent on infrastructure sizing and tuning tasks, as well as time spent diagnosing data freshness problems. Dataflow Prime enables you to get more done with less in the following ways:
Eliminate the time you spend sizing resource needs: Vertical Autoscaling (in conjunction with horizontal Autoscaling) means you don't have to spend days determining the optimum configuration of resources for your pipeline.
Optimize resource usage and save costs: Right Fitting, an industry-first technology, makes it possible to use custom resource configuration for each stage of the data pipeline, reducing waste.
Increase your productivity: The new diagnostics tools make it easier to meet and maintain business service level objectives (SLO) data processing jobs.
Customers such as Best Buy are excited with Dataflow Prime’s new capabilities to provide much needed tools to manage and diagnose their data pipelines at scale.
“Scaling effectively to handle continuously variable workloads in a fully automated way is very critical for us to meet service level objectives (SLOs)" said Ramesh Babu, Sr Director of Engineering, Best Buy. "The smart diagnostics and auto tuning features of Dataflow Prime not only allows us to just do that but also provides us with the ability to better observe the performance of the data pipelines.”
Availability and Compatibility
Dataflow Prime will be available in Preview in early Q3 of this year. We’ve built Dataflow Prime such that if you are a current user of Dataflow, you can bring your existing Dataflow jobs to Dataflow Prime by just setting a flag. Dataflow, in its current form, will continue to be available and supported, and you can move to Dataflow Prime at the time that makes the most sense for you.
Delivering unparalleled resource utilization with Serverless++ Autotuning
Dataflow already includes a number of autotuning capabilities. Dataflow Prime builds on this foundation and pushes the boundaries with the following new features.
Vertical Autoscaling dynamically adjusts the compute capacity allocated to each worker based on utilization. Vertical Autoscaling detects situations when users’ jobs are limited by worker resources and automatically adds more resources to those workers. Vertical Autoscaling works hand in hand with Horizontal Autoscaling to seamlessly scale workers to best fit the needs of the pipeline. As a result, it no longer takes hours or days to determine the perfect worker configuration to maximize utilization. Vertical Autoscaling also increases the reliability of your jobs. For example, jobs that need more memory than what is available fail midway with out-of-memory errors. In such cases, Vertical Autoscaling will automatically add more memory so that the job can complete execution.
Right Fitting: Each stage of a pipeline typically has a different resource requirement than the others. For example, one stage of the pipeline may implement ML predictions using a large ML model, and as a result, that stage may require larger memory workers. A following stage may use GPU for image processing. Until now, either all workers in the pipeline would have had the higher memory and GPU, or none of them would. Pipelines either had to waste resources or suffer slow/stalled workloads. Right Fitting solves this problem by creating stage-specific pools of resources, optimized for each stage. For example, the stage that processes images gets GPU whereas the stage that does ML scoring gets more memory.
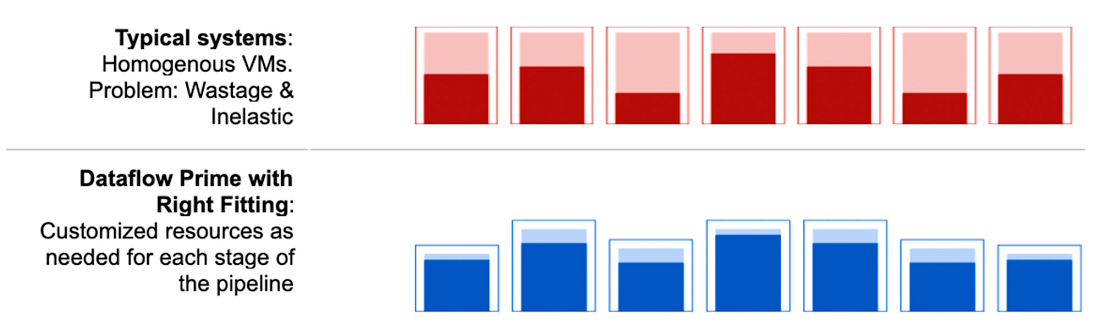
These new capabilities allow Dataflow to treat the underlying compute resources as a flexible collection of resources that can be scaled both horizontally and vertically and right-fitted for what the pipeline needs in a very granular way. This auto fitting infrastructure solves one of the most challenging and labor-intensive tasks for large-scale data processing.
Delivering radical simplicity with Smart Diagnostics
Based on decades of building big data processing systems for Google’s own use, we have built a set of new big data diagnostics and optimization tools that makes pinpointing problems with data pipelines fast and easy. Identifying bottlenecks and spotting problematic user code is a very challenging task, even for single threaded applications running in a single server. It becomes an exponentially harder problem when dealing with data-parallel pipelines running on tens or hundreds of workers. To address these challenges, Dataflow Prime includes the following capabilities:
- Job Visualizer allows users to see how their code is executed across dozens or hundreds of workers. Hot keys and inefficient code are visualized as elongated bars in the stage progress views, making it easier than ever to find parallelization bottlenecks. The tool also surfaces a list of steps for each stage of your pipeline in descending order of wall time, which can quickly indicate where your code can be optimized.
- Data Pipelines: The most important aspect users care about is meeting business SLOs. Managing individual jobs, while a critical requirement, does not allow users to focus on the business needs and SLOs that need to be met. In order to address this need, Data Pipelines brings scheduling, monitoring, SLO tracking and other management features to the logical pipeline level, while maintaining the ability to manage specific jobs when there is a need.
- Smart Recommendations: Smart Recommendations automatically detects problems in your pipeline and shows potential fixes. For example, if your pipeline is running into permissions issues, a Smart Recommendation will detect which IAM permissions you need to enable to unblock your job. If you are using an inefficient coder in your job, Smart Recommendations will surface more performant coder implementations that can help you save on costs.
What’s next
We’re excited for you to start using Dataflow Prime, which will be available in Preview Q3 2021. Interested customers can sign up to receive updates here or contact the Google Cloud sales team.



