Join optimizations with BigQuery primary keys and foreign keys
Abdullah Alamoudi
Software Engineer
Zewen Zhang
Software Engineer
BigQuery is a completely serverless and cost-effective enterprise data warehouse that works across clouds and scales with your data. User data is stored in BigQuery tables. Every table is defined by a schema that describes the column names, data types, and other information.
Recently, BigQuery introduced Unenforced Primary Key and Foreign Key Constraints. This post is a deep dive into Unenforced Key Constraints and how they may benefit queries in BigQuery.
Defining Constraints
Users can define constraints on a table when creating a table using the CREATE TABLE statement. Constraints can also be added to an existing table using the ALTER TABLE ADD PRIMARY KEY statement or the ALTER TABLE ADD CONSTRAINT statement. Constraints can be dropped using the ALTER TABLE DROP PRIMARY KEY statement or the ALTER TABLE DROP CONSTRAINT statement.
For example, The inventory table from TPC-DS has a composite primary key using the columns (inv_date_sk, inv_item_sk, inv_warehouse_sk), and 3 foreign keys referencing date_dim, item, and warehouse. The following statement can be used to create the table with the constraints:
To add constraints to an existing inventory table, the following ALTER TABLE statement can be used:
The user must use the NOT ENFORCED qualifier when defining constraints as enforcement is not supported by BigQuery at this time.
Table constraints can be viewed in the BigQuery UI in the Key Column.
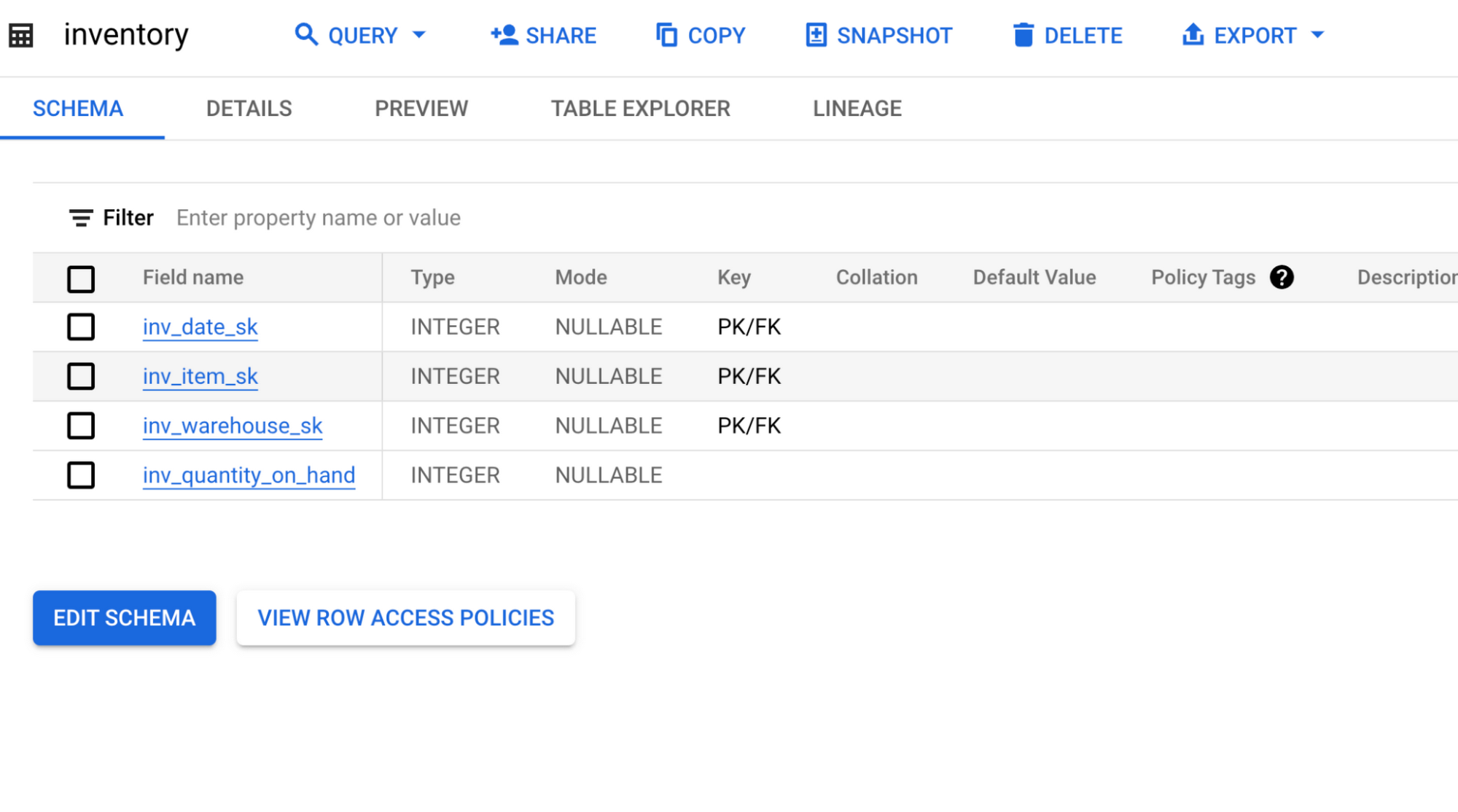
The tooltip shows more information about the keys.
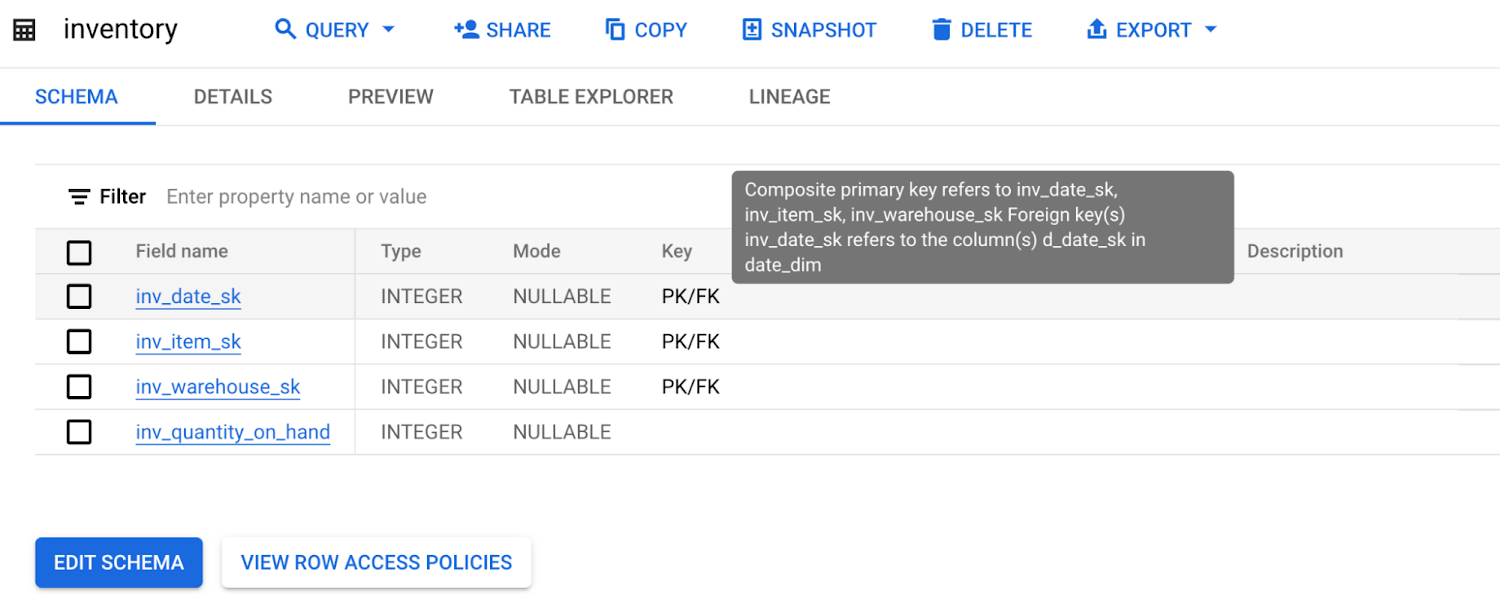
Alternatively, users may query the TABLE_CONSTRAINTS, KEY_COLUMN_USAGE and CONSTRAINTS_COLUMN_USAGE INFORMATION SCHEMA views.
