Advanced text analyzers and preprocessing functions in BigQuery
HP Truong
Software Engineer, BigQuery Search
BigQuery stores massive amounts of unstructured and structured text data, including customer information and business operations. BigQuery's Search and Machine Learning (ML) capabilities provide powerful analytical tools for extracting valuable business insights from these text data sets.
Text preprocessing is a critical step in text analysis and information retrieval pipelines, as it transforms raw natural language or unstructured text into machine-friendly formats. It is a prerequisite for many text-based operations, such as full-text search indexing and machine learning pipelines. In many cases, the effectiveness of a text search index is greatly influenced by the quality of the tokenization algorithm chosen. Similarly, the performance of machine learning models relies heavily on the quality of the preprocessed inputs.
We are announcing the public preview of a set of text analysis and preprocessing functions and capabilities in BigQuery. These new features will be an essential part of text processing on top of primitive string functions to further enhance the Search and ML experience in BigQuery.
Empowering text searches with analyzers
Fraud investigation scenario
Consider a hypothetical fraud investigation and prevention scenario. During the investigation, it would be beneficial to search business logs data to identify suspicious activities associated with the reported transactions. The process involves retrieving entries containing relevant customer information from a logs table that is generated by day-to-day business activities.
The following information may be of interest:
- customer ID
- access IP address
- email address
- last 4 digits of credit card number.
With the newly added powerful PATTERN_ANALYZER and its configurability, we will create a search index to help us search for the above specific information.
Constructing a search index configuration
A search index with the PATTERN_ANALYZER allows us to extract and index information that matches a specified RE2 regular expression. In this case, our regular expression will have the following form (note that "?:" denotes non-capturing group since we will capture the entire pattern as a whole):
(?:<customer_uuid>)|(?:<ip_address>)|(?:<email_address>)|(?:<credit_card_4_digits_number>)
Here's an example of a possible regular expression for each of the above component:
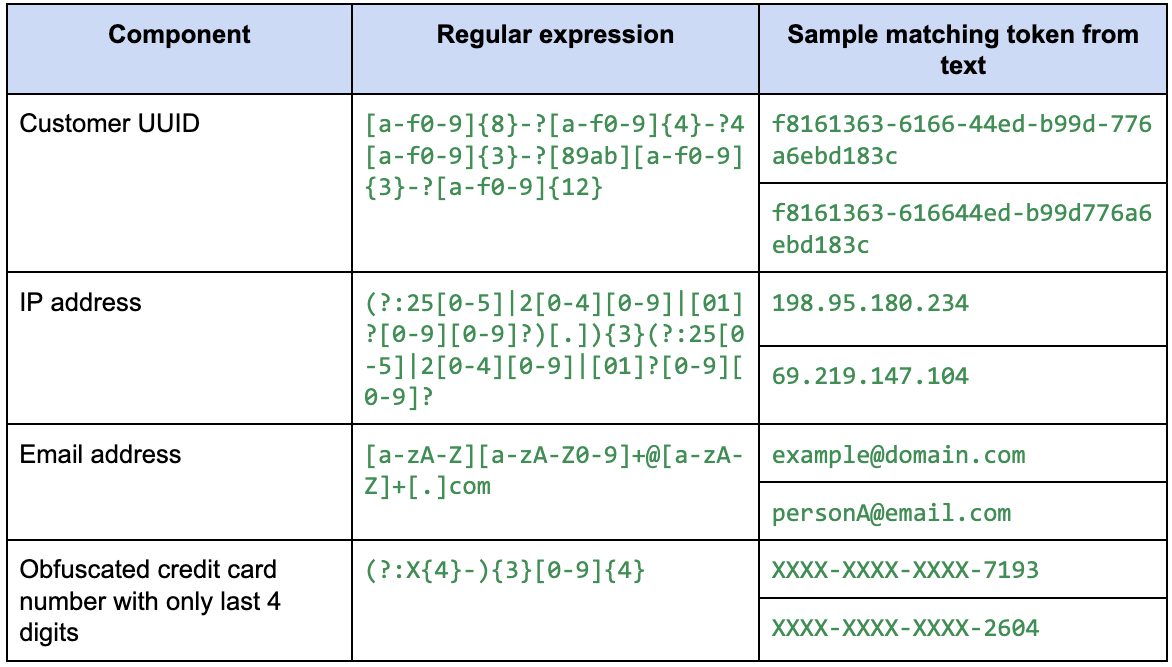
Putting them all together, we have the following regular expression:
(?:[a-f0-9]{8}-?[a-f0-9]{4}-?4[a-f0-9]{3}-?[89ab][a-f0-9]{3}-?[a-f0-9]{12})|(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)[.]){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)|(?:[a-zA-Z][a-zA-Z0-9]+@[a-zA-Z]+[.]com)|(?:(?:X{4}-){3}[0-9]{4})
We then can make further steps on the captured tokens to improve the search index effectiveness and search usability:
- lowercase the text to enable case-insensitive searches
- remove some known email addresses such as trusted system robot emails or testing emails
- remove some fixed/known IP addresses like localhost.
