How Traveloka built a Data Provisioning API on a BigQuery-based microservice architecture
Imre Nagi
Software Engineer, Data Team, Traveloka
Chairuni Aulia Nusapati
Software Engineer, Data Team, Traveloka
To build and develop an advanced data ecosystem is the dream of any data team, yet that often means understanding how the business will need to store and process that data. As Traveloka’s data engineers, one of our most important obligations is to custom-tailor our data delivery tools for each individual team in our company, so that the business can benefit from the data it generates.
In this blog, we’ll talk about one of our more recent solutions to deliver relevant data to specific business function, our Data Provisioning API. This API’s main function is to deliver big datasets (million of records, GB in size) from our data warehouse to production systems by request.
Background
We built the Data Provisioning API because the previous method by which we used to provide product teams with access to our data warehouse was problematic: previously, when a product team would request data from our data warehouse, we simply gave them the direct read access to the buckets or tables that they needed.
First, this solution forced a tight coupling to the underlying data storage technology and format. When we changed either the technology or the format, the client system would require a tedious update as well. Second, because the access is on a bucket level, we cannot ensure that they do not access the columns that they are not supposed to. Finally, it is hard to do audits, because there are so many ways that end users can read the data: we have no way to know if they are dumping the data elsewhere or simply querying it.
Based on these business-wide issues, we decided to build one standardized way to serve our data, which later became the Data Provisioning API.
Architecture overview
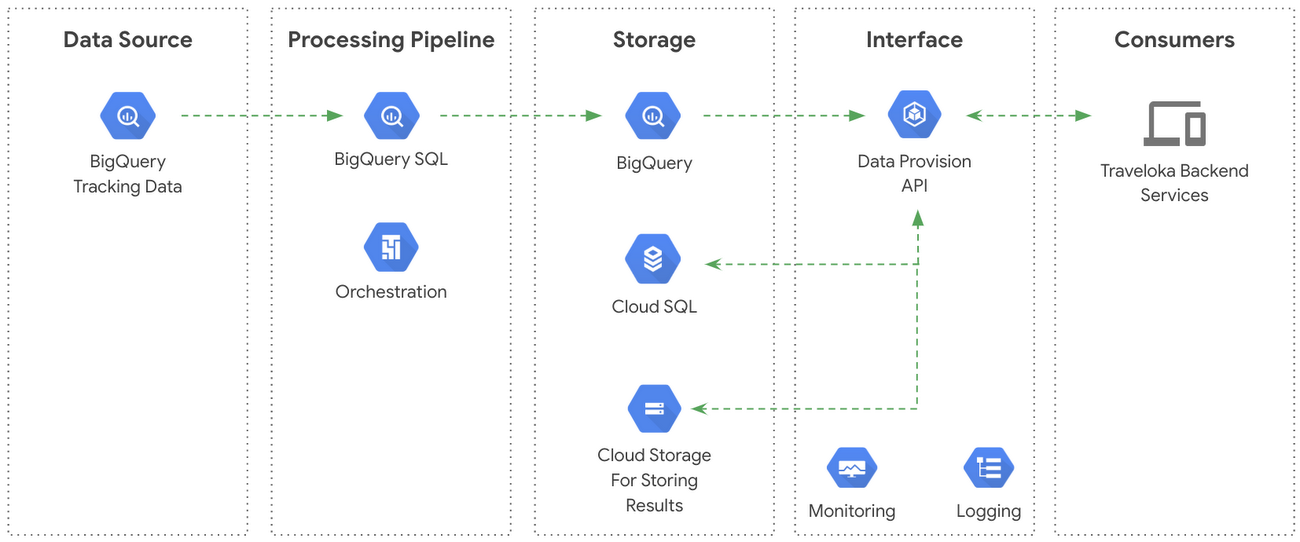
The data source: our BigQuery Data Provisioning API
Traveloka uses BigQuery as the underlying technology for its data warehouse. The warehouse stores an abundance of raw factual and historical data generated from our customers’ activities. In addition to those raw data, we also store processed data as both intermediate and final tables. Those raw and processed data are the main items to be served by the Data Provisioning API.
The job scheduler: Cloud Composer
The Data Provisioning API system uses Cloud Composer to schedule BigQuery queries that transform raw data into summarized and redacted versions for transfer into processed intermediate and final tables. The whole system depends on this scheduler.
Initially, we used a self-managed Airflow scheduling system hosted on Compute Engine instances, but recently we transitioned our schedules to Cloud Composer. Google Cloud had recently released the generally available version of Cloud Composer at time of writing, so we decide to use Composer in order to reduce the overhead of maintaining our self-managed Airflow cluster.
