Leveraging streaming analytics for actionable insights with gen AI and Dataflow
Kfir Naftali
Customer Engineer - Data and Analytics specialist, Google
Dori Rabin
Customer Engineer - Data and Analytics specialist, Google
In recent years, there’s been a surge in the adoption of streaming analytics for a variety of use cases, for instance predictive maintenance to identify operational anomalies, and online gaming — creating player-centric games by optimizing experiences in real-time. At the same time, the rise of generative AI and large language models (LLMs) that are capable of generating and understanding text, has led us to explore new ways to combine the two to create innovative solutions.
In this blog post, we showcase how to get real-time LLM insights in an easy and scalable way using Dataflow. Our solution applies to a gameroom chat, but it could be used to gain insights into a variety of other types of data, such as customer support chat logs, social media posts, and product reviews — any other domain where real-time communication is prevalent.
Game chats: a goldmine of information
Consider a company seeking real-time insights from chat messages. A key challenge for many companies is understanding users’ evolving jargon and acronyms. This is especially true in the gaming industry, where “gg” means “good game” or “g2g” means “got to go.” The ideal solution would adapt to this linguistic fluidity without requiring pre-defined keywords.
For our solution, we looked at anonymized data from Kaggle of gamers chatting while playing Dota 2, conversing freely with one another via short text messages. Their conversations were nothing short of gold in our eyes. From gamers' chats with one another, we identified an opportunity to quickly detect ongoing connection or delay issues, and by that ensure good quality of service (QoS). Similarly, gamers often talk about missing items such as tokens or game weapons, information we can also leverage to improve the gaming experience and its ROI.
At the same time, whatever solution we built had to be easy and quick to implement!
Solution components
The solution we built includes industry-leading Google Cloud data analytics and streaming tools, plus open-source gaming data and an LLM.
- BigQuery stores the raw data and holds detection alerts.
- Pub/Sub, a Google Cloud serverless message bus, is used to decouple the streamed chat messages and the Dataflow pipeline.
- Dataflow, a Google Cloud managed service for building and running the distributed data processing pipeline, relies on the Beam RunInference transform for a simple and easy-to-use interface for performing local and remote inference.
- The DOTA 2 game chat dataset is taken from Kaggle -G game chats raw data.
- Google/Flan-T5 is the LLM model used for detection based on the prompt. It is hosted in Hugging Face.
Once we settled on the components, we had to choose the right prompt for the specific business use case. In this case, we settled on game chats latency detection.
We analyzed our gaming data, looking for keywords such as connection, delay, latency, lag, etc.
Example:
The following game id came up:
Here, we spotted a lot of lag and server issues:
After a few SQL query iterations, we managed to tune the prompt in such a way that the true positive was high enough to raise a detection alert, but agnostic enough to spot delay issues without providing specific keywords.
"Answer by [Yes|No] : does the following text, extracted from gaming chat room, can indicate a connection or delay issue : "
Our next challenge was to create a Dataflow pipeline that seamlessly integrated two key features:
-
Dynamic detection prompts: Users must be able to tailor detection prompts for diverse use cases, all while the pipeline is up and running — without writing any code.
-
Seamless model updates: We needed a way to swap in a better-trained model without interrupting the pipeline's operation, ensuring continuous uptime — again, without writing any code.
To that end, we chose to use the Beam RunInference transform.
RunInference offers numerous advantages:
-
Data preprocessing and post-processing are encapsulated within the RunInference function and treated as distinct stages in the process. Why is this important? RunInference effectively manages errors associated with these stages and automatically extracts them into separate PCollections, enabling seamless handling as demonstrated in the code sample below.
-
RunInference’s automated model refresh mechanism is the watch file pattern. This enables us to update the model and load the newer version without halting and restarting the pipeline.
