Data on Kubernetes has crossed the chasm: the case for running stateful apps on GKE

Akshay Ram
Group Product Manager, GKE
John T. Forman
Director; Master Technology Architect, Accenture
Kubernetes is the de facto standard today for cloud-native development. For a long time, Kubernetes was mostly associated with stateless applications such as web and batch applications. However, like most things, Kubernetes is constantly evolving. These days, we are seeing an exponential increase in the number of stateful apps on Kubernetes. In fact, the number of clusters running stateful apps on Google Kubernetes Engine (GKE) has doubled every year since 2019.
Today, Kubernetes is increasingly used to run stateful and data applications such as databases (Kafka, MySQL, PostgreSQL, and MongoDB), big data (Hadoop and Spark), data analytics (Hive and Pig), and machine learning (TensorFlow and PyTorch). Modern data engineering tools like Airbyte and vector DBs, and feature stores such as Qdrant, Weaviate and Feast, use containers and Kubernetes as their default self-managed compute deployment option.
Meanwhile, Kubernetes platform engineers are becoming more conversant with these data tools, while data engineers are familiarizing themselves with Kubernetes. The 2022 Data On Kubernetes (DoK) report, where customers reported observing a 3x increase in productivity by running data applications on Kubernetes. Additionally, over 41% of respondents said they plan to reskill or hire for data on Kubernetes talent. The push for running data workloads on Kubernetes is only going to grow further.
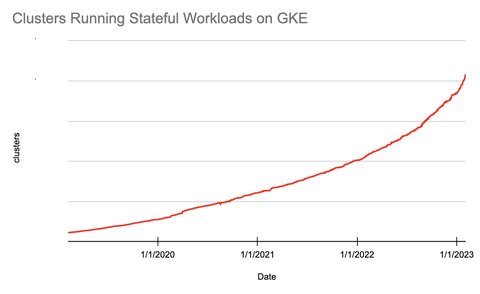
Figure 1. Stateful workloads exponential growth on Kubernetes taking Google Kubernetes Engine as an example
DoK is a promising approach to running data workloads for a variety of reasons:
- Scalability and flexibility
Computation for large-scale AI is measured in petaFlops. Customers leverage the scale of Kubernetes to run large-scale supercomputers. For instance, PGS replaced its Cray with a GKE-based supercomputer capable of 72.02 petaFLOPS. This is equivalent to the world's 7th largest computer.
Along with large-scale compute comes the need for scalable storage. The flexible nature of Kubernetes has led to storage integrations through the Container Storage Interface (CSI), which gives customers an extensive selection of storage options for accessing their data.
Support for block and file storage has been around for a while; more recently, new Object storage-based Fuse CSI drivers are proving to be a popular new integration with stateful applications. This need is driven by AI/ML and data analytics applications that need high throughput and low-cost storage. Adding a Fuse layer helps with portability, as data scientists can simply use file semantics while accessing their data on object storage rather than using a cloud provider-specific SDK.
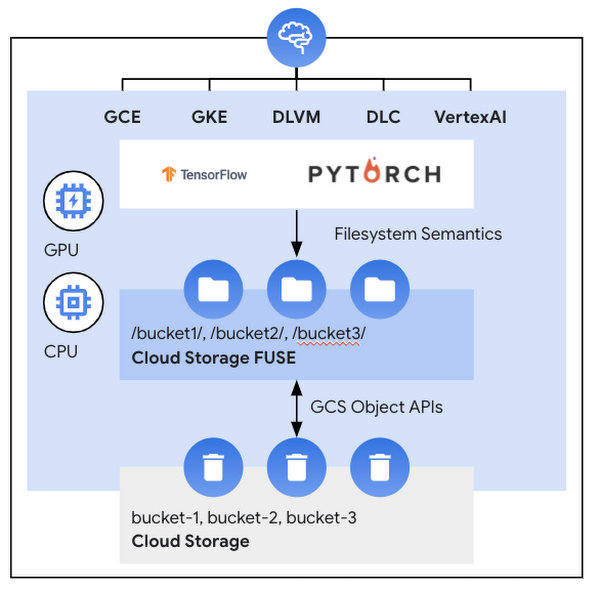
Figure 2. GCS Fuse CSI allows AI/ML applications on Pytorch and Tensorflow to access data in object storage via file semantics
2. Resilience
Kubernetes provides a high degree of resilience, with automation to recover from failure scenarios. Kubernetes can auto-heal including automatically restarting containers that fail, and it can also distribute your data workloads across multiple nodes to improve performance and availability. For instance, you can use a spread policy to place replicas across zones, set up load balancing, seamlessly attach persistent volumes, and schedule backups. You can also make this a repeatable pattern with infrastructure as code (IaC) tools such as Terraform.
