Built with BigQuery: How Sift delivers fraud detection workflow backtesting at scale
Neeraj Gupta
CTO, Sift
Dr. Ali Arsanjani
Director, AI/ML Partner Engineering, Head of AI Center of Excellence, Google Cloud
Sift is one of the leaders in digital trust and safety, that empower digital disruptors of Fortune 500 companies to unlock new revenue without risk using machine learning to provide fraud detection services. Sift dynamically prevents fraud for many abuse categories through industry-leading ML-based technology, expertise, and an impressive global data network of over 70 billion monthly events.
Sift’s platform offers customers to configure workflows using an intuitive UI to automate fraud detection, accommodating highly critical business actions like blocking a suspicious order, applying additional friction (such as requesting MFA) to a transaction, or processing a successful transaction. Customers can build and manage their business logic using workflows within the Sift UI, automate decision-making and continue to streamline manual review. Sift’s customers process tens of millions of events in a single day through these workflows.
Below is an example of the Sift UI and how workflows enable customers to make risk-based decisions on user events, such as the creation of new incoming orders. In the example below, the workflow logic evaluates the payment abuse score of the incoming request and then redirects based on the level of severity. For example, as shown in route 3 (at the bottom of the image) if such a score is greater than 50 an email based 2 factor authentication is triggered to validate the incoming request if it's greater than 90 it will be labeled as a fraudulent request and blocked.
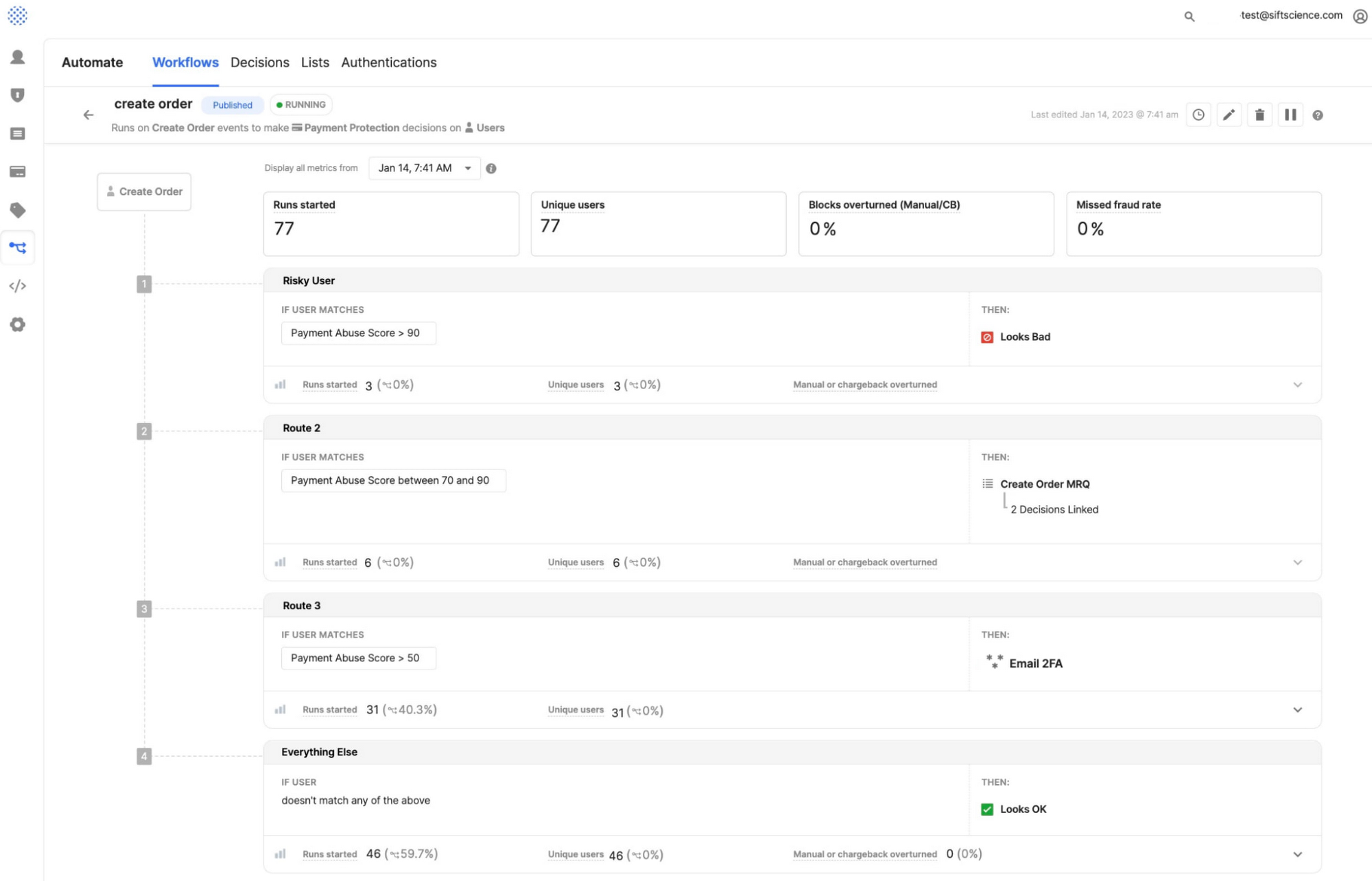
When changes are being made to existing workflows, customers want to be confident that these changes will positively affect their core KPIs (user insult rate, fraud cost, monthly active users, customer lifetime value, etc.). Productionizing a workflow route that has a negative effect can reduce the ROI and potentially deny valid requests or non-fraudulent customers, which must be avoided at all costs.
Workflow backtesting powered by BigQuery
The workflow backtesting architecture powered by BigQuery provides that functionality in a robust and scalable manner by enabling customers to:
Test changes for a route (as shown in the image above) within a running workflow
Self-serve and run “what-if” experiments with no code through the Sift UI
Enable fraud analysts to gauge a workflow’s performance for a route before publishing it in production
Here’s a high-level flow diagram of the fully managed and serverless Google Cloud building blocks utilized when issuing a Workflow Request:
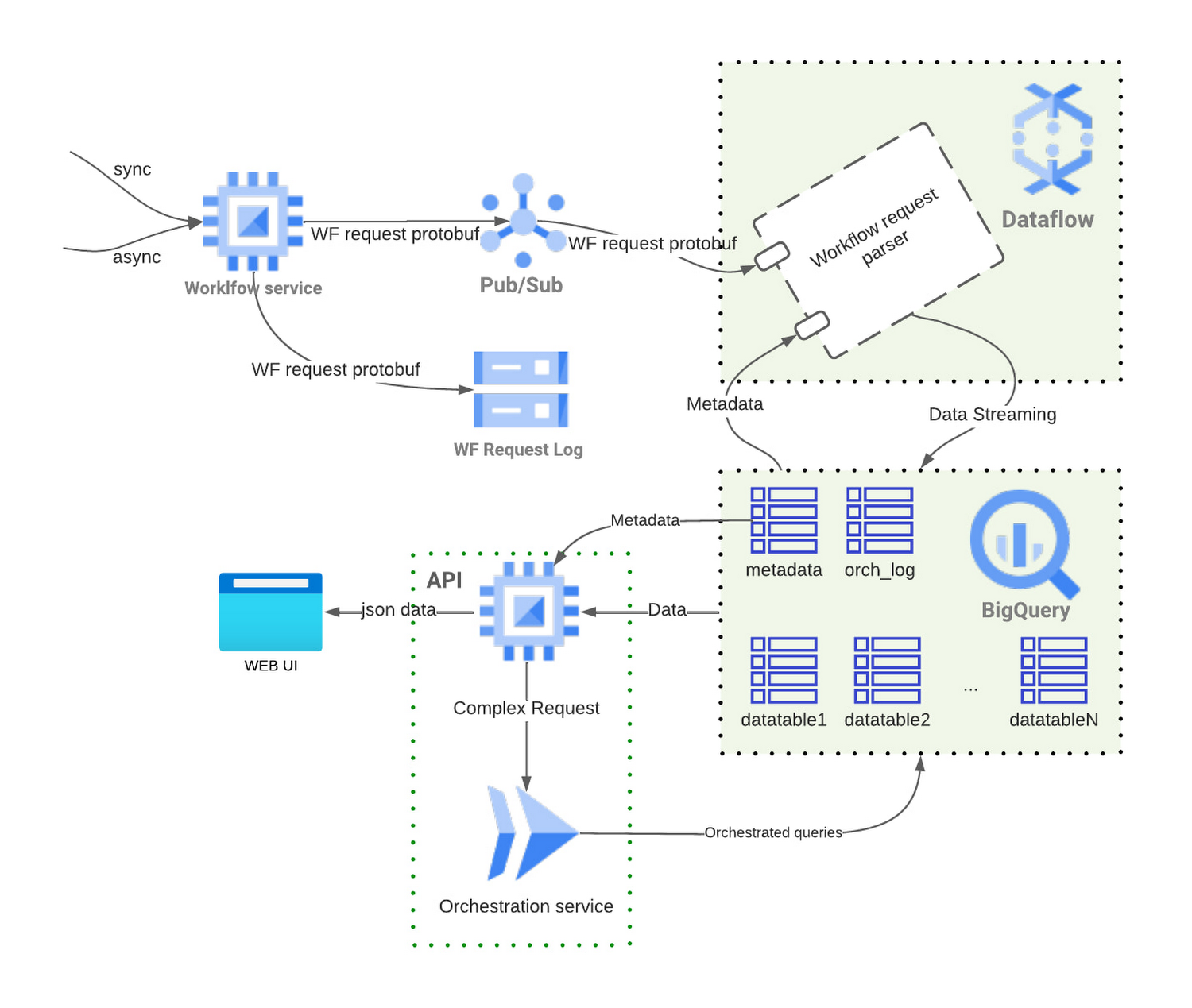
Whenever the workflow service receives a request, it pushes the message containing the whole workflow request into a Cloud Pub/Sub topic. A Dataflow job gets the message and processes it through a parser (workflow request parser) that extracts all available fields from the message. This process enables Sift to transform a complex workflow request into a flattened, spreadsheet-like structure that is very convenient for later use. After that, a Dataflow job creates records in BigQuery (via Storage Write API) following a schema-agnostic design.
Orchestration of the backtesting flow
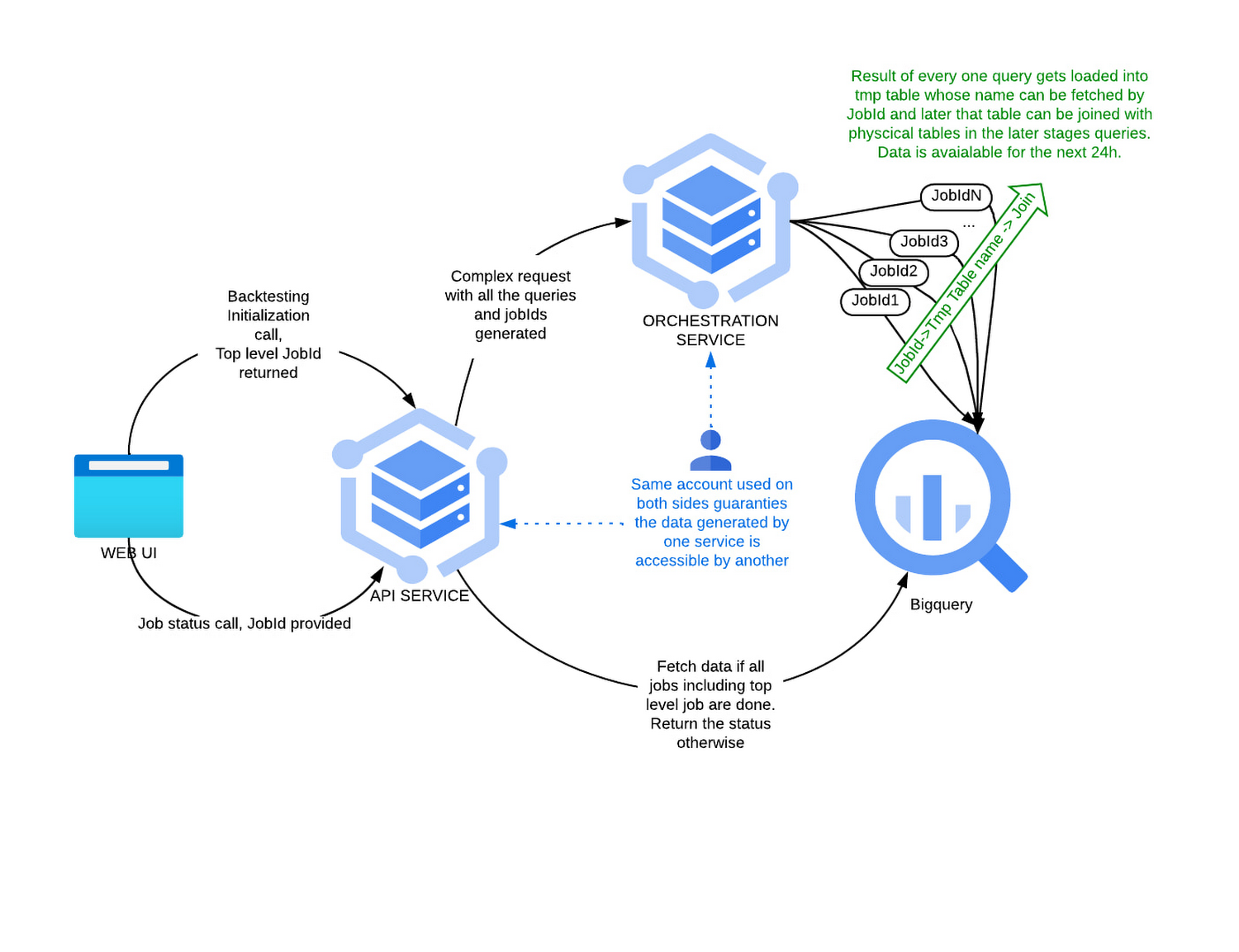
Conceptually, backtesting is implemented as a dynamically generated SQL query(s). In order to process a single backtesting call, Sift needs to run three or more queries that depend on each other and should be processed in a strictly defined order as a logical unit of work. The Sift console is utilized to perform backtesting async API calls. The orchestration service is a simple web application based on Spring Cloud that exposes an endpoint that accepts JSON-formatted requests. Every request includes all backtesting queries packed along with all related query parameters and pre-generated JobIDs. It parses the request and executes all queries against BigQuery in the correct order. For every single step, it creates a status record into a log table that API queries for context on the status of the readiness of the data. The process can be depicted in the next diagram:
BigQuery’s ability to scale and the path to a schema agnostic design
Every workflow request may contain tens of thousands of columns/fields that customers may decide to use for any backtesting request. The table sizes are in terabytes and have billions of records each. Furthermore, often attributes are being added or removed prior to testing a new workflow, hence the need for a schema-agnostic design allowing for:
The introduction of new features without needing to modify the table's structure
Changes to be implemented declaratively through modification of metadata vs. schemas
Deep customization and scalability allowing for more than ten thousand features of the same data type for customers that use many custom fields

As illustrated in the schema above, data are grouped into tables arranged by data type rather than a workflow-specific layout. Joining that data is accomplished by utilizing an associative metadata table, which can be thought of as (fact table) linking to multiple data type tables (dimension tables) in the context of a traditional data warehousing design.