To do this, we can use the token filters option of the analyzer:

Experimenting with different configurations
Prior to creating our search index, which can be a time-consuming and expensive process, we use the newly added TEXT_ANALYZE function to experiment with various configurations to find the one that works as intended. Below we show some example queries to test the configurations.
Since we will use the same analyzer options in our example, we can declare a variable called CUSTOM_OPTIONS so that we can reuse it in multiple queries:
Note: in this example, we have two separate lists of stop words for illustration purposes. In practice, combining the list to be 1 list would make the search execution faster.
Example 1: text containing both UUID and IP address
Result:

Example 2: text containing multiple email addresses and an obfuscated credit card number
Result:

We can continue iterating until we identify a good configuration for our use cases. Let's say that in addition to the critical information for our investigation, we also want to add regular words to our index. This way, the searches for normal words can also make use of the search index. We can do this by appending the following regular expression to the end of our pattern:
\b\w+\b
So our regular pattern becomes
(?:[a-f0-9]{8}-?[a-f0-9]{4}-?4[a-f0-9]{3}-?[89ab][a-f0-9]{3}-?[a-f0-9]{12})|(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)[.]){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)|(?:[a-zA-Z][a-zA-Z0-9]+@[a-zA-Z]+[.]com)|(?:(?:X{4}-){3}[0-9]{4})|(?:\b\w+\b)
Since we are indexing normal words now, it is also useful to remove some common English words so they don't pollute the index with unnecessary entries. We do this by specifying the stop_words list in the analyzer options:
{"stop_words": ["a", "an", "and", "are", "is", "the"]}
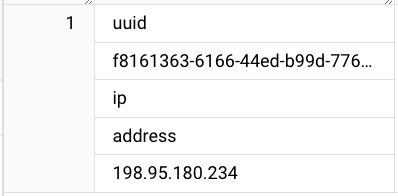
The latest configuration and verification using TEXT_ANALYZE function can be seen below (note that we need to escape the backslashes \ in our SQL statements):
Result:
Result:
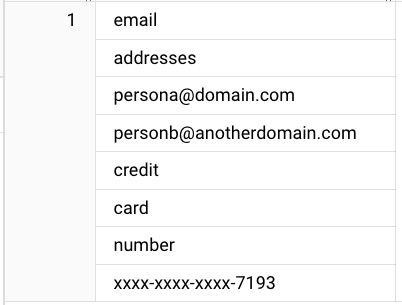
Creating the search index
Once we conclude our testing effort and find the suitable configuration, we can create the search index:
Using the search index
As a reminder of how the SEARCH function works, it applies the analyzer (with the specified configuration) on both the search data as well as the input search query, and returns TRUE if the tokens from the search query is a subset of the tokens from the searched data.
While the SEARCH function works without indexes, it can take advantage of the search index for better performance if the function and the index share the same analyzer configurations. We set the analyzer and analyzer_options arguments in the SEARCH function below:
IP addresses, customer UUIDs, other normal words (not the stop words) are also indexed, so searching for those can be improved by the search index in a similar manner.
In this example, we can see that the new PATTERN_ANALYZER is a powerful tool to help build an effective search index for our fraud investigation scenario. The text analyzers and their options are designed to be flexible to accommodate various use cases. With correct configurations for search indexes, query performance can be greatly improved as presented in this blog post.