Kubernetes gets frequent updates, which can be seen as disruptive to stateful applications. However, with pod disruption budgets, maintenance windows, and blue-green deployments, Kubernetes has all the automation it needs to gracefully manage upgrades, allowing organizations to realize the benefits of running on modern infrastructure.
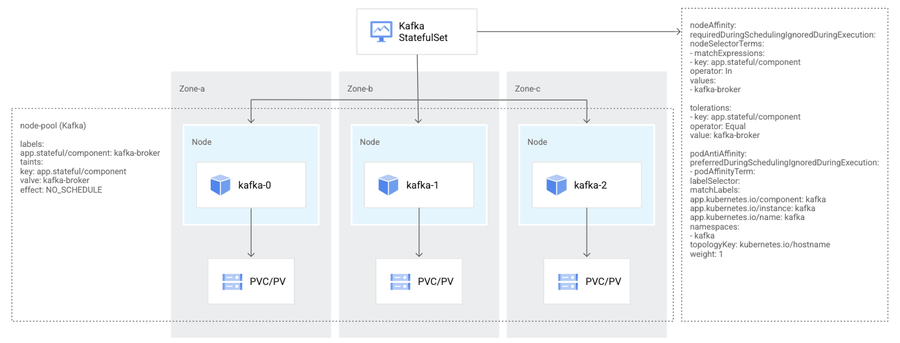
3. Openness
Kubernetes is a community-led project and fully open-source tool (at one time, it was the fastest-growing open-source software ever), meaning there is a huge ecosystem of other open-source tools designed for use with it. There’s also a rich ecosystem of tools and services to help you manage your data workloads. You can use Kubernetes operators such as Spark, Airflow, and Kafka, which come in both OSS and enterprise versions. Then there are modern data engineering OSS tools like Airbyte, Feast and vector DBs such as Weaviate, and Qdrant, that support containers and kubernetes for their self-managed compute deployments.
