Boost developer productivity with new pipeline validation capabilities in Dataflow
Ning Kang
Software Engineer, Google
Efesa Origbo
Product Manager, Google
Among data engineers, Dataflow is widely used to develop batch and streaming jobs that support a wide variety of analytics and machine learning use cases, for example patient monitoring, fraud prevention, and real-time inventory management. Data engineers love Dataflow’s ease of use, observability features, and massive scale. They also need to continue reducing the time they spend troubleshooting and fixing issues within their data pipelines. This need becomes even more important in the context of rapidly growing data volumes, and the rise of generative AI.
Data engineers building batch and streaming jobs with Dataflow sometimes face a few challenges. Examples of such challenges include:
-
User errors in their Apache Beam code sometimes go undetected until the job fails while it is already running, wasting engineering time and cloud resources.
-
Fixing the initial set of errors that are highlighted after a job failure is no guarantee of future success. Subsequent submissions of the same job may fail and highlight new errors that require fixing before the job can run successfully.
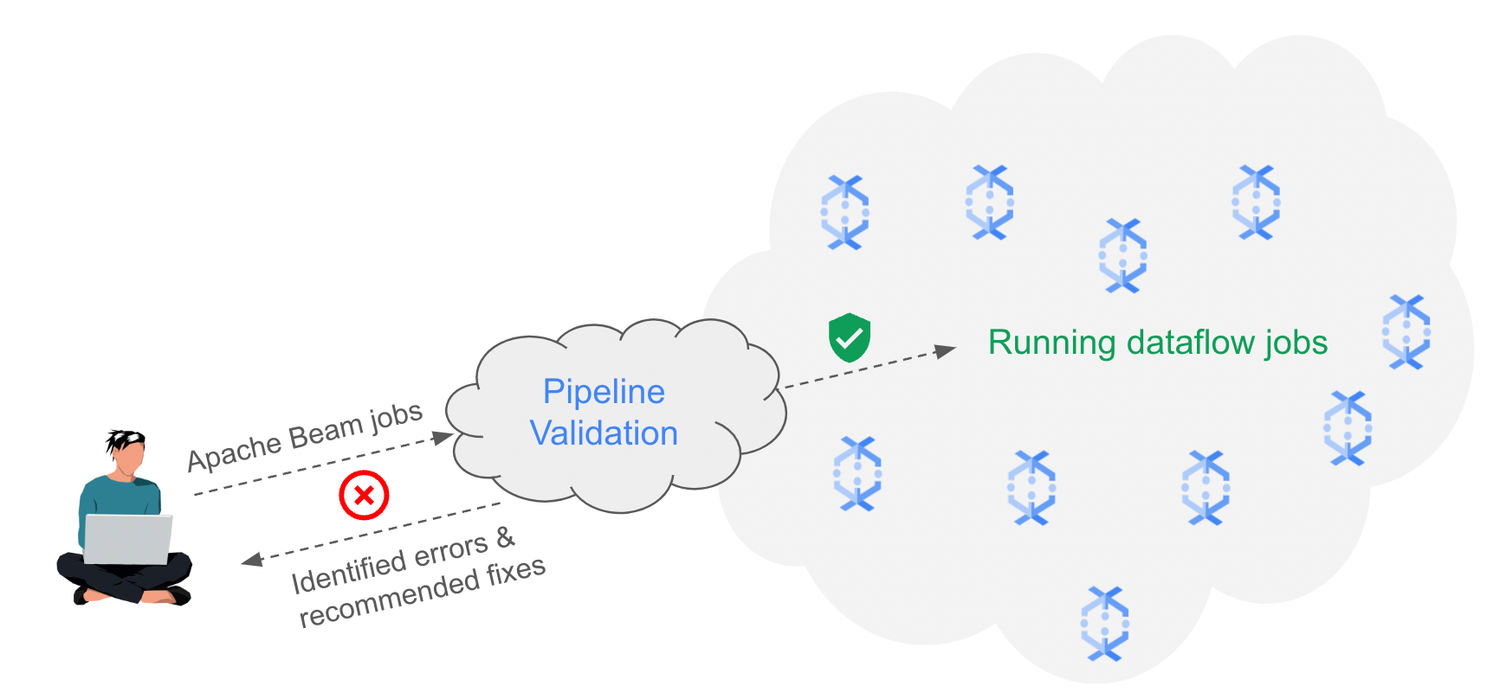
To solve these challenges, we’re excited to announce the general availability of pipeline validation capabilities in Dataflow.
