Moving to Log Analytics for BigQuery export users
Roy Arsan
Cloud Solutions Architect, Google
If you’ve already centralized your log analysis on BigQuery as your single pane of glass for logs & events…congratulations! You’re already benefiting from BigQuery’s:
Petabyte-scale cost-effective analytics,
Analyzing heterogeneous data across multi-cloud & hybrid environments,
Running on fully-managed serverless data warehouse with enterprise security features,
Democratizing analytics for everyone using standard familiar SQL with extensions.
With the introduction of Log Analytics (Public Preview), something great is now even better. It leverages BigQuery while also reducing your costs and accelerating your time to value with respect to exporting and analyzing your Google Cloud logs in BigQuery.
This post is for users who are (or are considering) migrating from BigQuery log sink to Log Analytics. We’ll highlight the differences between the two, and go over how to easily tweak your existing BigQuery SQL queries to work with Log Analytics. For an introductory overview of Log Analytics and how it fits in Cloud Logging, see our user docs.
Comparison
When it comes to advanced log analytics using the power of BigQuery, Log Analytics offers a simple, cost-effective and easy-to-operate alternative to exporting to BigQuery with Log Router (using log sink) which involves duplicating your log data. Before jumping into examples and patterns to help you convert your BigQuery SQL queries, let’s compare Log Analytics and Log sink to BigQuery.
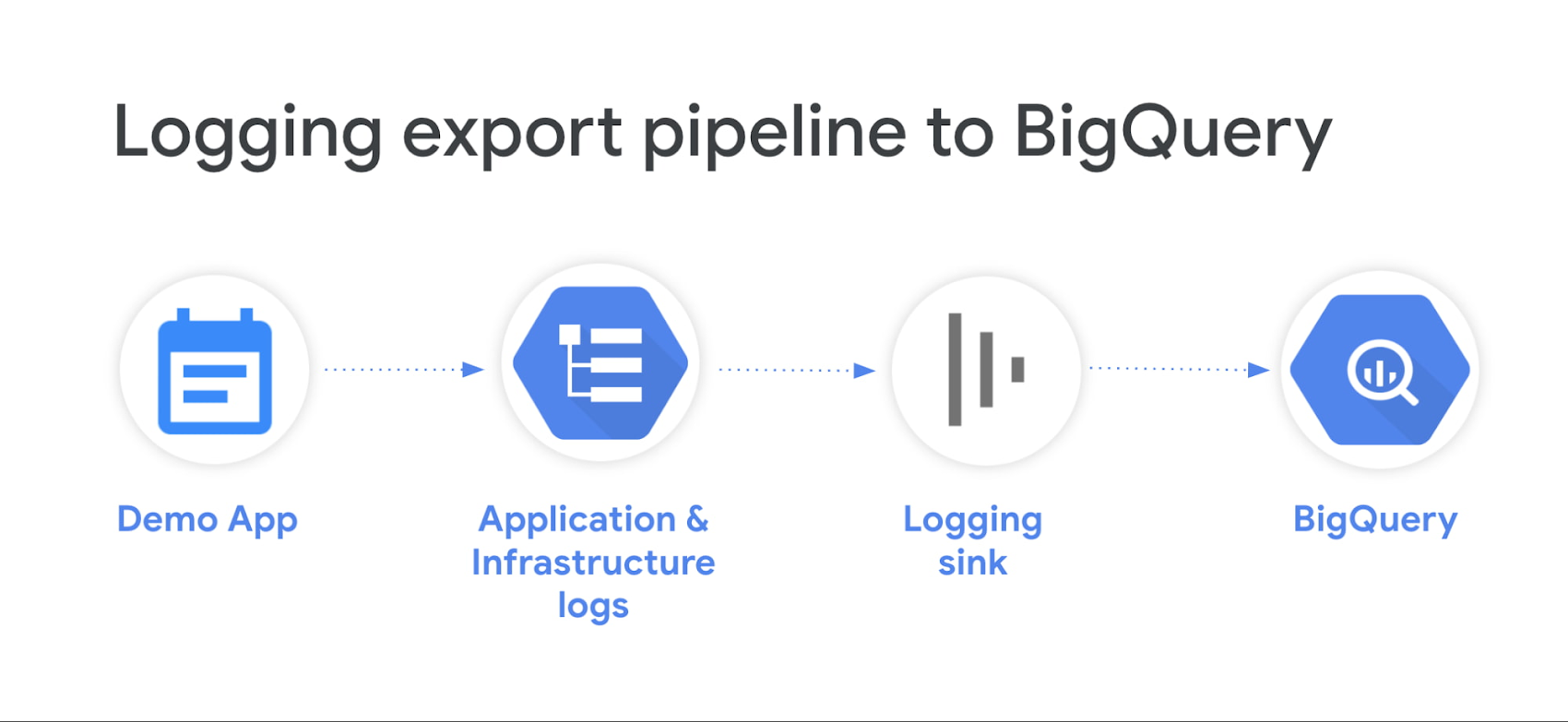
Log sink to BigQuery | Log Analytics | |
Operational Overhead |
|
|
Cost |
|
|
Storage |
|
|
Analytics |
|
|
Security |
|
|
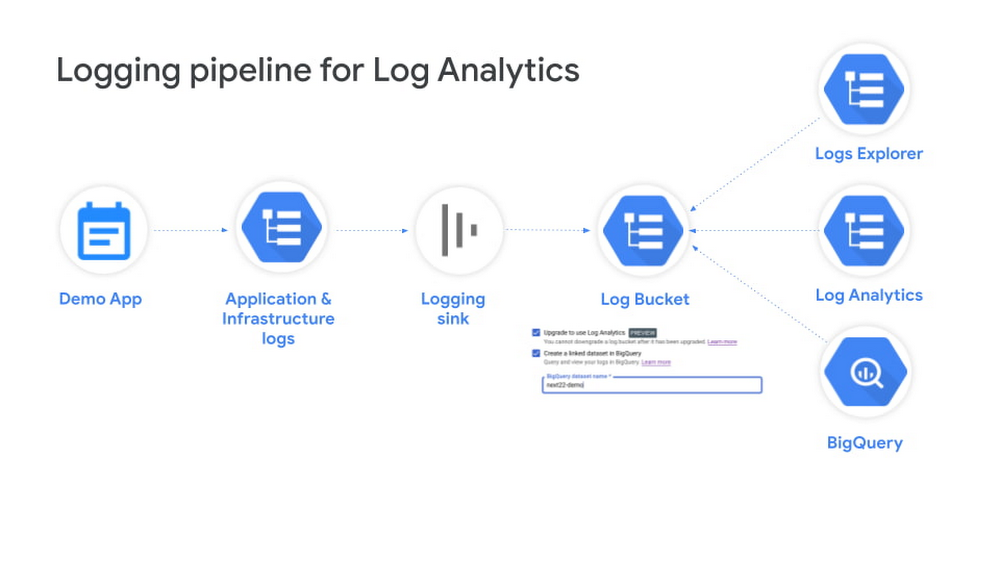
Comparing Log Analytics with traditional log sink to BigQuery
Simplified table organization