Why create Primary Keys and Foreign Keys?
One may wonder “If Key Constraints are not enforced, why should users create them?”
The answer to this question is that query optimizers may use this information to better optimize queries.
Below, we will discuss three query optimizations that leverage Key Constraints: Inner Join Elimination, Outer Join Elimination and Join Reordering.
Inner Join Elimination
Joins are one of the most expensive operations in databases and a lot of query optimization techniques attempt to optimize them. However, nothing beats completely eliminating joins.
Let’s look at the following tables from the TPC-DS schema:
The store_sales table is one of the fact tables in the dataset. It has a composite primary key (ss_item_sk, ss_ticket_number) and it references 9 dimension tables:
ss_sold_date_sk references date_dim(d_date_sk)
ss_sold_time_sk references time_dim(t_time_sk)
ss_item_sk references item(i_item_sk)
ss_customer_sk references customer(c_customer_sk)
ss_cdemo_sk references customer_demographics(cd_demo_sk)
ss_hdemo_sk references household_demographics(hd_demo_sk)
ss_addr_sk references customer_address(ca_address_sk)
ss_store_sk references store(s_store_sk)
ss_promo_sk references promotion(p_promo_sk)
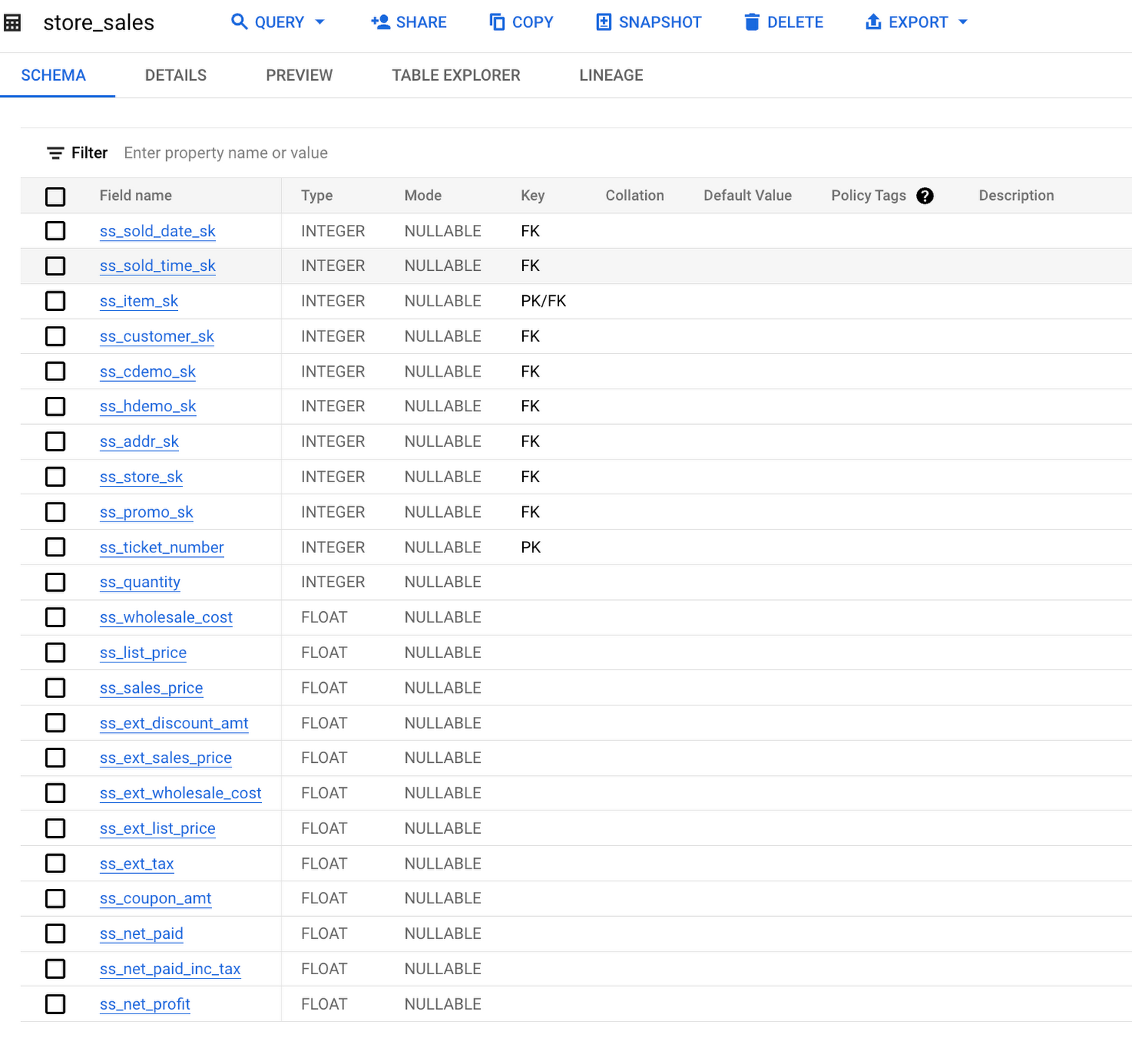
With that information, consider the following query:
The query above only selects columns from the fact table which is joined with the dimension table using columns that form a referential relationship.
Using the constraints, we know that each row in store_sales will have a single match in customer or will have no match if ss_customer_sk was NULL. The query optimizer can then eliminate this join when creating the query plan.
Let’s run the query first without defining the constraints and look at the execution plan:
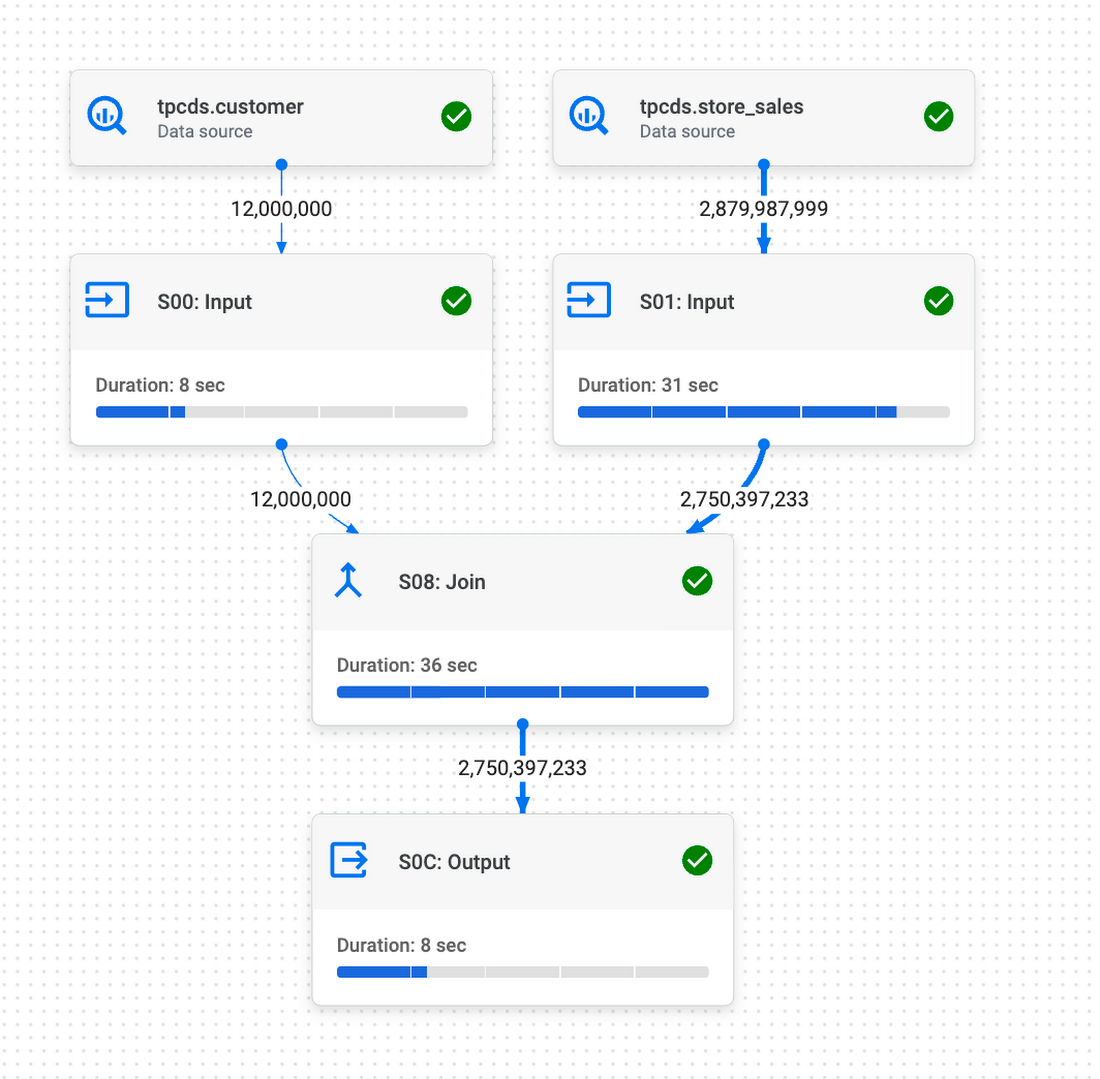
As we can see, the query contains a single join between the two tables.
