How to deploy data observability with Monte Carlo on Google Cloud
Yang Li
Staff Cloud Solutions Architect, Google Cloud
Michael Segner
Product Marketing, Monte Carlo
Data is increasingly valuable, powering critical dashboards, machine learning applications, and even large language models (LLMs). Conversely, that means every minute of data downtime — the period of time data is wrong, incomplete, or inaccessible — is more and more costly. For example, a data pipeline failure at a digital advertising platform company could result in hundreds of thousands in lost revenue .
Unfortunately, it is impossible to anticipate all the ways data can break with testing, and attempting to maintain a view of inconsistencies across your entire environment would be incredibly time-consuming.
Monte Carlo, a data observability software provider, together with Google Cloud can significantly minimize data downtime by utilizing cutting-edge Google Cloud services for ETL, data warehousing, and data analytics. Combined with the robust capabilities of Monte Carlo’s data observability, you can better detect, resolve, and prevent data incidents on a large scale.
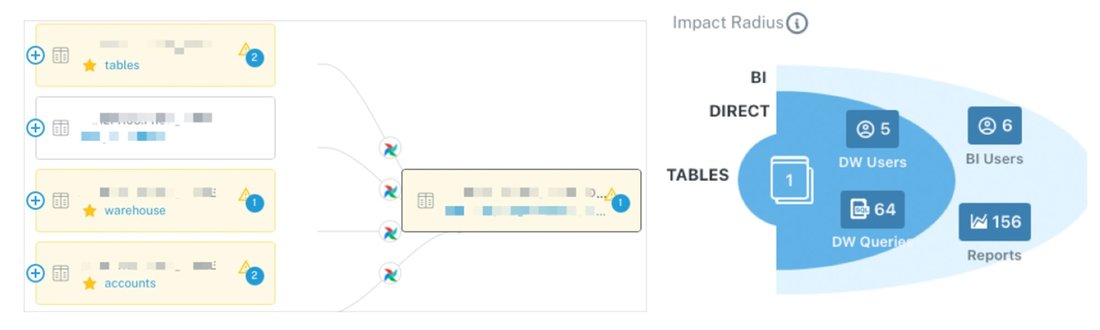
Monte Carlo’s data lineage shows the assets upstream with anomalies that may be related to the volume incident, while Impact Radius shows who will be affected to help inform smart triaging.
This is all enabled by the metadata, access to query logs, and other BigQuery features that help structure your data, as well as the APIs provided by Looker.
This reference architecture enables these key outcomes:
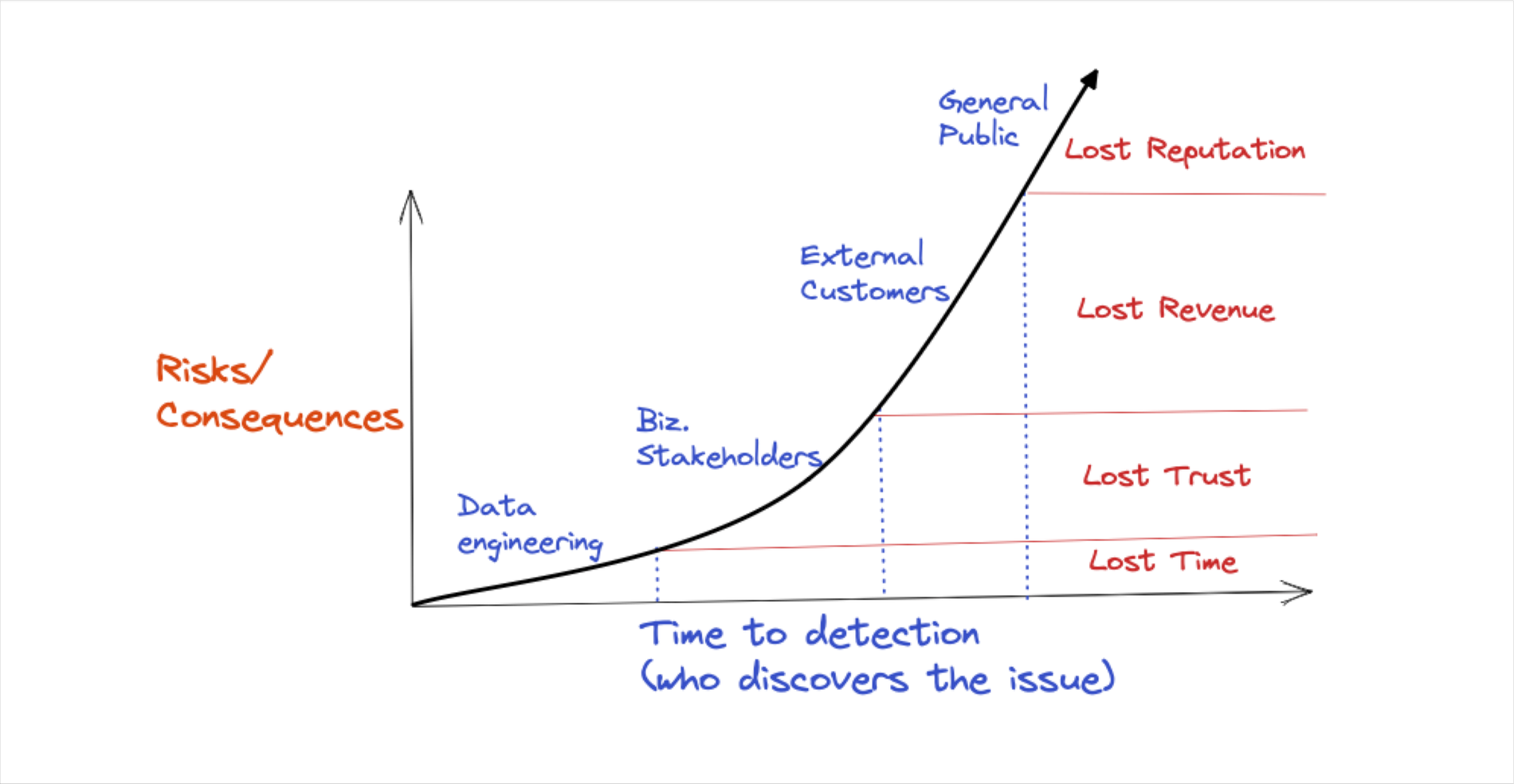
1. Mitigate the risk and impact of bad data: Reducing the number of incidents and improving time-to-resolution lowers the likelihood that bad data will cause negative reputational, competitive, and financial outcomes.
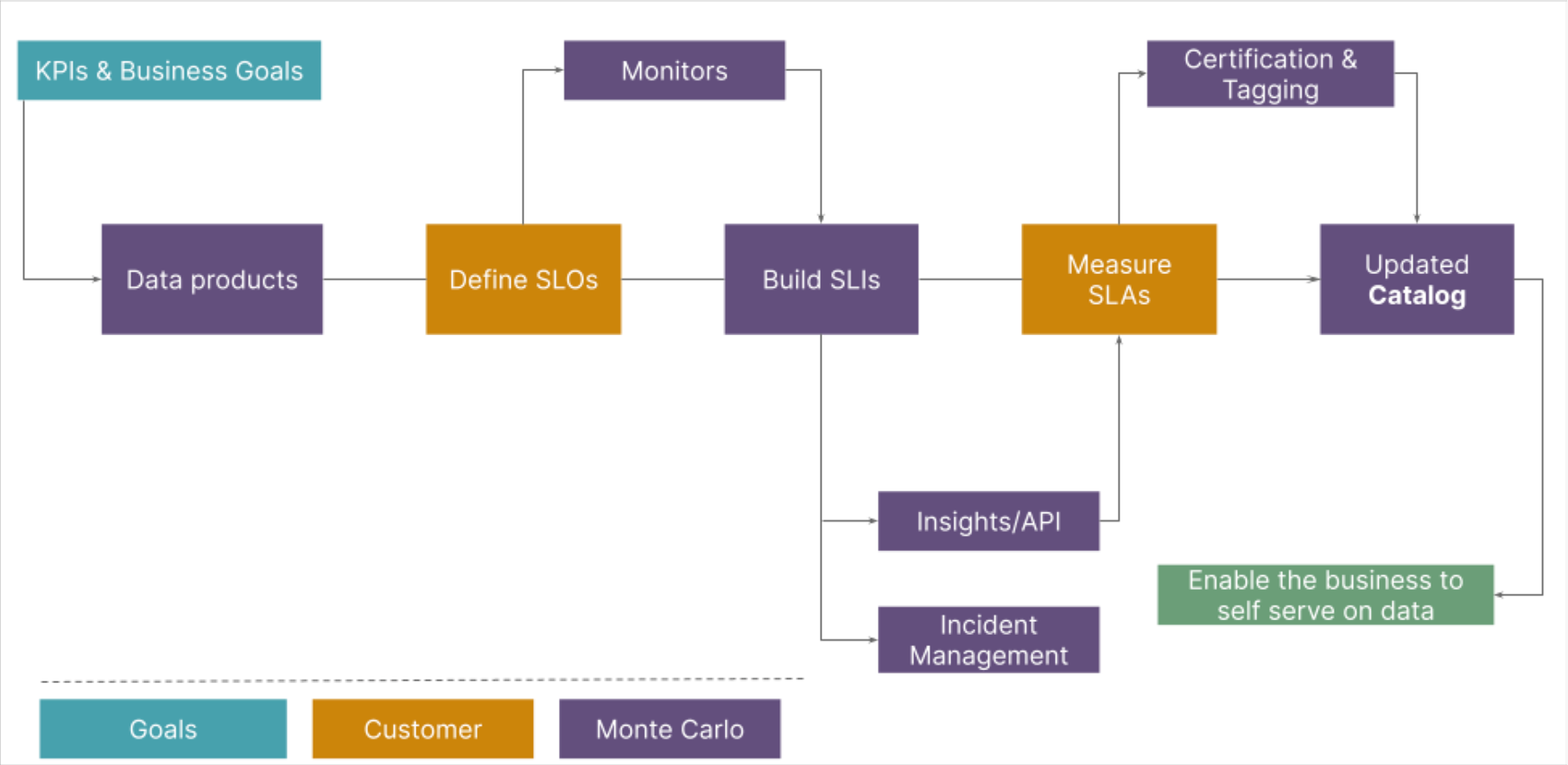
2. Increase data adoption, trust, and collaboration: Catching incidents first, and proactively communicating during the incident management process, helps build data trust and adoption. Data quality monitors and dashboards are the enforcement and visibility mechanisms required for creating effective, proactive data SLAs.
3. Reduce the time and resources spent on data quality: Studies show data teams average 30% or more of their workweek on data quality and other maintenance related tasks rather than tasks to unlock additional value from data and data infrastructure investments. Data observability reduces the amount of time data teams need to scale their data quality monitoring as well as resolving incidents.
4. Optimize the performance and cost of data products: When data teams move fast, they build “pipeline debt” over time. Slow-running data pipelines utilize excess compute, cause data quality issues, and create a poor user experience for data consumers, who must wait for data to return, dashboards to load, and AI models to update.
Architecture
Monte Carlo recently expanded to a hybrid-SaaS offering using native Google Cloud technologies. The following diagram shows a Google-Cloud-hosted agent and datastore architecture for connecting BigQuery, Looker, and other data pipeline solutions to your Monte Carlo platform.