Temporary storage for query results: Cloud Storage
Since the data that the Data Provisioning API serves are huge in size, we decided to store the result in a temporary storage and let our clients retrieve them directly from that location. This simplified our process for sending the result to our clients; it’s all handled by the storage system. We chose to use Cloud Storage as the technology for this storage, because it makes it easy for us to send the query results: we simply create a signed URL for every result and we can apply a retention policy to auto-delete the provisioned data after a period of time.
Service metadata storage: Cloud SQL (for MySQL)
We process requests asynchronously, meaning we do not return the result immediately but instead queue them until our querying resources are free. As a result, we need to have a metadata storage that saves the state of each request, including a link to the result when the processing has finished. We used the Google Cloud SQL (MySQL) to track links, state, and other metadata.
The deployment: Google Kubernetes Engine
The Data Provisioning API is hosted in Kubernetes clusters managed by the Google Kubernetes Engine (GKE). The Kubernetes cluster communicates with Cloud Storage and Cloud SQL to store the results and job metadata of query requested by the user. We’ll explain this aspect in greater detail in the following sections.
How does the Data Provisioning API work?
Here’s how it works from a higher point of view:
- The client creates a request.
- We then ask BigQuery to process a corresponding query.
- When the processing has finished, BigQuery will save the result into a folder in Cloud Storage.
- A signed URL to that Cloud Storage folder is generated and stored in metadata storage.
- Finally, the client can retrieve the result from Cloud Storage using the signed URL.
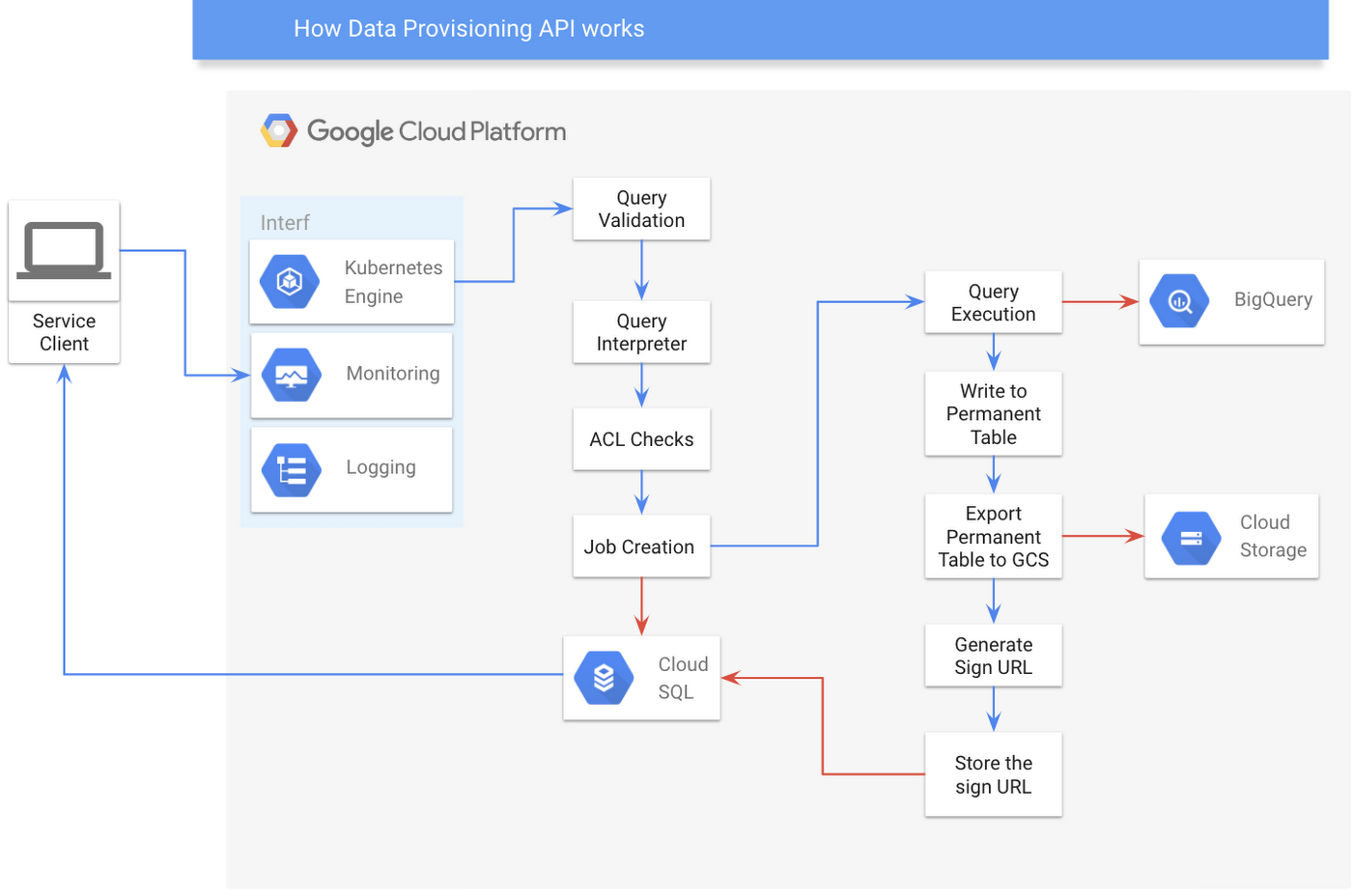
How does exactly the Data Provisioning API work underneath? Well, to explain that, we need to show the two major components building the API: the Query Spec Builder and the Execution Pipeline.
