Meet Your New AI-Powered Teammate: Introducing the BigQuery Data Engineering Agent
Firat Tekiner
Product Management
Honza Fedak
Director of Engineering
For years, data teams have relied on the BigQuery platform to power their analytics and unlock critical business insights. But building, managing, and troubleshooting the data pipelines that feed those insights can be a complex, time-consuming process, requiring specialized expertise and a lot of manual effort. Today, we're excited to announce a major step forward in simplifying and accelerating data engineering within BigQuery: the Data Engineering Agent, now available for you to try in an experimental release.
This is not just an assistive tool; it is an agentic solution, designed to act as intelligent partners in your data workflows. They automate daunting tasks, collaborate with your team, and continuously learn and adapt, freeing you to focus on what matters most: extracting value from your data.
Why a data engineering agent?
The world of data is changing. Organizations are generating more data than ever before, and that data is coming from a wider variety of sources, in a multitude of formats. At the same time, businesses need to move faster, making quick, data-driven decisions to stay competitive.
This creates a challenge for traditional data engineering, which often involves tedious manual coding, schema struggles, and siloed expertise. We’ve heard about the daily grind from data workers everywhere::
-
How can I quickly build a pipeline to ingest all the datasets from a new source, applying the same principles I use across my other projects?
-
How do I update existing pipelines with new requirements without breaking everything downstream?
-
Why did this pipeline fail, and how can I fix it—fast?
-
How do I enforce metadata consistency when similar columns have slightly different names or data types?

The BigQuery data engineering agent aims to address these pain points head-on and accelerate the way data pipelines are built and managed.
Meet your new AI-powered data engineering team
Imagine a team of expert data engineers, available 24/7, ready to jump in and tackle the toilsome pipeline development, maintenance, and troubleshooting tasks, enabling your data team to scale and focus on higher-value work. It acts as an intelligent, task-centric system to simplify the creation and modification of your data pipelines
Here are a few ways how BigQuery data engineering agent will change the game:
1. Autonomous pipeline building and modification
Do you need a new pipeline to ingest, transform, and validate data? Simply describe your needs in natural language – the agent handles the rest. For example:
"Create a pipeline to load data from the 'customer_orders' bucket, standardize the date formats, remove duplicate entries based on order ID, and load it into a BigQuery table named 'clean_orders'."
The agent, leveraging its understanding of data engineering best practices and your specific environment and context, generates the necessary SQLx code, builds the pipeline, and even creates basic unit tests. It's not just about automation; it's about intelligent, context-aware automation.
Need to update an existing pipeline? Just tell the agent what you want to change. It analyzes the existing code, proposes modifications, and even highlights potential impacts on downstream processes. You remain in control, reviewing and approving changes, but the agent handles the heavy lifting.

While the agent performs sophisticated data engineering tasks, it is designed for the entire spectrum of "data workers"—from technical practitioners to data-savvy business users. This philosophy of broad accessibility is why the agent surfaces in multiple places. By meeting you in the BigQuery UI for interactive development, or via the CLI and API for automation, we are empowering a wider range of roles to build, manage, and innovate with data pipelines.
2. Tackle Complex Use Cases with Ease
The agent is designed to help with a wide range of transformations and tasks, including:
-
Data Ingestion: Create pipelines to ingest external data, starting with Google Cloud Storage buckets.
-
Data Transformation: Perform necessary transformations like data cleaning, deduplication, formatting, standardizing, joins, and aggregations.
-
Data Quality: Enforce data quality rules and standards, which can be customized through agent instructions.
-
Custom Logic: Incorporate your unique business logic by providing custom instructions and leveraging User-Defined Functions (UDFs) within the pipeline.
-
Data Modeling: Generate complex schemas, like Data Vault or Star Schema, directly from your source tables.
For example, you could prompt the agent:
"Create a data vault model for the 'tlc_green_trips_2022' table. Define hubs for trip, vendor, and location. Then, create the link and satellite tables to connect them."

3. Scale Your Operations with Bulk Actions
A powerful use of the data engineering agent is to scale pipeline generation or modification using previously acquired context and knowledge. Using the API and CLI, you can apply a common template or set of instructions across dozens or even hundreds of pipelines simultaneously. This helps scaleing your team's output and is ideal for standardizing processes across teams/projects or deploying similar pipelines for various use cases.
How it works: Context is Key
The agent's ability to handle these complex tasks stems from its deep, hierarchical contextual understanding. This allows it to generate code that is not only syntactically correct but also aligned with your organization's specific needs and best practices.

