BigQuery integrates with Document AI to help build document analytics and generative AI use cases
Oliver Zhuang
Software Engineer
As digital transformation accelerates, organizations are generating vast amounts of text and other document data, all of which holds immense potential for insights and powering novel generative AI use cases. To help harness this data, we’re excited to announce an integration between BigQuery and Document AI, letting you easily extract insights from document data and build new large language model (LLM) applications.
BigQuery customers can now create Document AI Custom Extractors, powered by Google's cutting-edge foundation models, which they can customize based on their own documents and metadata. These customized models can then be invoked from BigQuery to extract structured data from documents in a secure, governed manner, using the simplicity and power of SQL.
Prior to this integration, some customers tried to construct independent Document AI pipelines, which involved manually curating extraction logic and schema. The lack of native integration capabilities left them to develop bespoke infrastructure to synchronize and maintain data consistency. This turned each document analytics project into a substantial undertaking that required significant investment. Now, with this integration, customers can easily create remote models in BigQuery for their custom extractors in Document AI, and use them to perform document analytics and generative AI at scale, unlocking a new era of data-driven insights and innovation.
A unified, governed data to AI experience
You can build a custom extractor in the Document AI Workbench with three steps:
- Define the data you need to extract from your documents. This is called document schema, stored with each version of the custom extractor, accessible from BigQuery.
- Optionally, provide extra documents with annotations as samples of the extraction.
- Train the model for the custom extractor, based on the foundation models provided in Document AI.
In addition to custom extractors that require manual training, Document AI also provides ready-to-use extractors for expenses, receipts, invoices, tax forms, government ids, and a multitude of other scenarios, in the processor gallery. You may use them directly without performing the above steps.
Then, once you have the custom extractor ready, you can move to BigQuery Studio to analyze the documents using SQL in the following four steps:
- Register a BigQuery remote model for the extractor using SQL. The model can understand the document schema (created above), invoke the custom extractor, and parse the results.
- Create object tables using SQL for the documents stored in Cloud Storage. You can govern the unstructured data in the tables by setting row-level access policies, which limits users’ access to certain documents and thus restricts the AI power for privacy and security.
- Use the function ML.PROCESS_DOCUMENT on the object table to extract relevant fields by making inference calls to the API endpoint. You can also filter out the documents for the extractions with a “WHERE” clause outside of the function. The function returns a structured table, with each column being an extracted field.
- Join the extracted data with other BigQuery tables to combine structured and unstructured data, producing business values.
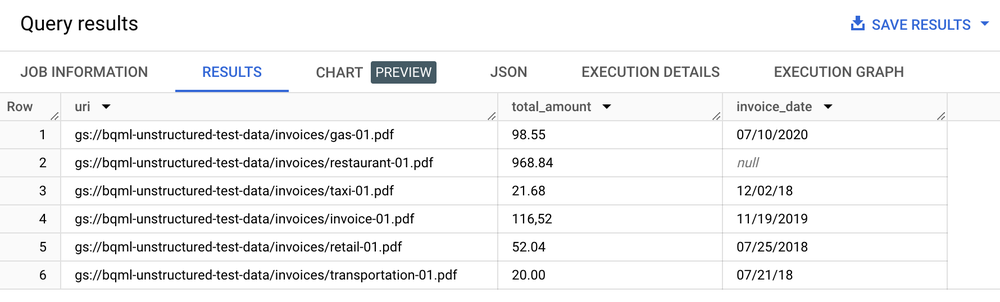
The following example illustrates the user experience:
Table of results
Text analytics, summarization and other document analysis use cases
Once you have extracted text from your documents, you can then perform document analytics in a few ways:
- Use BigQuery ML to perform text-analytics: BigQuery ML supports training and deploying text models in a variety of ways. For example, you can use BigQuery ML to identify customer sentiment in support calls, or to classify product feedback into different categories. If you are a Python user, you can also use BigQuery DataFrames for pandas, and scikit-learn-like APIs for text analysis on your data.
- Use PaLM 2 LLM to summurize the documents: BigQuery has a ML.GENERATE_TEXT function that calls the PaLM 2 model to generate texts, which can be used to summarize the documents. For instance, you can use a Document AI to extract customer feedback and summarize the feedback using PaLM 2, all with BigQuery SQL.
- Join document metadata with other structured data stored in BigQuery tables: This allows you to combine structured and unstructured data for more powerful use cases. For example, you could identify high customer lifetime value (CLTV) customers with feedback captured from online reviews, or shortlist the most requested product features from customer feedback.
Implement search and generative AI use cases
Once you’ve extracted structured text from your documents, you can build indexes optimized for needle-in-the-haystack queries, made possible by BigQuery's search and indexing capabilities, unlocking powerful search functionality.
This integration also helps unlock new generative LLM applications like executing text-file processing for privacy filtering, content safety checks, and token chunking using SQL and custom Document AI models. The extracted text, combined with other metadata, simplifies the curation of the training corpus required to fine-tune large language models. Moreover, you’re building LLM use cases on governed, enterprise data that’s been grounded through BigQuery's embedding generation and vector index management capabilities. By synchronizing this index with Vertex AI, you can implement retrieval-augmented generation use cases, for a more governed and streamlined AI experience.
Next steps
The above capabilities are now available in preview. To get started, reach out to your Google sales representative, or check out the following tutorials:

