New AI-driven features in Dataprep enhance the wrangling experience
Bertrand Cariou
Sr. Director Solutions & Partner Marketing, Trifacta
Since the inception of Cloud Dataprep by Trifacta, we’ve focused on making the data preparation work of data professionals more accessible and efficient, with a determined intention to make the work of preparing data more enjoyable (and even fun, in some cases!).
The latest release of Dataprep brings new and enhanced AI-driven features to advance your wrangling experience a step further. We've improved the Dataprep core transformation experience, so it's easier and faster to clean data and operationalize your wrangling recipes.
We’ve been infusing AI-driven functions in many parts of Dataprep so it can suggest the best ways to transform data or figure out automatically how to clean the data, even for complex analytics cases. This effort has helped a broad set of business users access and leverage data in their transformational journey to become data-driven organizations.
With data preparation fully integrated with our smart analytics portfolio, including ingestion, storage, processing, reporting, and machine learning, self-service analytics for everyone—not just data scientists and analysts—is becoming a reality.
Let's zoom in on a few new features and see how they can make data preparation easier.
Improving fuzzy matching on rapid target
When you prepare your data using Dataprep, you can use the exploratory mode to figure out what the data is worth and how you might use it. You could also use exploratory mode to enhance an existing data warehouse or some production zones in a data lake.
For the latter, you can use Rapid Target to quickly map your wrangling recipe to an existing data schema in BigQuery or a file in Cloud Storage. Using Rapid Target means you don’t have to bother matching your data transformation rules to an existing database schema; Dataprep will figure it out for you using AI. With the new release, in addition to