-
Hierarchical context: This intelligence is built on several layers of knowledge, which you can augment with your own instructions
-
Universal Knowledge: The foundation includes a broad understanding of common data formats, SQL syntax, and standard data engineering practices.
-
Vertical-Specific Knowledge: This layer can contain knowledge of industry-specific conventions, such as data formats in finance or healthcare.
-
Organizational/Project Context: The agent can be made aware of your company’s unique naming conventions, security policies, and preferred methodologies.
-
Pipeline-Specific Context: For any given task, it understands the details of the specific pipeline, including its source and target schemas, transformations, and dependencies.
-
Continuous learning: The agents don't just follow instructions; they learn from user interactions and previously developed pipelines. Agent knowledge gets continually enhanced over time as they work in your environment.
You can directly influence this by providing the agent with custom instruction files.Here is an example of an agent instruction file for a retail domain, which sets standards for naming conventions, transformation rules, and data quality checks:
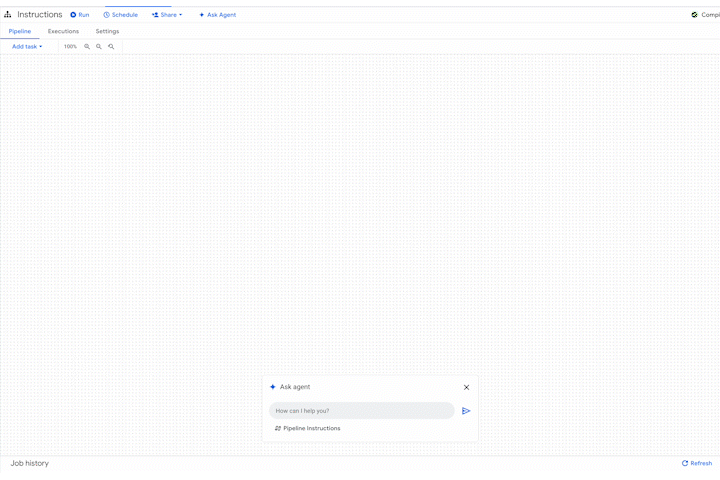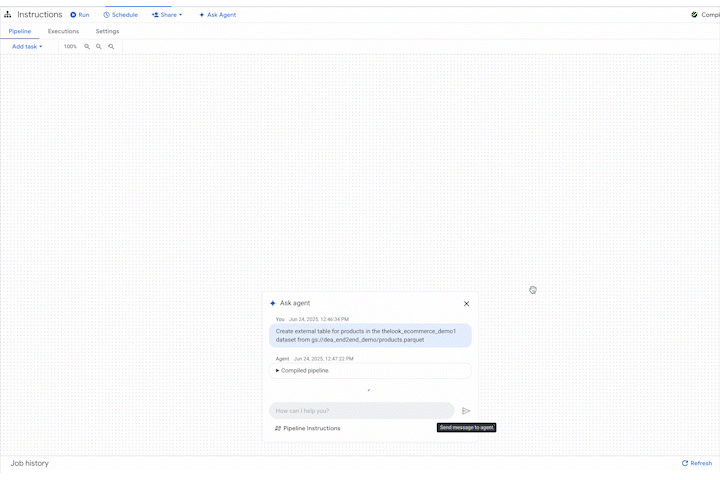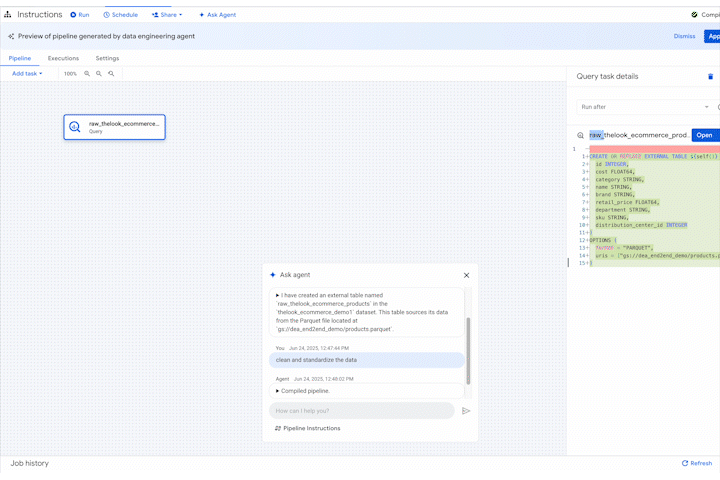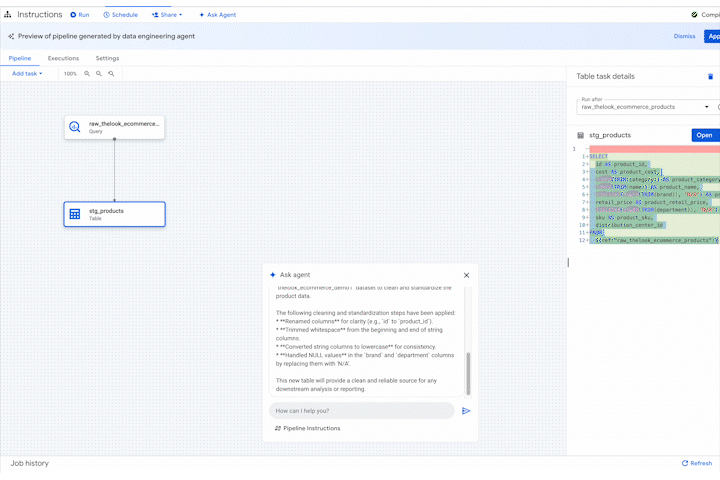
What's Next? A More Intelligent Data Platform
This is just the beginning of our journey to build a truly intelligent, autonomous data platform. The BigQuery Data Engineering Agent, coupled with products like Dataplex, BigQuery ML, and Vertex AI, is poised to transform how organizations manage, process, and derive value from their data.
Looking ahead, this intelligence will expand into proactive troubleshooting and optimization. Imagine agents that monitor your pipelines, identify issues like schema and data drift, and propose fixes before they impact your business. It's like having a dedicated expert constantly watching over your data infrastructure.
This will be powered by a collaborative, multi-agent environment where specialized agents work together to achieve complex goals, much like a real-world data team. Our vision includes:
-
An agent expertly handles data intake from various sources.
-
A agent crafts efficient and reliable data pipelines.
-
A validation agent helps ensures data quality and consistency.
-
A troubleshooting agent proactively identifies and resolves issues.