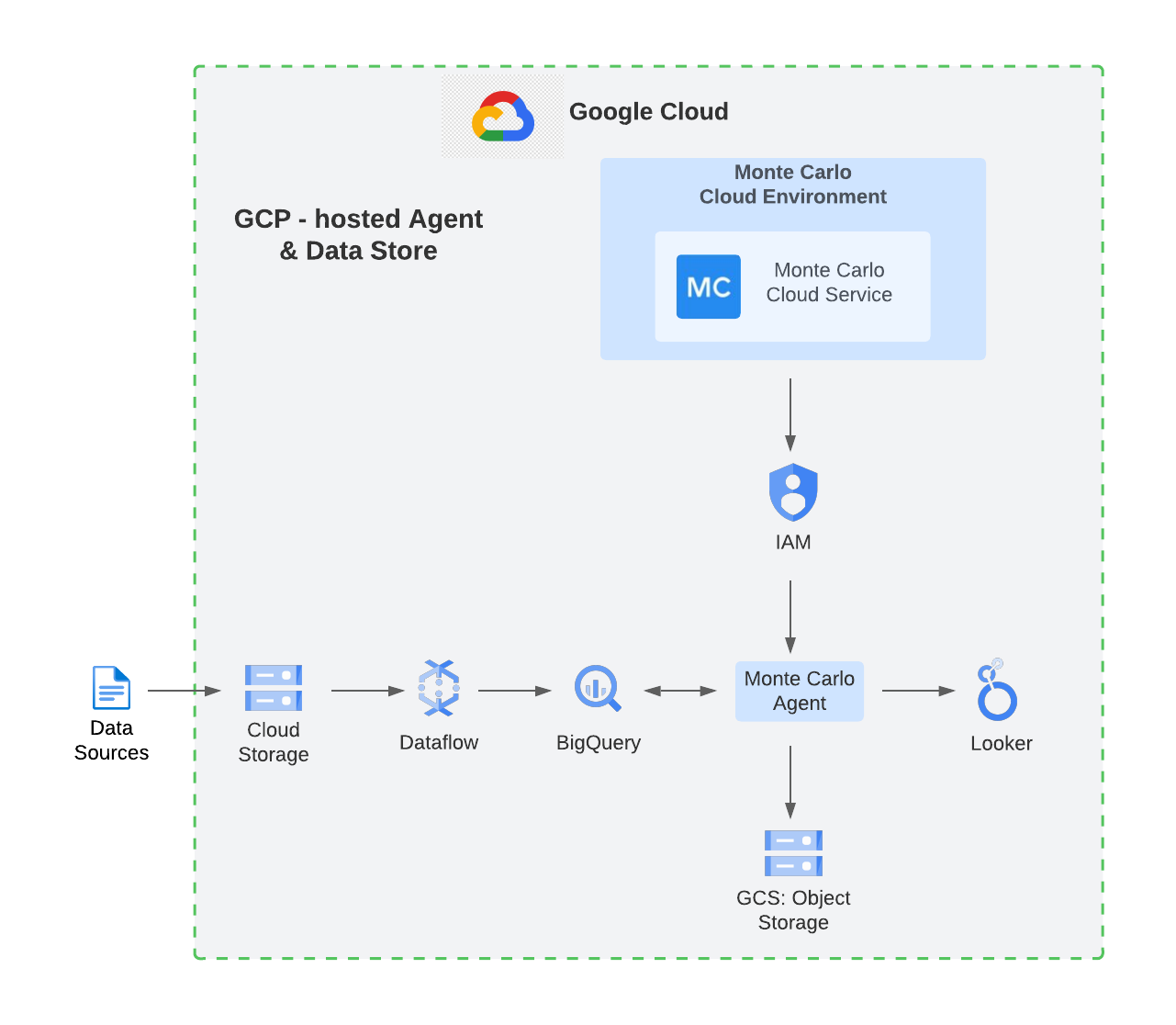
Additional architecture options include deployments where:
- the MC agent is hosted within the Monte Carlo cloud environment and object storage remains as a Google Cloud Storage bucket
- both the MC agent and object storage are hosted within the MC cloud environment
These deployment options help you choose how much control you want over your connection to the MC service as well as how you want to manage the agent/collector infrastructure.
The Google-Cloud-hosted agent and datastore option provides several capabilities, built on the following components:
- Process and enrich data in BigQuery - BigQuery is a serverless and cost-effective enterprise data platform. Its architecture lets you use SQL language to query and enrich enterprise-scale data. And its scalable, distributed analysis engine lets you query terabytes in seconds and petabytes in minutes. Integrated ML and support for BI Engine lets you easily analyze the data and gain business insights.
- Visualize data and insights in Looker - Looker is a comprehensive business intelligence tool that consolidates your data via integration with numerous data sources. Looker lets users craft and personalize dashboards automatically, turning data into significant business metrics and dimensions. Linking Looker with BigQuery is straightforward, as users can add BigQuery projects and specific datasets directly as Looker data sources.