matching schemas by strict column name equality, we have added fuzzy-matching algorithms to auto-align columns with the target schema by column name similarities or column content. Here’s what that looks like:
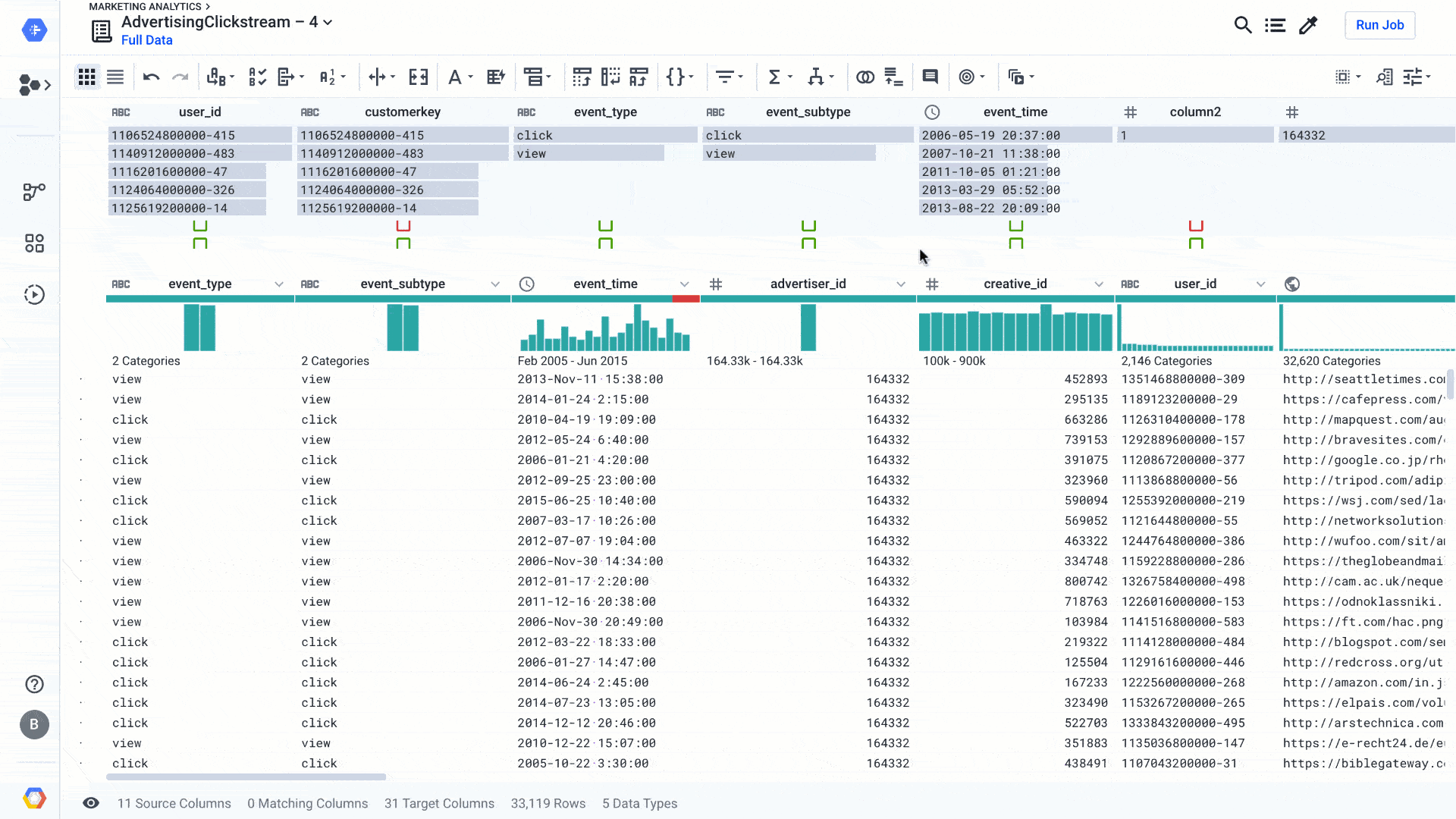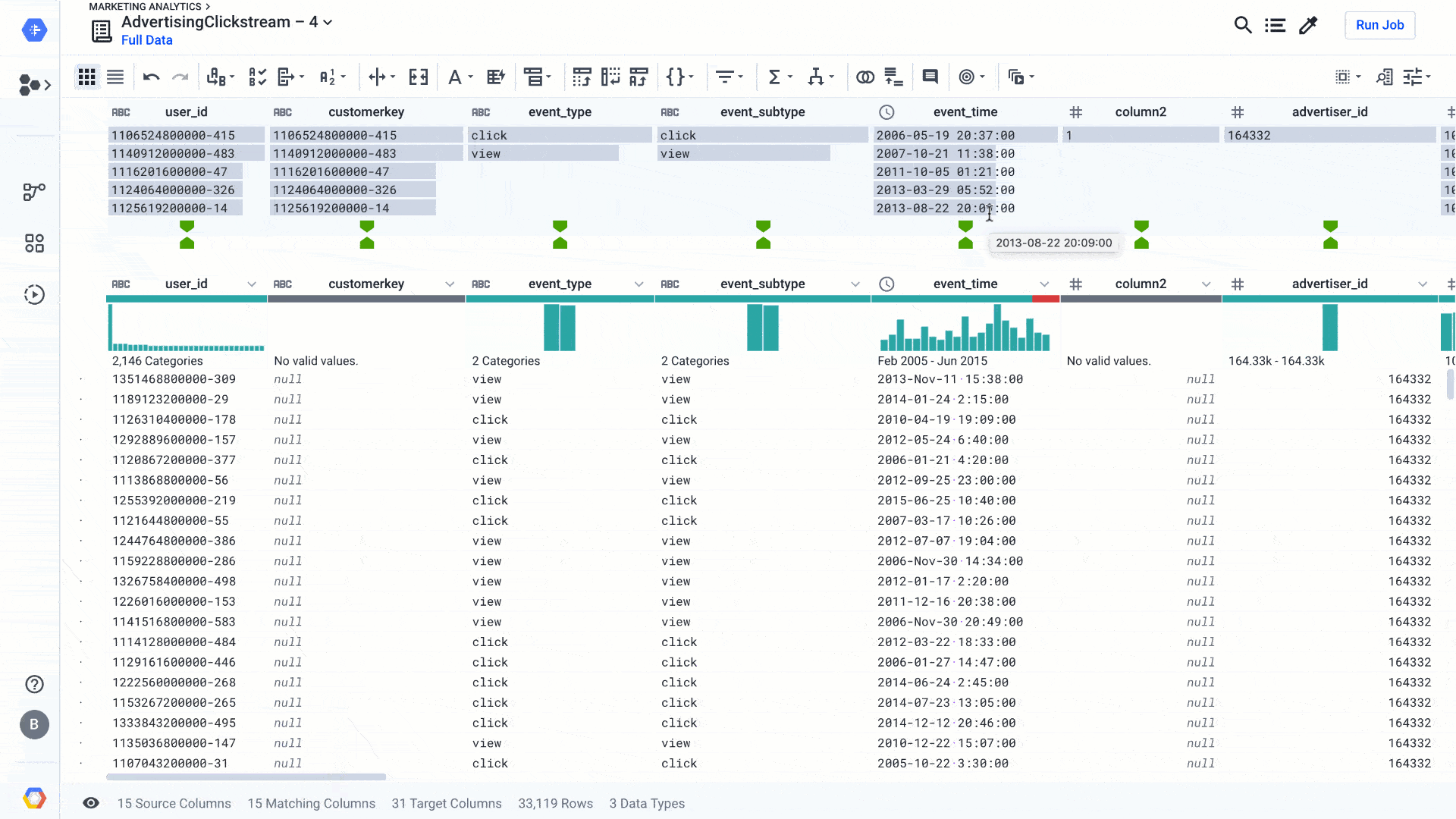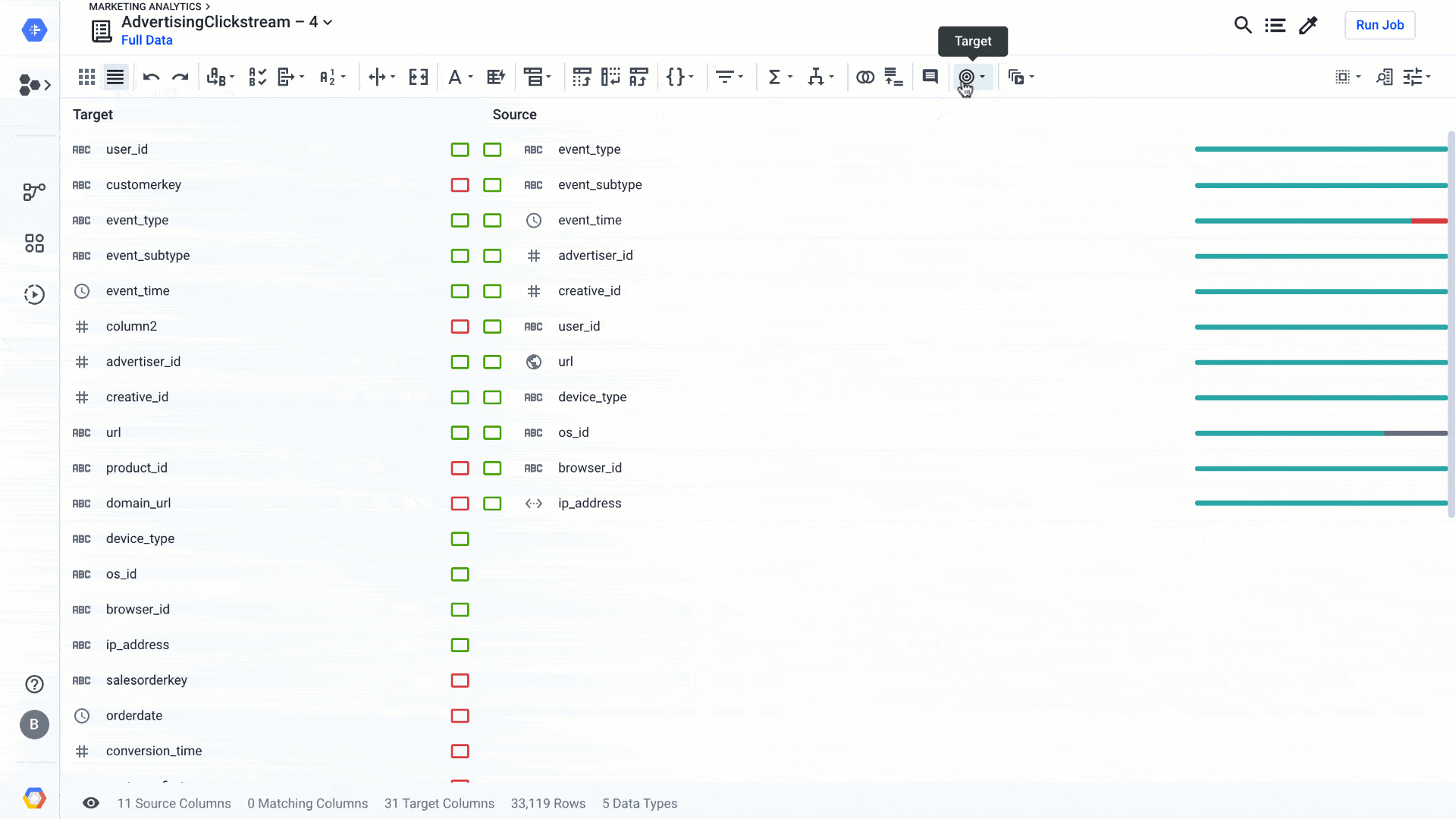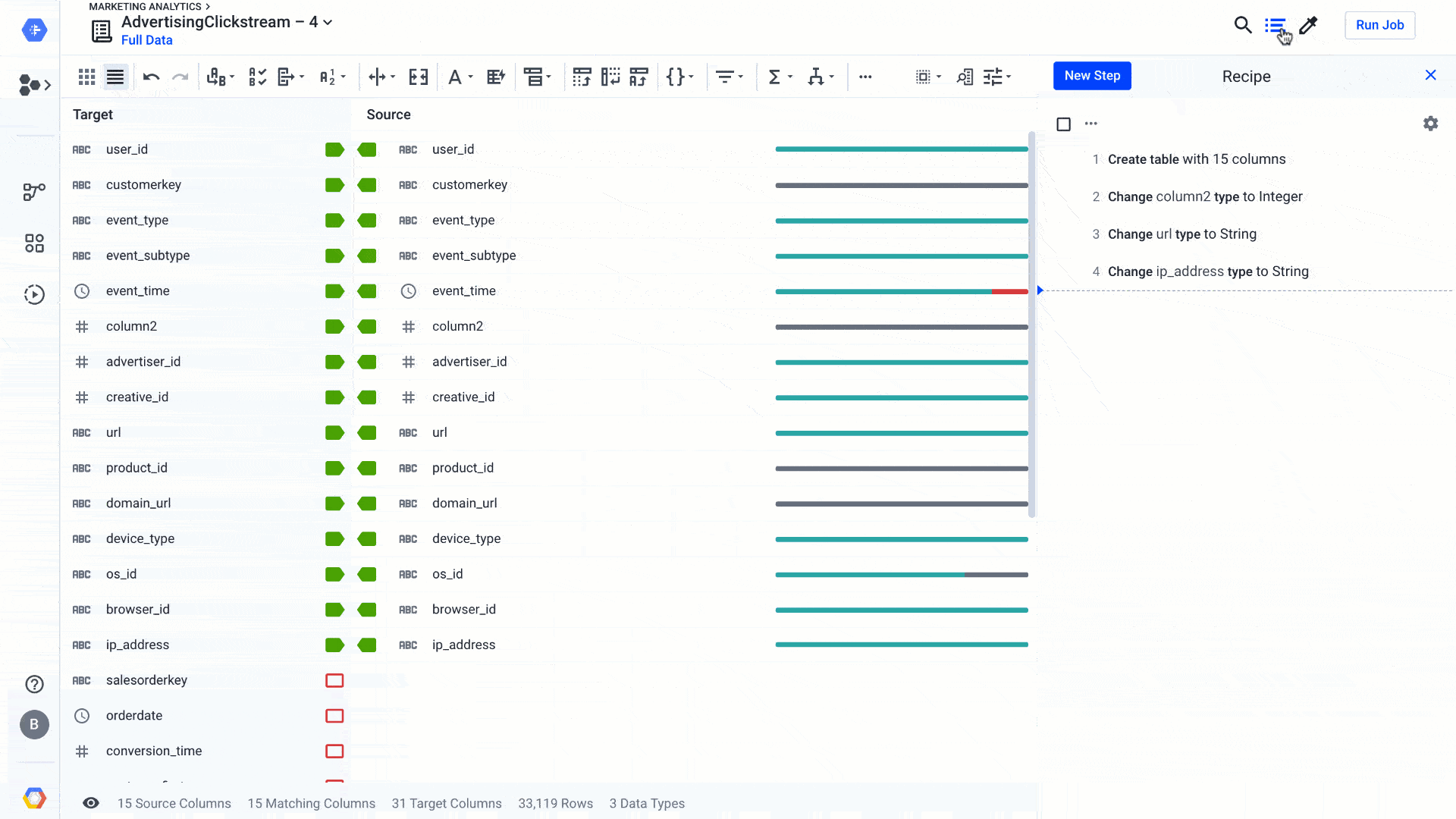
Dataprep suggests best matches between the columns of your recipe and an existing data schema. You can accept it, change it, or go back to your recipe to modify it so the data can match. This is yet another feature that helps load the data warehouse faster, so you can focus on analyzing your data.