Data volumes are large, and schemas frequently change, making indexing labor-intensive and less applicable. During the evaluation of the initial workflow architecture, Sift performed comprehensive testing on deeply nested queries with large aggregations to identify the most suitable schema design allowing for performance and flexibility. Columnar storage formats for the data fit well into this idea as it minimizes IO necessary for loading data into memory and further manipulation via complex dynamically queries. Before finalizing the design, Sift performed extensive benchmarking, running logically similar queries against comparable volumes of data managed by several data warehouse solutions and benchmarking the BQ-powered solution. The conclusion was that BQs Dremel Engine and the cluster-level file system (Colossus) provided their use case's most performant and scalable architecture.
Benchmarking with BigQuery
During several sessions of load testing and working through a set of "production-like" use cases with production volumes of data and throughput, the team reached satisfactory average response times of around 60 seconds for the single backtesting request and a max response time approaching 2 minutes for complex requests. Load testing also helped to estimate the necessary number of BQ Slots required to supply expected workload(s) with enough computation resources. Below is an example of the initial Jmeter test report (Configuration: Randomly chosen clientId/workflow configId/routeId):
Backtesting period: 45d
BQ Computation resources: 3000 BQ slots
Planned workload to reach: 30 requests per minute
Test duration: 30 mins

Additionally, the team started to experiment with the "BigQuery Slot Estimator" functionality, allowing for:
Visualization of slot capacity and utilization data for the workflow-specific project
Identification of periods of peak utilization when the most slots are used
Exploration of job latency percentiles (P90, P95) to understand query performance related to Workflow Backtesting Sequences
What-if modeling of how increasing or reducing slots might affect performance over time.
Assessing the automatically-generated cost recommendations based on historical usage patterns
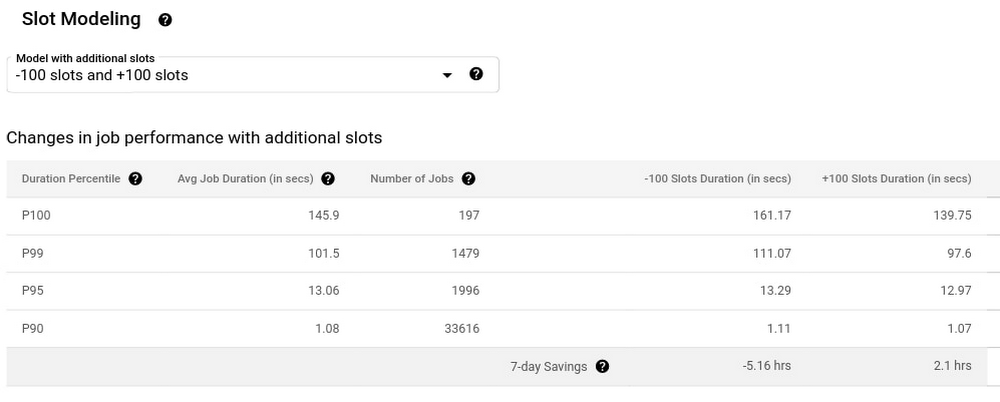
Below is an example of utilizing BQ's Slot Estimator to model how performance might change at different capacity levels, modeled at -100 and +100 slots of the current capacity:
Customer success stories
From crypto and fintech companies to on-demand apps and marketplaces, customers of Sift see less fraud and more growth. Below is a small subset of examples on how Sift helps their customers reduce payment friction and focus on user growth.
Conclusion
Google’s data cloud provides a complete platform for building data-driven applications like the workflow backtesting solution developed by Sift. Simplified data ingestion, processing, and storage to powerful analytics, AI, ML, and data sharing capabilities are integrated with the open, secure, and sustainable Google Cloud platform. With a diverse partner ecosystem, open-source tools, and APIs, Google Cloud can provide technology companies with the portability and differentiators they need to serve the next generation of customers.
- Learn more about Sift on Google Cloud.
- Learn more about Google Cloud’s Built with BigQuery initiative.
We thank the Sift and Google Cloud team members who co-authored the blog: Pramod Jain Senior Staff Software Engineer, Sift, Eduard Chumak Staff Software Engineer, Sift, Christian Williams, Principal Architect, Cloud Partner Engineering, Raj Goodrich - Cloud Customer Engineer at Google Cloud