Text analyzers with BigQuery ML
We also announce two new text preprocessing functions: ML.TF_IDF and ML.BAG_OF_WORDS. Similar to other preprocessing functions, these two new functions can be used in the TRANSFORM clause to create ML models with data preprocessing. The following example shows how to use these functions with text analyzers.
The ML use cases for text analyzers focus more on extracting all text tokens and performing Unicode normalization on them before vectorization. This is achieved via combining the above functions with the newly introduced TEXT_ANALYZE function.
While BigQuery offers the ability to use pre-trained ML models for text vectorization, the aforementioned statistics-based functions offer simplicity, interpretability, and lower computational requirements. Additionally, when dealing with new domains where extensive domain-specific data for fine-tuning is lacking, statistics-based methods often outperform pre-trained model-based methods.
In this example, we will explore building a machine learning model to classify news into 5 categories: tech, business, politics, sport, and entertainment. We will use the BBC news public dataset, which is hosted in BigQuery at bigquery-public-data.bbc_news, and carry out the following steps:
- Tokenize news as raw strings and remove English stop words.
- Train a classification model using the tokenized data and a custom vectorization function in BigQuery ML.
- Make predictions on new test data to classify news into categories.
Raw text preprocessing with TEXT_ANALYZE
The first step in building the classifier is to tokenize the raw news text and preprocess the tokens. The default LOG_ANALYZER with its default list of delimiters is often good enough, so we can use them without any further configuration.
Additionally, our text data may contain Unicode text, so ICU normalization would be a useful preprocessing step.
{ "normalizer": { "mode": "ICU_NORMALIZE" } }
Next, we filter out some common English stop words from the tokens list:
{"stop_words": ["is", "are", "the", "and", "of", "be", "to"]}
Putting it all together, we use TEXT_ANALYZE to preprocess the raw data and materialize into a table as inputs for our training model
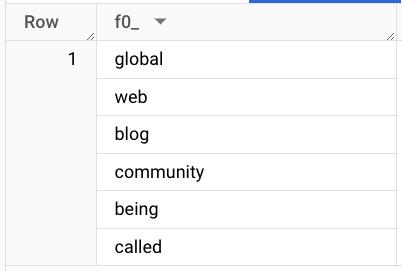
We can take a look at an example tokenized row to get an idea of the tokenization result:
Result:
Model training with TRANSFORM clause
Now we can use the tokenized data to train our classifier. In this example we use the random forest classifier together with the TRANSFORM clause using ML.BAG_OF_WORDS as the vectorization function:
After training, we can see that the created model has good performance.

Using the model for inference
Finally, we can test out the model using an excerpt from a sport article outside of the training data. Note that we will need to use the exact same TEXT_ANALYZE options for preprocessing.
Result:
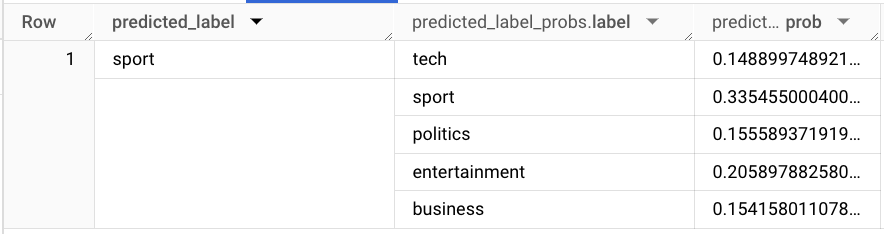
This example illustrates that TEXT_ANALYZE and BigQuery ML vectorization functions are great tools for preprocessing data and creating machine learning models. This is a significant improvement compared to the multiple steps presented in our previous blogpost on sentiment analysis with BigQuery ML.
Conclusion
The new features added to our text analysis toolset are valuable additions to the existing functionality. They provide users with more flexibility, power, and insight into their data. The ability to perform custom text analysis in a variety of ways makes our toolset even more comprehensive and user-friendly.
We invite you to try out the new features and see for yourself how they can enhance your text preprocessing and analysis workflow. We hope that these new features will help you to gain even deeper insights into your data. We are committed to continuing to develop and improve our text analysis tools to meet your needs.

