Unlocking the hidden value of data: Launching Dataflow Templates for Elastic Cloud
Evren Eryurek
Director of Product Management, Google Cloud
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialA key strategic priority for many customers that we work with is to unlock the value of the data they already have. Up to 73% of all data within an enterprise goes unused for analytics. “Dark data” is a commonly used term to refer to this and industry observers believe that most enterprises are only leveraging a small percentage of their data for analytics.
While there are many dimensions to unlocking data for analytics, one fundamental component is the need to make data available across systems so that users are not limited by organization and technological silos. To that end, we launched Dataflow Templates to address the challenge of making data seamlessly available across various systems that a typical enterprise needs to deal with. Dataflow Templates, built on the rich, scalable and fault tolerant data processing capabilities of Dataflow and Apache Beam, provides a turnkey, utility-like experience for common data ingestion and replication tasks. Dataflow Templates are prepackaged data ingestion and replication pipelines for many of the common needs that users have to make data available to all their users and systems so that they can make the most of the data.
We provide a number of Dataflow Templates including some of the most popular ones such as Pub/Sub to BigQuery, Apache Kafka to BigQuery, Cloud Spanner to Cloud Storage and Data Masking/Tokenization (using Cloud DLP). We continue to make more Templates available and recently launched Templates for Datastream to create up-to-date replicated tables of your data in Database into BigQuery for analytics.
Today, we announce a new set of Templates we developed in partnership with Elastic. These Templates allow data engineers, developers, site reliability engineers (SREs) and security analysts to ingest data from BigQuery, Pub/Sub and Cloud Storage to the Elastic Stack with just a few clicks in the Google Cloud Console. Once created, Dataflow Templates run in a serverless fashion: there is no infrastructure to size and setup, no servers to manage and more importantly, no distributed system expertise is required to setup and operate these Templates. Once the data is in Elastic, users can easily search and visualize their data with Elasticsearch and Kibana to complement the analytics they are able to perform on Google Cloud.
“It’s never been easier for our customers to explore and analyze their data with Elastic in Google Cloud. By leveraging Google Dataflow templates, customers can ingest data from Google Cloud services, such as BigQuery, Cloud Storage and Pub/Sub without having to install and manage agents,” said Uri Cohen, Product Lead,Elastic Cloud.
Getting started with these Templates is very easy, first head to Dataflow in the Google Cloud Console, select Create Job From Template and then select one of the Elastic Templates from the dropdown.
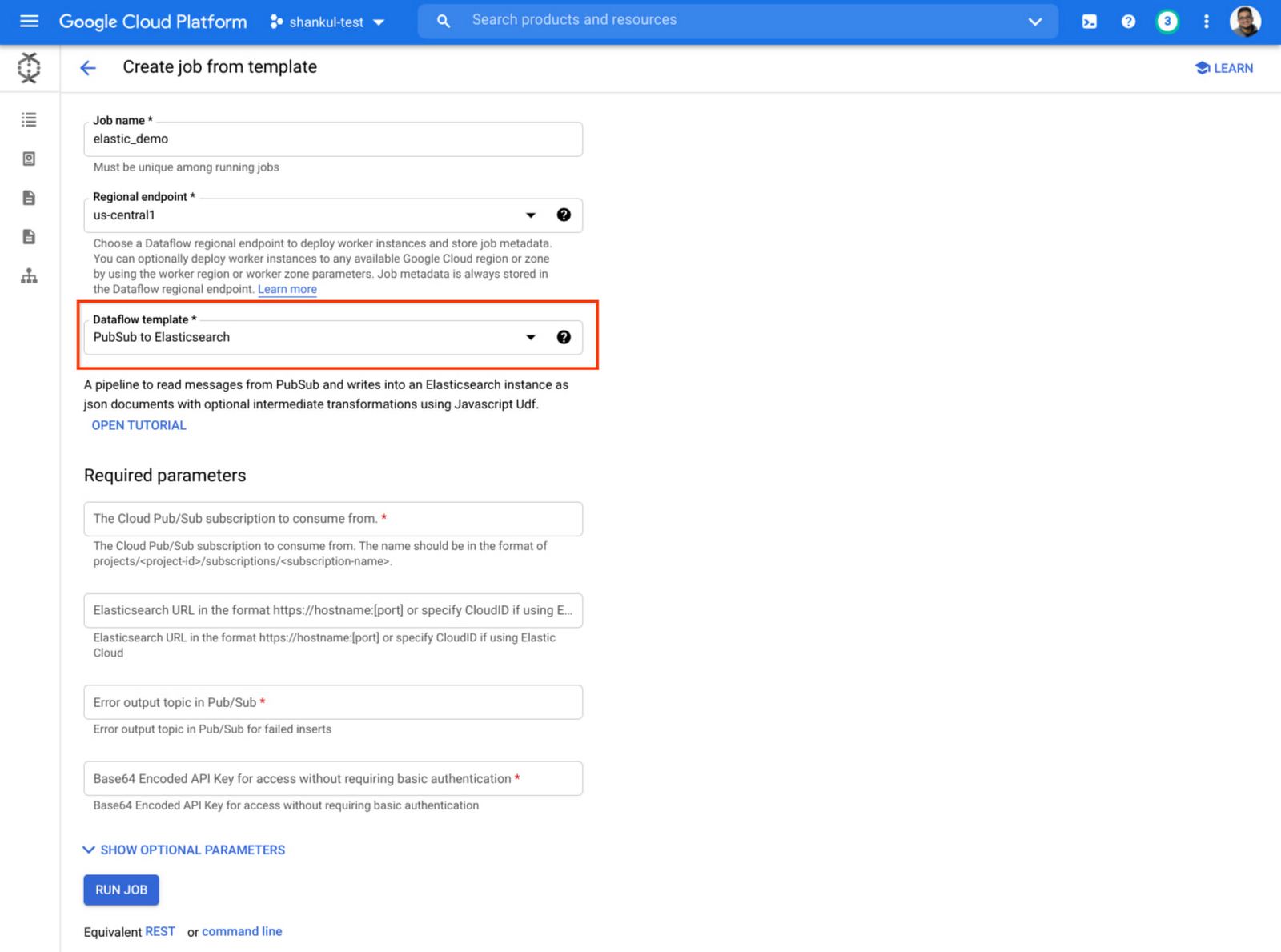
The team at Elastic has also published a series of blog posts with detailed information on using these Templates.
Ingest data directly from Google Pub/Sub into Elastic using Google Dataflow
Ingest data directly from Google BigQuery into Elastic using Google Dataflow
Ingest data directly from Google Cloud Storage into Elastic using Google Dataflow
Additionally, you can find more information, including other Templates available at Getting started with Dataflow Templates.