The Query Spec Builder
To begin, a user submits a job containing a JSON-formatted query that specifies the data they want to retrieve under some conditional rules. By accepting simple JSON, we are able to hide the physical data warehouse layer from our users. This JSON format technically should specify one or multiple data source definitions and its corresponding retrieval conditional rules (if any), as specified in our data contract. To provide some context, a data source definition is a definition of what and how multiple datasets or a materialized view should be queried.
Query Spec Builder is an extensible query interpreter that can interpret the JSON query into our own Domain Specific Language (DSL). Later on, we will use this DSL to construct the same query for any of the other database implementations that we use: we merely need to extend the interface we defined earlier. Even though we are currently using BigQuery as our data warehouse, changing our database physical layer eventually will not impact the query created by our user. We also run a query check against our Access Control List (ACL) service in the Query Spec Builder to make sure that the data at a very granular level (up to columnar data) are protected and no data will be provided to unauthorized users.
If the job submission goes well, the server returns job metadata containing a job identifier that the user can later use to check the status of the job, and to retrieve the URL that links to the results.
The Execution Pipeline
Once the job metadata is saved in our metadata storage, Standard SQL constructed from the user’s JSON query will be executed on the BigQuery execution pipeline. We spawn a worker that executes the job in the background. We currently use RXJava to help us maintain the scheduler’s and worker’s life cycles. The RXJava thread will help the worker to finish these consecutive tasks.
Submitting SQL to BigQuery
Retrieving data from BigQuery is easy thanks to its Java API. Using the API’s standard configuration, it returns the data’s iterator, once the job finishes. To read the data, we need to keep iterating over all results from the job. However, we don’t really want to iterate through all the data, especially over exceptionally large datasets. Instead, we want a lightweight service for the end user, while moving all computationally intensive tasks to the query engine. Thus, we decided to write the result into a permanent table.
Extracting the resulting BigQuery table to Cloud Storage
Since we store the query result in a permanent table, we need to export the data from this table into our Cloud Storage bucket so that we can generate a time-limited signed URL later. However, we must be very careful about running this operation. If the data is small enough (less than 1GB), we can immediately store the object into one blob object in our storage. On the other hand, if the result size is larger, we need to use a wildcard to specify the bucket containing the blob objects so that BigQuery can split the result into multiple different files.
Generating a signed URL for objects in Cloud Storage
Once we store the results in Cloud Storage The next step is to deliver them to our end user. It’s clear that giving direct Cloud Storage access to our user is pretty straightforward but not desirable due to the additional requirement of a separate access control list (ACL) for Cloud Storage users. Fortunately, we discovered that Cloud Storage supports the signed URL feature. This is a feature that allows us to give our users a temporary access to objects for a configurable amount of time, even if they don’t have a Google account. Furthermore, the usage of pre-signed URL is not tightly coupled with any cloud vendor.
Conclusion
Our new Data Provisioning API has successfully addressed several problems previously present in our data delivery process. We now have a clear API contract that standardizes the way product teams access our data warehouse. By using our API, product teams no longer access the physical layer, and that helps us to audit the use of our data. We can also flexibly define the access control up to the column level, which ensures that the product team uses only the columns they need. Additionally, the API gives a standard (yet flexible) definition that other teams can use to query the data, so we can restrict how the product teams access our data while still allowing to flexibly run a wide variety of queries.
The API has been used by several business use cases already, and there will be more use cases to come!