4. Costs
Kubernetes allows fine-grained bin packing and right-sizing of resources. This brings a level of cost optimization for data apps that was traditionally not seen in the VM world. Managed Kubernetes products such as GKE now give you out-of-the-box recommendations to help you make decisions on right-sizing workloads and driving up efficiency.
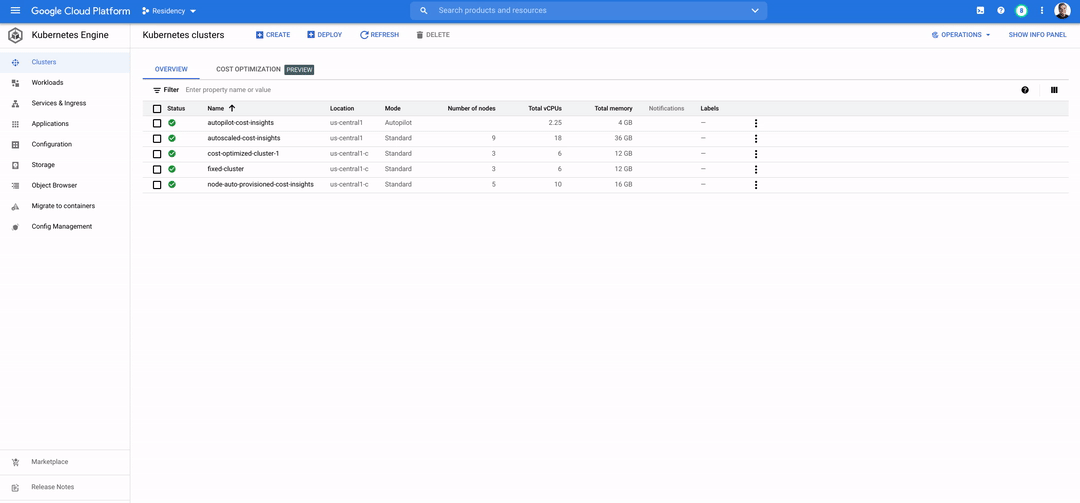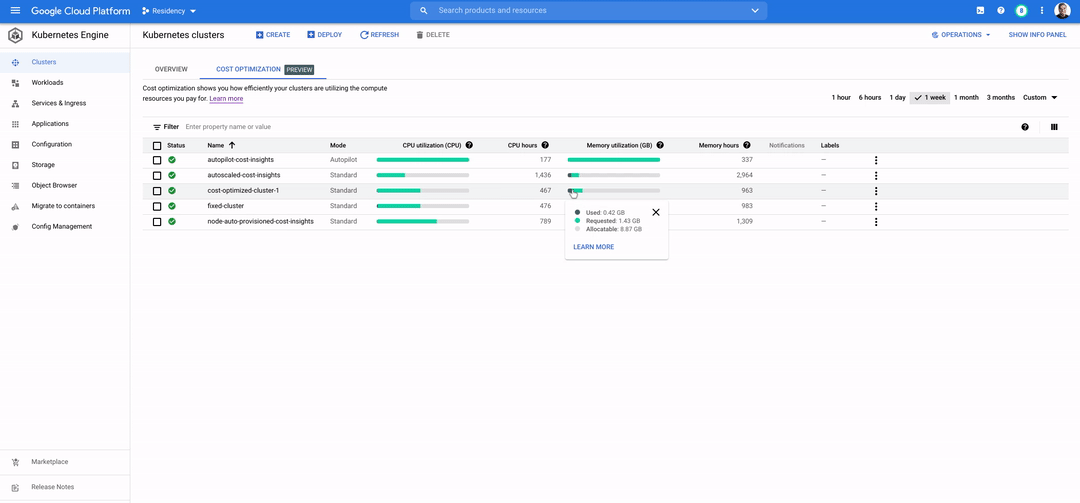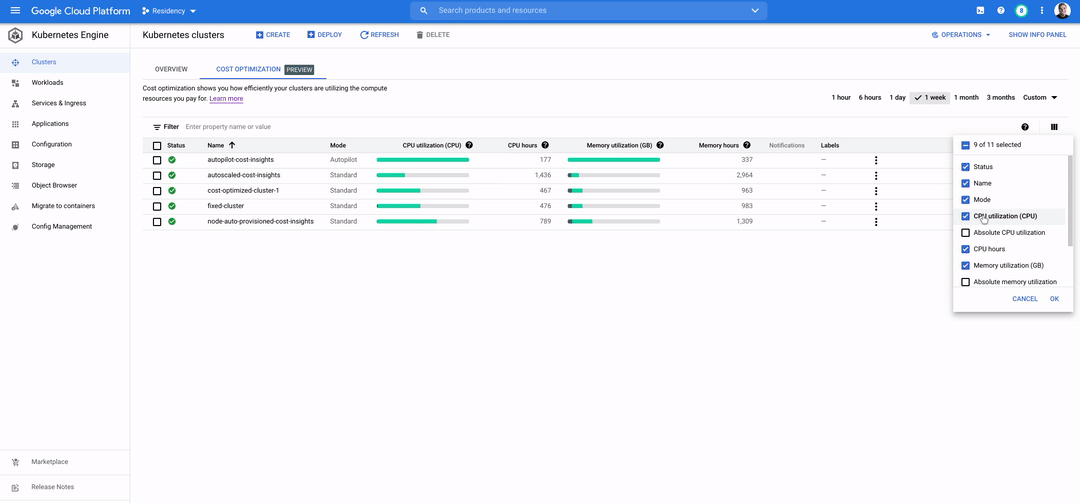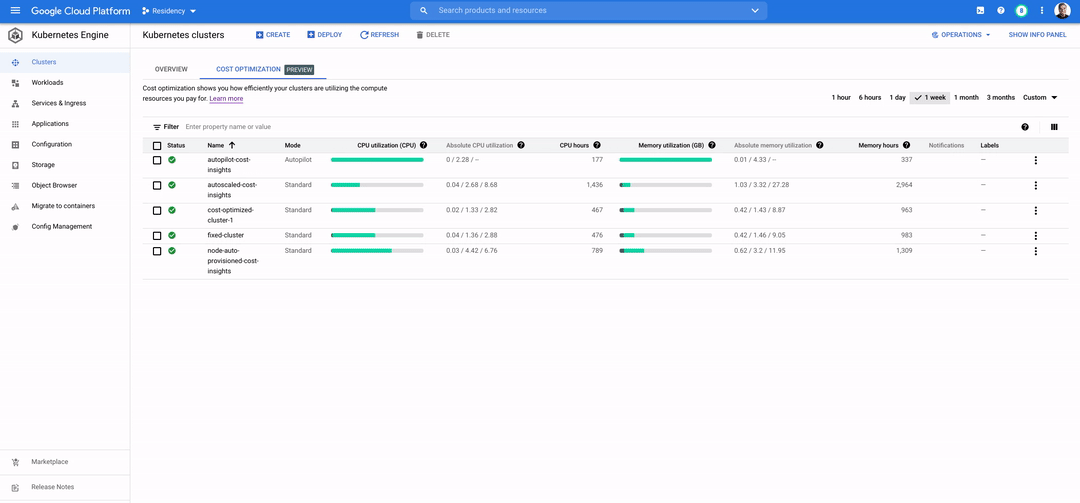
To summarize, Data on Kubernetes is well-positioned to become the operational default in a world where data and AI/ML applications are expected to grow. To learn more about running stateful and data applications on Kubernetes, explore our data on GKE documentation.