Adding local settings and improved date/time interface
When you work on a new data set, the first thing that Dataprep will figure out is the data structure and the data type of each column. Doing so, with the help of some AI algorithms, Dataprep can more easily identify data errors based on expected types and how to clean those types. However, some data types, such as dates or currencies, may be more complicated to infer based on the region you’re located in or the region the data is sourced from. For this particular reason, we’ve added a local setting option (at the project level and user level) so that Dataprep can infer data types—in particular, date and time when there is ambiguity in the data.
For example, in the image below, changing the local setting to France will tell Dataprep to assume the dates should be in a French format, such as dd/mm/yyyy or 10-Mars-2020. The inference algorithms will determine the quality score of the data and the suggestions rules to clean that particular date column in a French format. This makes your job a whole lot easier.
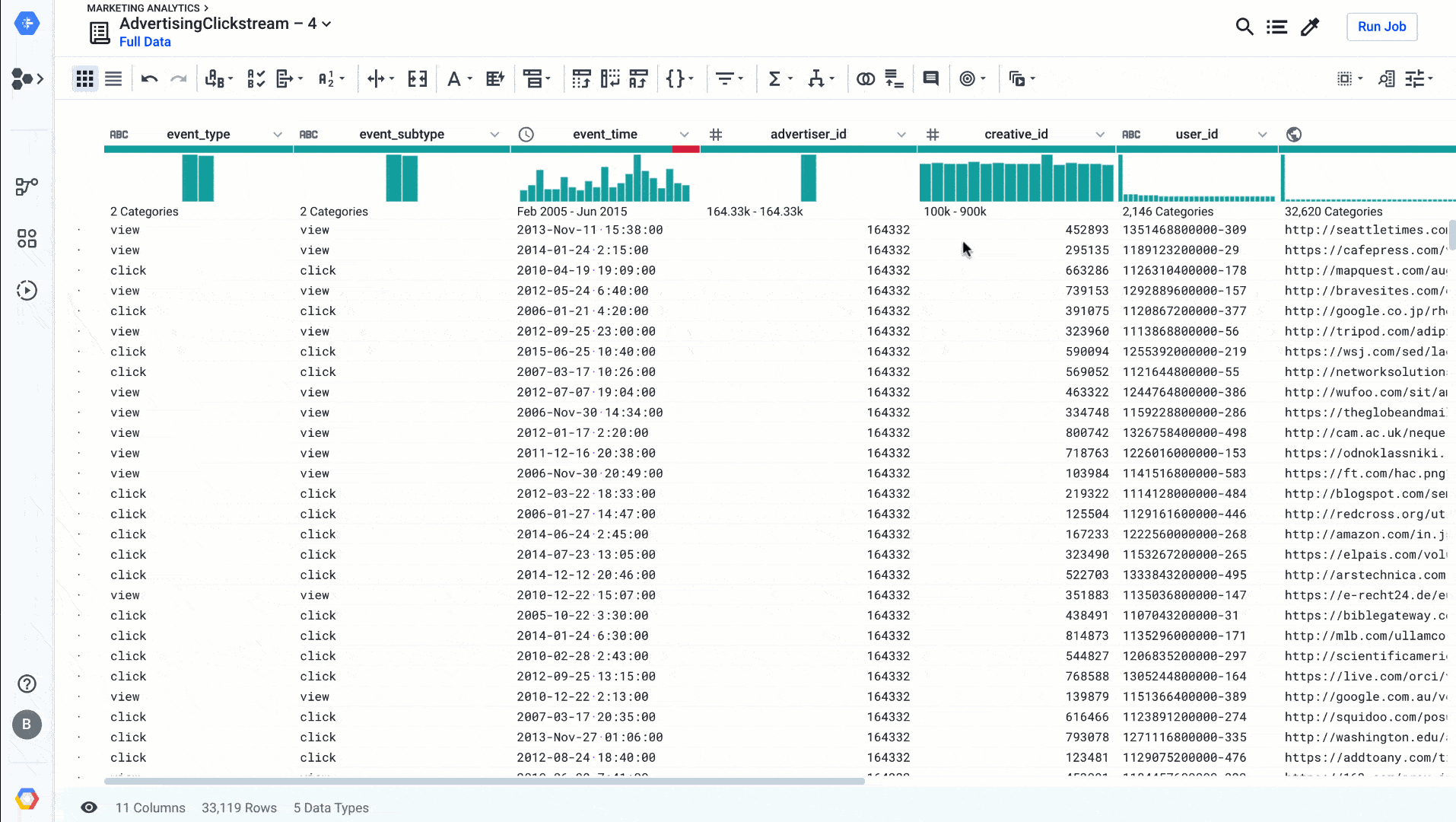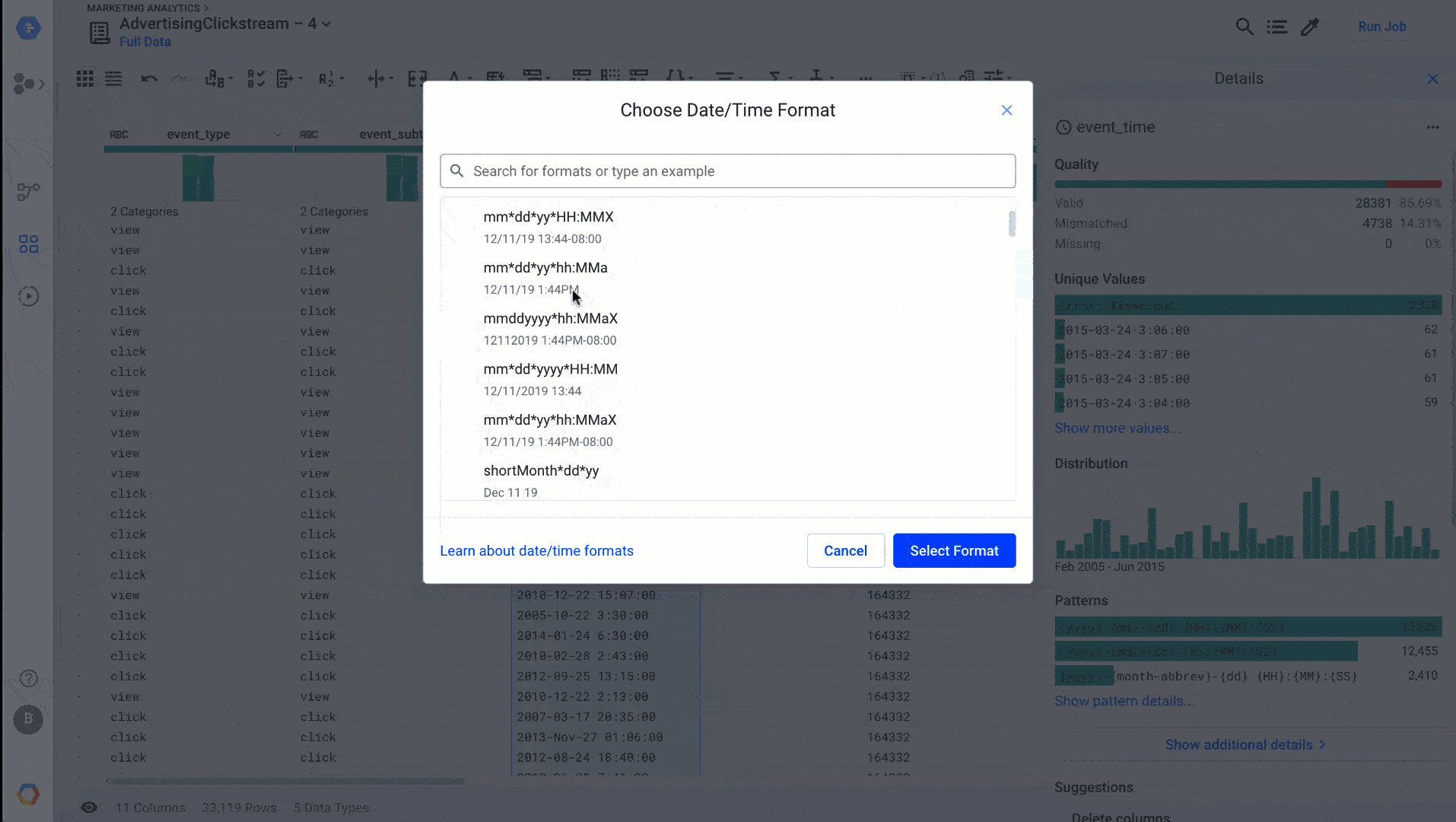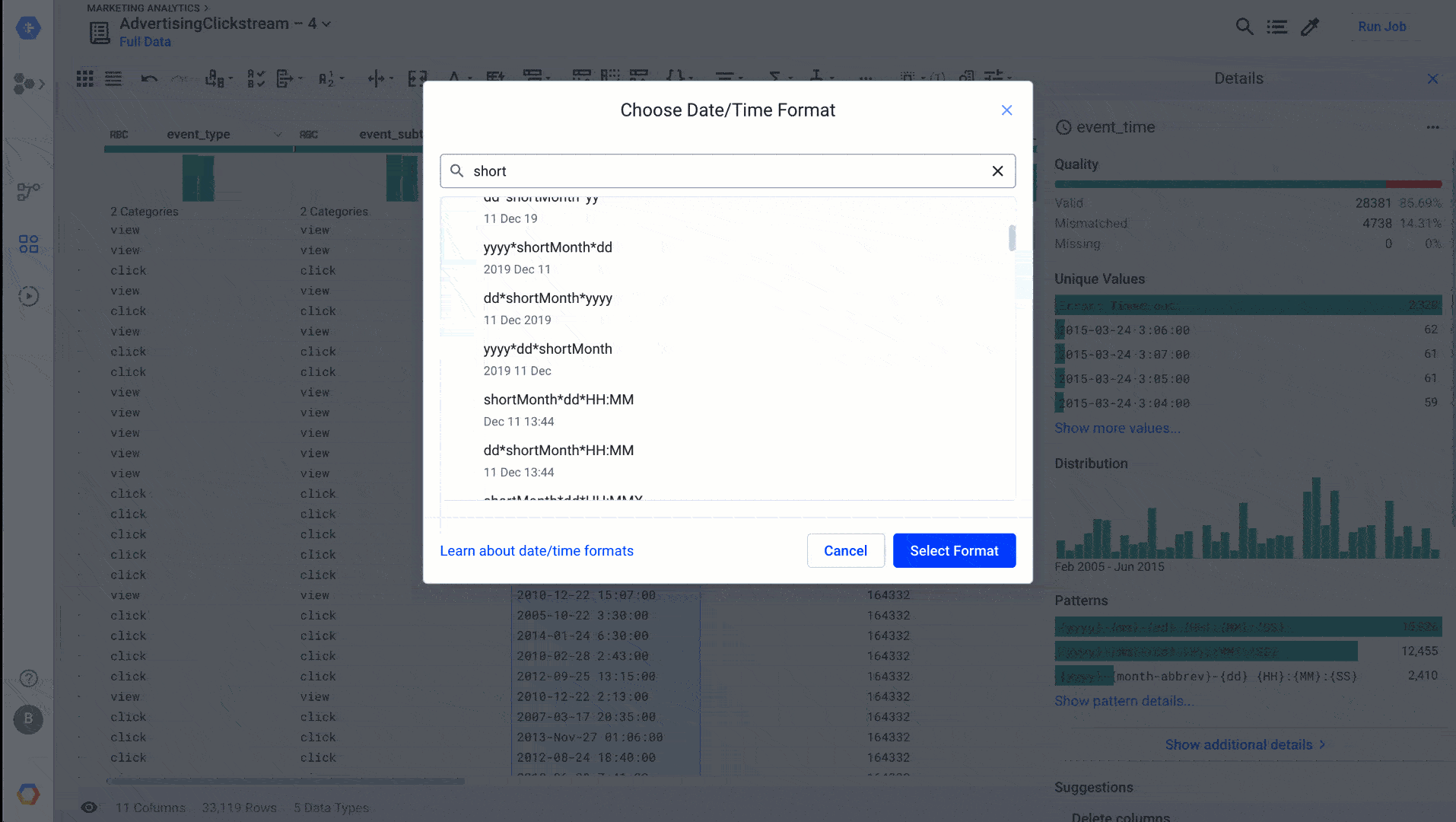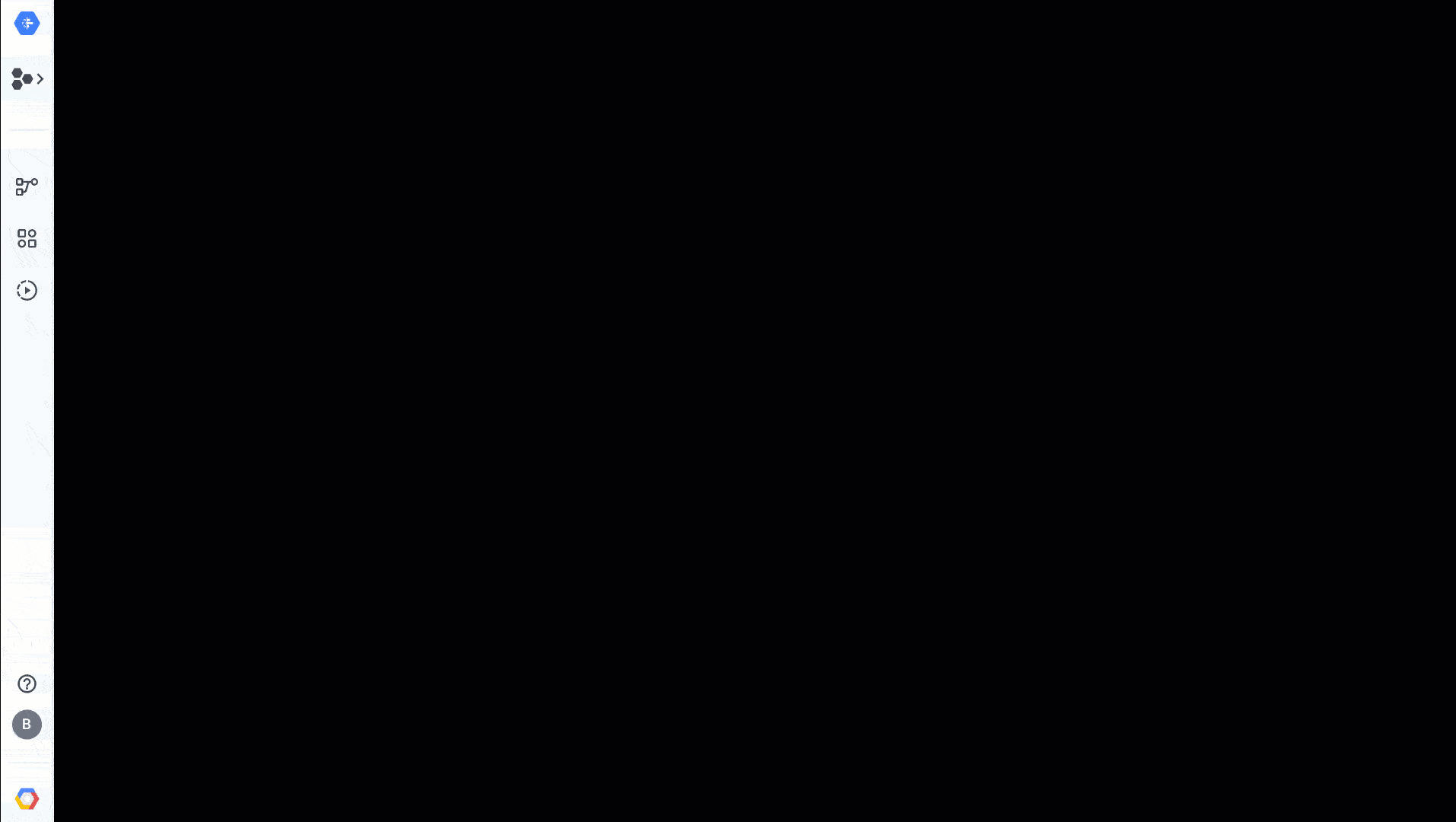
As a bonus to the date type management, we’ve streamlined the date/time data type menu. This new menu makes it far easier to find the exact date/time format you are looking for, letting you search instead of look at a list of 100 values, as shown here:
Increasing cross-project data consistency with macro import/export
As you’re going through your data preparation recipes, you will necessarily surface data pattern issues, such as similar data quality issues and similar ways to resolve them. Sometimes cleaning just one column requires a dozen steps, and you don’t want to rewrite all these steps every time this data issue occurs. That’s what macros are for.
A macro is a sequence of steps that you can use as a single, customizable step in other data preparation recipes. So once you have defined one particular macro to apply data transformations, you can reuse it in other recipes so all your colleagues can benefit from it. This is particularly handy when you open a data lake sandbox and give access to business users to discover and transform data. By providing a set of macros to clean data, you will bring consistency across users, and if the data evolves you can also evolve the macros accordingly.
With this new ability to import and export macros, you can maintain consistency across all of your Dataprep deployments across departments or stages of your projects (i.e., dev, test, production), create backups, and create an audit trail for your macros. You can also post or use existing macros from the Wrangler Exchange community, and build up a repository of commonly used macros, extending the flexibility of Dataprep’s Wrangle language.

There are many more features that have been added to Dataprep, such as downloadable profile results, new trigonometry and statistical functions, shortcuts options, and many more. You can check them out in the release notes and learn more about Dataprep.
Happy wrangling!