- Deploy the Monte Carlo agent and object storage - Monte Carlo uses an agent to connect to data warehouses, data lakes, BI and other ETL tools in order to extract metadata, logs and statistics. No record-level data is collected by the agent. However, there are times when Monte Carlo customers may want to sample a small subset of individual records within the platform as part of their troubleshooting or root-cause analysis process. Perhaps you need this type of sampling data to persist within your clouds, which can be done via dedicated object storage in Google Cloud Storage. To deploy the agent in your Google Cloud environment, you can access the appropriate infrastructure wrapper on the Terraform Registry. This launches a DockerHub image to Cloud Run for the agent and a Cloud Storage bucket for sampling data. The agent has a stable HTTPS endpoint that accesses the public internet and authorizes via Cloud IAM.
- Deploy object storage for Monte Carlo sampling data - There are times when Monte Carlo customers may want to sample a small subset of individual records within the platform for troubleshooting or to perform root-cause analysis process. They may have a desire or requirement for this type of sampling data to persist within their clouds, whether or not they choose to deploy and manage the Monte Carlo agent. Users can find the appropriate infrastructure wrapper available on the Terraform Registry (GitHub repository) that will generate the resources
- Integrate Monte Carlo and BigQuery - Once the agent is deployed and you’ve established connectivity, you create a read-only service account with the appropriate permissions and provide the service credentials via the Monte Carlo onboarding wizard (details for BigQuery setup here). By parsing the metadata and query logs in BigQuery, Monte Carlo can automatically detect incidents and display end-to-end data lineage, all within days of deployment, without any additional configuration.
- Integrate Monte Carlo and Looker - You can also easily integrate Looker and Looker Git (formerly LookML code repository), which will allow Monte Carlo to map dependencies between Looker objects and other components of your modern data stack. This can be done by creating an API key on Looker that allows Monte Carlo to access metadata on your Dashboards, Looks, and other Looker Objects. You can then connect via private/public keys, which provides more granular control and connectivity, or HTTPS, which is recommended if you have many repos to connect to MC.
- Integrate Monte Carlo with Cloud Composer and Cloud Dataplex - The Monte Carlo agent can be effectively integrated with both Cloud Composer and Cloud Dataplex to enhance data reliability and observability across your Google Cloud data ecosystem. By integrating Monte Carlo with Cloud Composer and Cloud Dataplex, you can ensure enhanced data observability, quicker identification of data incidents, and more efficient root-cause analysis. This integration empowers teams to maintain high data quality and reliability across complex, multi-faceted data environments within Google Cloud.
- Integrate Monte Carlo and other ETL tools - Organizations’ data platforms often consist of multiple solutions to manage the data lifecycle — from ingestion, orchestration, and transformation, to discovery/access, visualization, and more. Depending on their size, some organizations may even use multiple solutions within the same category. For example, in addition to BigQuery, some organizations store and process data within other ETL tools powered by Google Cloud. Most of these integrations require a simple API key or service account to connect them to your Google-Cloud-hosted Monte Carlo agent. For more details on a specific integration, refer to Monte Carlo’s documentation.
Conclusion
In conclusion, deploying data observability with Monte Carlo and Google Cloud offers an invaluable solution to the increasingly critical issue of data downtime. By leveraging advanced Google Cloud services and Monte Carlo's observability capabilities, organizations can not only mitigate risks associated with bad data but also enhance trust, collaboration, and efficiency across their data landscape. As we've explored, the integration of tools like BigQuery and Looker with Monte Carlo's architecture creates a powerful synergy, optimizing data quality and performance while reducing the time and resources spent on data maintenance.
If you're looking to elevate your organization's data management strategies and minimize data downtime, consider exploring the integration of Monte Carlo with your Google Cloud environment. Start by evaluating your current data setup and identifying areas where Monte Carlo's observability can bring immediate improvements. Remember, in the world of data, proactive management is key to unlocking its full potential.
Ready to take the next step? Reach out to the Monte Carlo or Google Cloud team today to begin your journey towards enhanced data observability and reliability. Let's transform the way your organization handles data!