-
A data quality agent, powered by Dataplex metadata, monitors data and proactively alerts on anomalies.
While our initial focus is on ingestion and transformation tasks, we are committed to expanding these capabilities to other critical data engineering areas. By automating tedious work, these agents will act as intelligent collaborators, unlocking new levels of productivity and paving the way for a new era of data-driven innovation.
Data engineering agent and your data workers
The world is only beginning to see the full potential of AI-powered agents in revolutionizing how data workers interact with and derive value from their data. With BigQuery data engineering agent, the roles of data engineers, data analysts and data scientists are expanding beyond their traditional boundaries, empowering these teams to achieve more, faster, and with greater confidence. These agents act as intelligent collaborators, streamlining workflows, automating tedious tasks, and unlocking new levels of productivity. While our initial focus is on ingestion and transformation tasks, we are committed to expanding these capabilities to other critical data engineering areas. By automating tedious work, these agents will act as intelligent collaborators, unlocking new levels of productivity and paving the way for a new era of data-driven innovation.

Coupled with products like Dataplex, BigQuery ML, and Vertex AI, BigQuery data engineering agent is poised to transform the way organizations manage, process, and derive value from their data. By automating complex tasks, promoting collaboration, and empowering data workers of all skill levels, these agents are paving the way for a new era of data-driven innovation.
Ready to get started?
BigQuery Data Engineering Agent is available now in an experimental release. We are incredibly excited to see how you integrate it into your workflows to unlock the full potential of your data.
Join the Experimental Program waiting list: Show your interest by signing up using the link
BigQuery data engineering agent will be available soon. We're excited to see how it fits into your data engineering workflows and help you unlock the full potential of your data. Show your interest in getting access here.
To help you and your team to understand some of the features and get started, we have compiled the following resources:
-
Recent Webinar: Empowering Data Teams with Agentic AI