All with a few lines of code:
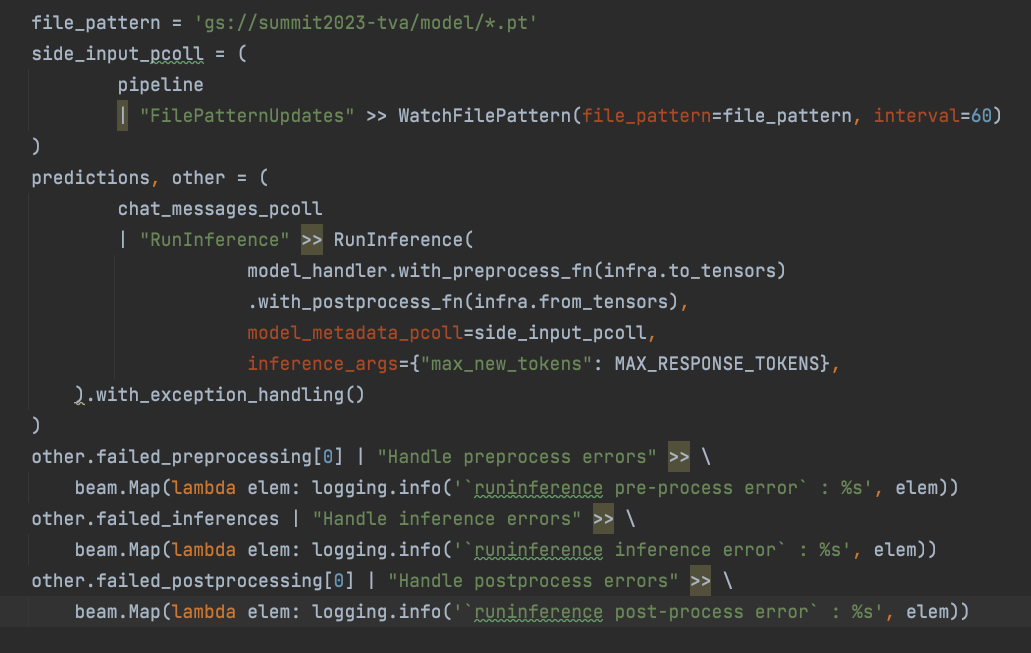
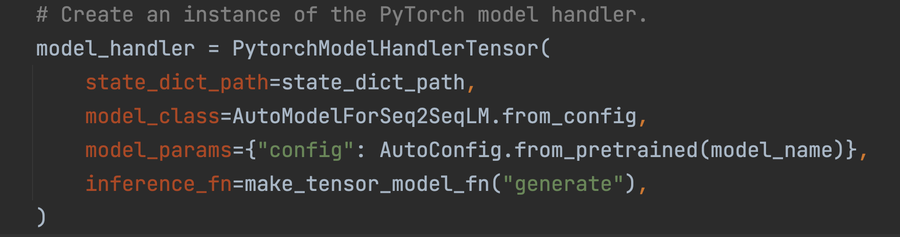
RunInference uses a “ModelHandler” object, which wraps the underlying model and provides a configurable way to handle the used model.There are different types of ModelHandlers; which one you choose depends on the framework and type of data structure that contains the inputs. This makes it a powerful tool and simplifies the building of machine learning pipelines.