Let’s define the constraints and run the query again. We now get the following plan:
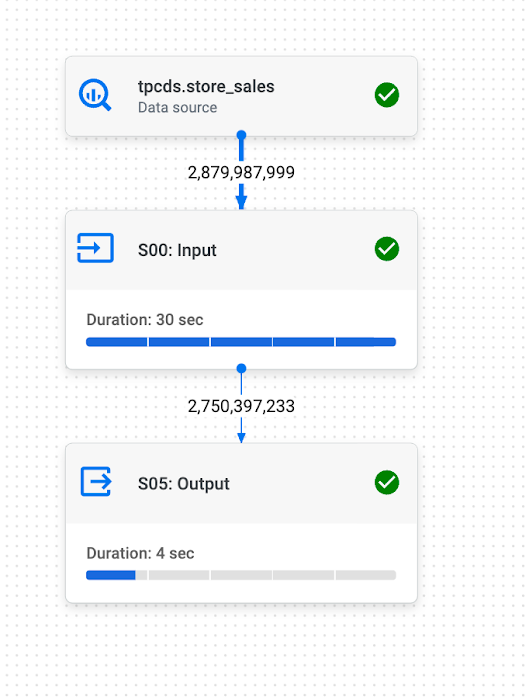
The join has been eliminated and we still got the same result. This was only possible due to the presence of the Key Constraints.
Outer Join Elimination
Removing outer joins has fewer requirements. To remove a LEFT OUTER JOIN, the join keys on the right side must be unique and only columns from the left side are selected. To remove a RIGHT OUTER JOIN, the join keys on the left side must be unique and only columns from the right side are selected.
The joins can be eliminated in this case since having unique keys guarantees that each row from the other side will have at most one match.
Consider the following query:
There is no relationship between ss_item_sk and c_customer_sk.
Let’s first run the query without defining PK constraints on the customer table. We can see the join in the query plan.
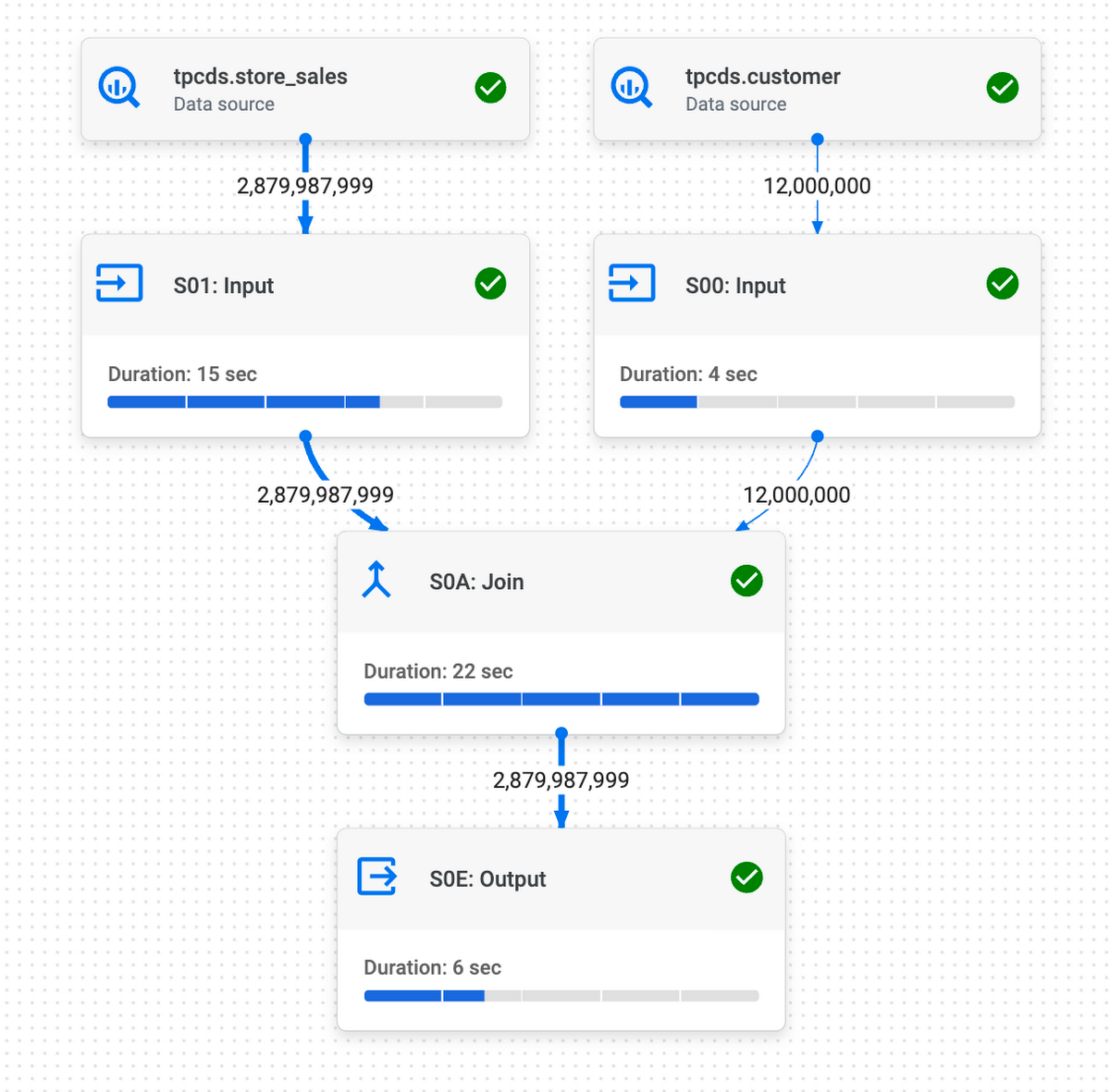
After defining the constraints, we ran the same query and can see that the join has been eliminated.