Now, when you submit your batch or streaming job, Dataflow pipeline validation performs dozens of checks to ensure that your job is error free and can run successfully. Once the validations are completed, you are presented with a list of identified errors, along with recommended fixes in a single pane of glass, saving you time you would have previously spent on iteratively fixing errors in your Apache Beam code.
Early results
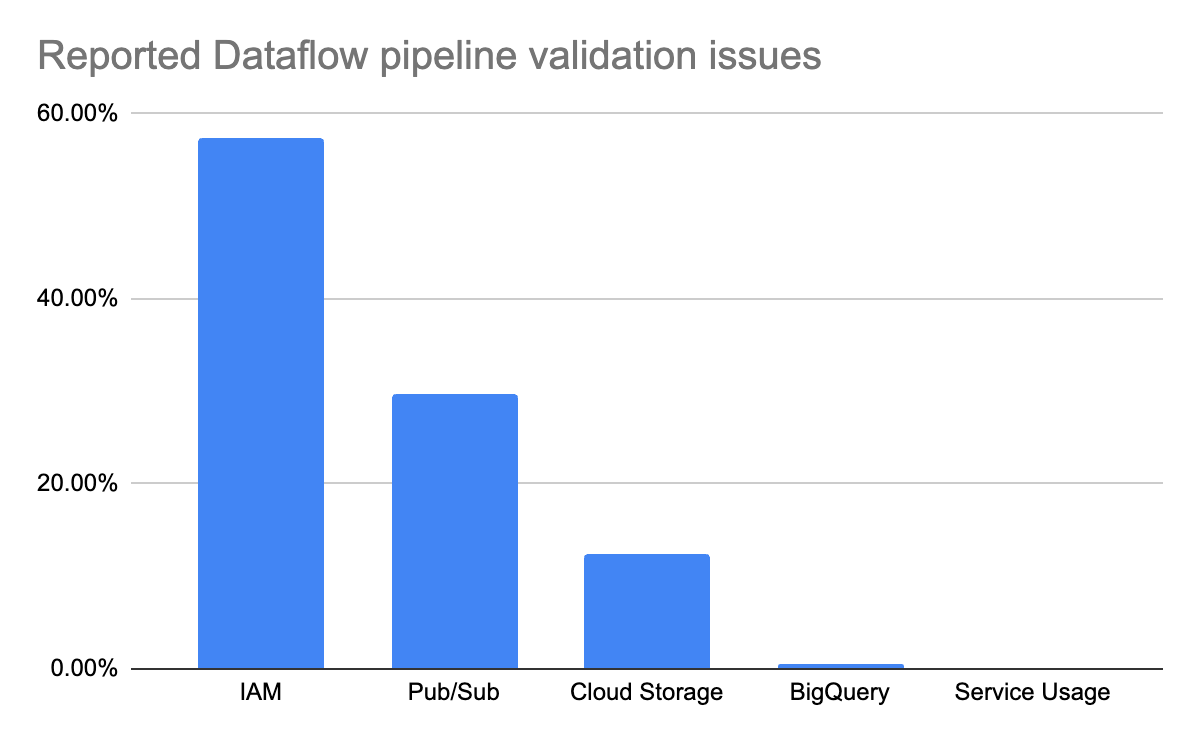
Since we launched the feature, we’ve seen that pipeline validation can catch issues in a wide range of jobs, saving time that would otherwise be spent on troubleshooting. The majority of these issues are due to missing identity and access management (IAM) permissions that are required to run Dataflow jobs. The second most common set of issues are missing Pub/Sub topics and subscriptions, including typos and accidentally deleted topics and subscriptions.
Getting started
Pipeline validation is enabled by default for all Dataflow batch and streaming jobs. You can disable this feature by setting the enable_preflight_validation service option to false. Also, when you update an existing streaming pipeline, you can use the graph_validate_only service option to trigger a validation check for your new job graph. To learn more about pipeline validation, head on over to the documentation for more details.