The first important data change is that all logs in a Log Analytics-upgraded log bucket are available in a single log view _AllLogs with an overarching schema (detailed in next section) that supports all Google Cloud log types or shapes. This is in contrast to traditional BigQuery log sink where each log entry gets mapped to a separate BigQuery table in your dataset based on the log name, as detailed in BigQuery routing schema. Below are some examples:

The second column in this table assumes your BigQuery log sink is configured to use partitioned tables. If your BigQuery log sink is configured to use date-sharded tables, your queries must also account for the additional suffix (calendar date of log entry) added to table names e.g. cloudaudit_googleapis_com_data_access_09252022.
As shown in the above comparison table, with Log Analytics, you don’t need to know apriori the specific log name nor the exact table name for that log since all logs are available in the same view. This greatly simplifies querying especially when you want to search and correlate across different logs types.
You can still control the scope of a given query by optionally specifying log_id or log_name in your WHERE clause. For example, to restrict the query to data_access logs, you can add the following:
WHERE log_id = "cloudaudit.googleapis.com/data_access"
Unified log schema
Since there’s only one schema for all logs, there’s one superset schema in Log Analytics that is managed for you. This schema is a collation of all possible log schemas. For example, the schema accommodates the different possible types of payloads in a LogEntry (protoPayload, textPayload and jsonPayload) by mapping them to unique fields (proto_payload, text_payload and json_payload respectively):
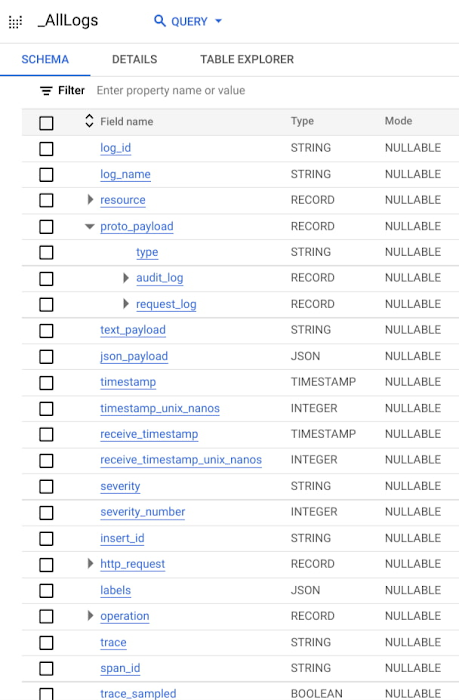
Log field names have also generally changed from camelCase (e.g. logName) to snake_case (e.g. log_name). There are also new fields such as log_id, that is log_id of each log entry.