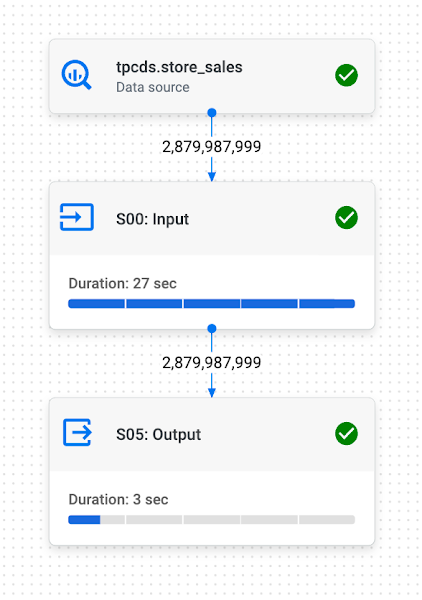
Why would a user write the queries above? Shouldn’t the user remove the joins themselves?
In many production environments, users create views which join many fact and dimension tables.
Developers writing applications query the views instead of querying the tables and writing the joins over and over. Each query that accesses the view selects a different set of columns. When the constraints are defined, the optimizer can limit the tables scanned to the ones that are needed to answer each query.
Join Reordering
When joins can’t be eliminated, the query optimizer uses the Table Constraints to infer information about join cardinalities. The query optimizer may then use this information when performing join reordering.
Let’s look at query 24 of TPC-DS. First, we will run the query without table constraints. In the execution details tab, we can see the elapsed time, the slot time, and the bytes shuffled for the query:
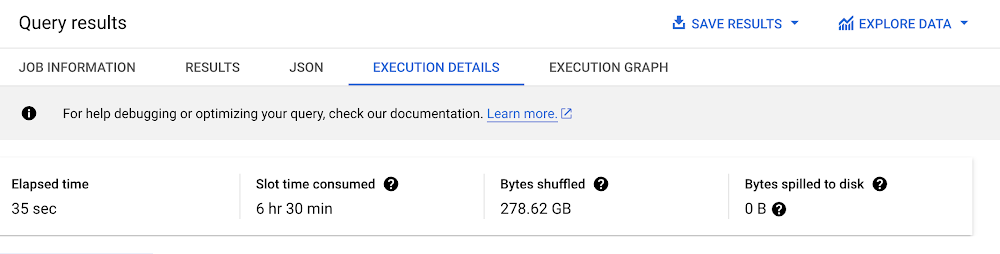
After defining key constraints, we rerun the query and we can see that the improvements in the execution details tab:
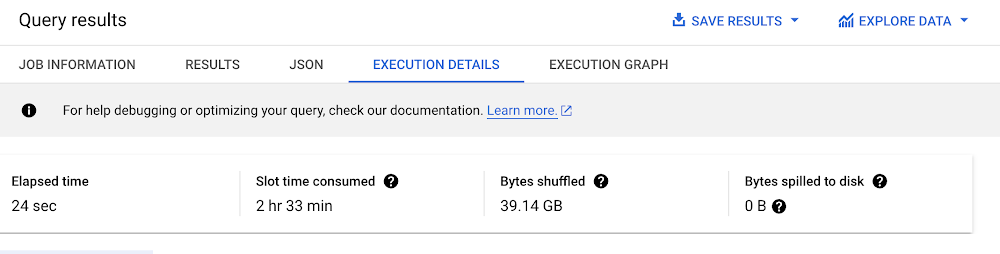
These improvements are due to having a better join ordering for the query. The full plan and the join order can be viewed in the execution graph tab.
User responsibilities
With great power comes great responsibility. Since Key Constraints are not enforced in BigQuery, the user is responsible for maintaining the constraints at all times.
The values of the Primary Key Columns must be unique in all rows and must not have any NULL values.
Each Foreign key must either be null or have a corresponding Primary key row in the referenced table.
If any of these constraints are violated, queries over tables with violated constraints may return incorrect results.
Conclusions
In summary, the BigQuery optimizer can make use of Key Constraints to create better query plans. Such optimizations can lead to major resource savings and faster response times.
To get the benefit of these optimizations, users can define key constraints when creating new tables, and modify their existing tables to add constraints definitions.
Did you know Primary Key Constraints are also used for streaming data from other systems into BigQuery? Check out BigQuery’s Change Data Capture to learn about that functionality.