Solution architecture
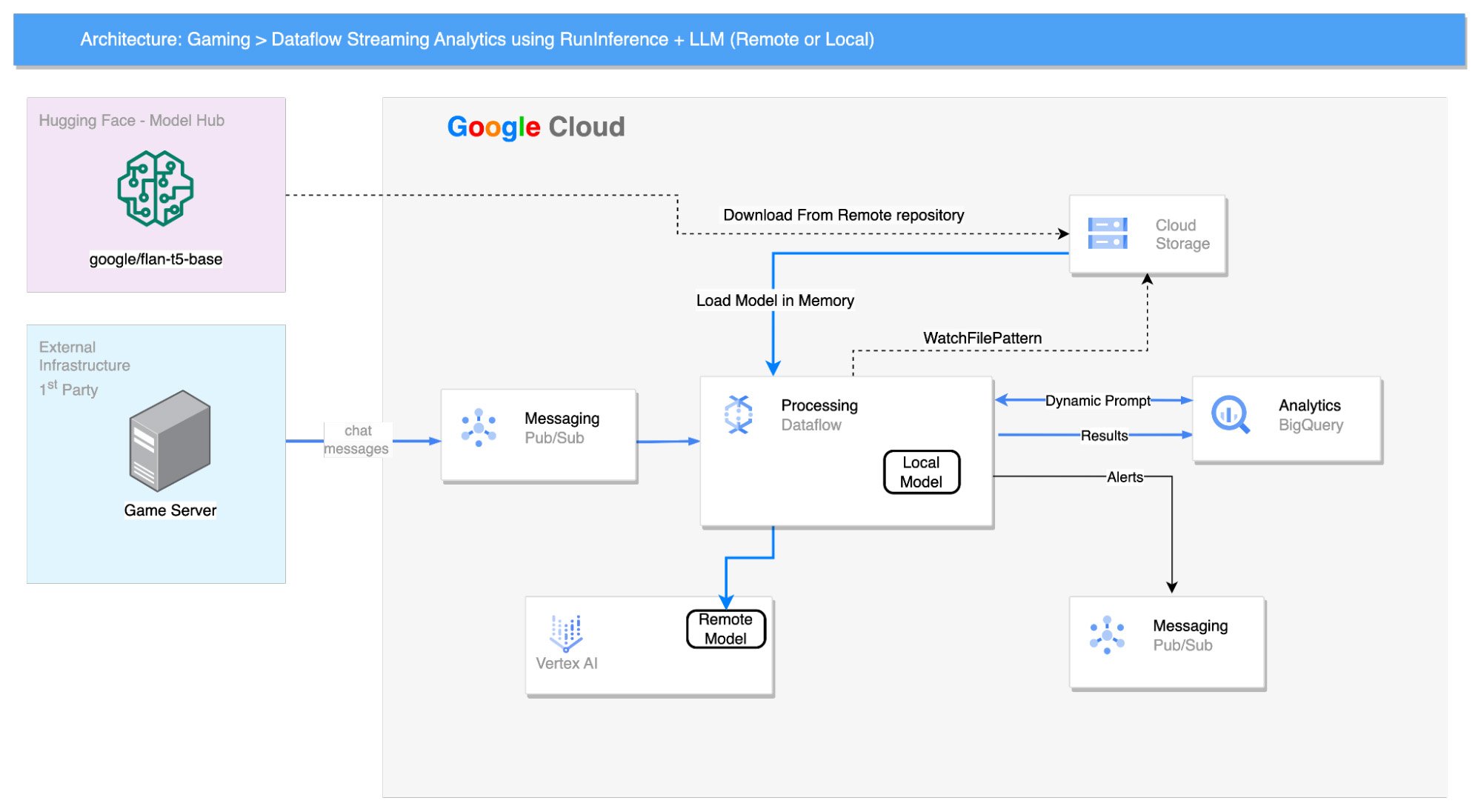
We created a Dataflow pipeline to consume game chat messages from a Pub/Sub topic. In the solution, we simulated the pipeline by reading the data from a BigQuery table and pushed it to the topic.
The Flan-T5 model is loaded into the workers' memory and provided with the following prompt:
"Answer by [Yes|No] : does the following text, extracted from gaming chat room, indicate a connection or delay issue : "
A Beam side input PCollection, read from a BigQuery table, empowers various business detections to be performed within the Beam pipeline.
The model generates a [Yes|No] response for each message within a 60-second fixed window. The number of Yes responses is counted, and if it exceeds 10% of the total number of responses, the window data is stored in BigQuery for further analysis.
Conclusion:
In this blog post, we showcased how to use LLMs with Beam Dataflow's RunInference function to gain insights about gamers chatting amongst themselves.
We used the RunInference transform with a loaded Google/Flan-t5 model to identify anything that indicates a system lag, without giving the model any specific words. In addition, the prompts can be changed in real time and be provided as a side input to the created pipeline. This approach can be used to gain insights into a variety of other types of data, such as customer support chat logs, social media posts, and product reviews.
You can find the source code we used to build this streaming data pipeline in this github repository. Please do not forget to star it if you find it helpful.
Check out the Beam ML Documentation to learn more about integrating ML using the RunInference transform as part of your real-time Dataflow workstreams. For a Google Colab notebook on using RunInference for Generative AI, check out this link.