Another user-facing schema change is the use of native JSON data type by Log Analytics for some fields representing nested objects like json_payload and labels. Since JSON-typed columns can include arbitrary JSON objects, the Log Analytics schema doesn't list the fields available in that column. This is in contrast to traditional BigQuery log sink which has pre-defined rigid schemas for every log type including every nested field. With a more flexible schema that includes JSON fields, Log Analytics can support semi-structured data including arbitrary logs while also making queries simpler, and in some cases faster.
Schema migration guide
With all these table schema changes, how would you compose new or translate your existing SQL queries from traditional BigQuery log sink to Log Analytics?
The following lists side-by-side all log fields and maps them to corresponding column names and types, for both cases of traditional Log sink routing into BigQuery, and the new Log Analytics. Use this table as a migration guide to help you identify breaking changes, properly reference the new fields and methodically migrate your existing SQL queries (See full mapping table here):
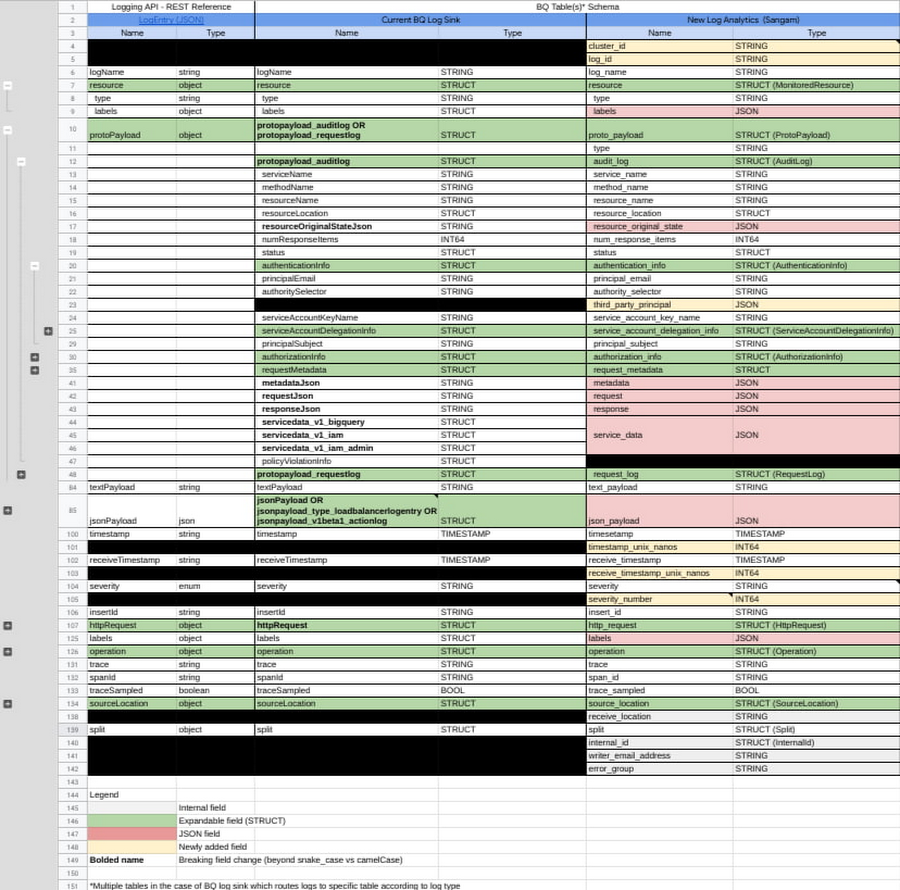
All fields with breaking changes are bolded to make it visually easier to track where changes are needed. For example, if you’re querying audit logs, you’re probably referencing and parsing protopayload_auditlog STRUCT field. Using the schema migration table above, you can see how that field now maps to proto_payload.audit_log STRUCT field with Log Analytics.
Notice the newly added fields are marked in yellow cells and the JSON-converted fields are marked in red cells.
Schema changes summary
Based on the above schema migration guide, there are 5 notable breaking changes (beyond the general column name change from camelCase to snake_case):
1) Fields whose type changed from STRING to JSON (highlighted in red above):
metadataJsonrequestJsonresponseJsonresourceOriginalStateJson
2) Fields whose type changed from STRUCT to JSON (also highlighted in red above):
labelsresource.labelsjsonPayloadjsonpayload_type_loadbalancerlogentryprotopayload_auditlog.servicedata_v1_bigqueryprotopayload_auditlog.servicedata_v1_iamprotopayload_auditlog.servicedata_v1_iam_admin
3) Fields which are further nested:
protopayload_auditlog(nowproto_payload.audit_log)protopayload_requestlog(nowproto_payload.request_log)
4) Fields which are coalesced into one:
jsonPayload(nowjson_payload)jsonpayload_type_loadbalancerlogentry(nowjson_payload)jsonpayload_v1beta1_actionlog(nowjson_payload)
5) Other fields with type changes:
httpRequest.latency(from FLOAT to STRUCT)
Query migration patterns
For each of these changes, let’s see how your SQL queries should be translated. Working through examples, we highlight below SQL excerpts and provide a link to complete SQL query in Community Security Analytics (CSA) repo for full real-world examples. In the following examples:
‘Before’ refers to SQL with traditional BigQuery log sink, and
‘After’ refers to SQL with Log Analytics
Pattern 1: Referencing nested field from a STRING column now turned into JSON:
This pertains to some of the fields highlighted in red in the schema migration table, namely:
metadataJsonrequestJsonresponseJsonresourceOriginalStateJson
Before:
JSON_VALUE(protopayload_auditlog.metadataJson, '$.violationReason')
After:
JSON_VALUE(proto_payload.audit_log.metadata.violationReason)
Real-world full query: CSA 1.10
Before:
JSON_VALUE(protopayload_auditlog.metadataJson, '$.ingressViolations[0].targetResource')
After:
JSON_VALUE(proto_payload.audit_log.metadata.ingressViolations[0].targetResource)
Real-world full query: CSA 1.10
Pattern 2: Referencing nested field from a STRUCT column now turned into JSON:
This pertains to some of the fields highlighted in red in the schema migration table, namely:
labelsresource.labelsjsonPayloadjsonpayload_type_loadbalancerlogentryprotopayload_auditlog.servicedata*
Before:
jsonPayload.connection.dest_ip
After:
JSON_VALUE(jsonPayload.connection.dest_ip)
Real-world full query: CSA 6.01
Before:
resource.labels.backend_service_name
After:
JSON_VALUE(resource.labels.backend_service_name)
Real-world full query: CSA 1.20
Before:
jsonpayload_type_loadbalancerlogentry.statusdetails
After:
JSON_VALUE(json_payload.statusDetails)
Real-world full query: CSA 1.20
Before:
protopayload_auditlog.servicedata_v1_iam.policyDelta.bindingDeltas
After:
JSON_QUERY_ARRAY(proto_payload.audit_log.service_data.policyDelta.bindingDeltas)
Real-world full query: CSA 2.20
Pattern 3: Referencing fields from protoPayload:
This pertains to some of the bolded fields in the schema migration table, namely:
protopayload_auditlog(nowproto_payload.audit_log)protopayload_requestlog(nowproto_payload.request_log)
Before:
protopayload_auditlog.authenticationInfo.principalEmail
After:
proto_payload.audit_log.authentication_info.principal_email
Real-world full query: CSA 1.01
Pattern 4: Referencing fields from jsonPayload of type load balancer log entry:
Before:
jsonpayload_type_loadbalancerlogentry.statusdetails
After:
JSON_VALUE(json_payload.statusDetails)
Real-world full query: CSA 1.20
Pattern 5: Referencing latency field in httpRequest:
Before:
httpRequest.latency
After:
http_request.latency.nanos / POW(10,9)
Conclusion
With Log Analytics, you can reduce the cost and complexity of log analysis, by moving away from self-managed log sinks and BigQuery datasets, into Google-managed log sink and BigQuery dataset while also taking advantage of faster and simpler querying. On top of that, you also get the features included in Cloud Logging such as the Logs Explorer for real-time troubleshooting, logs-based metrics, log alerts and Error Reporting for automated insights.
Armed with this guide, switching to use Log Analytics for log analysis can be easy. Use the above schema migration guide and apply the 5 prescriptive migration patterns, to help you convert your BigQuery SQL log queries or to author new ones in Log Analytics.


