Simplify troubleshooting in Google Kubernetes Engine with new playbooks
Kyle Benson
Product Manager, Cloud Ops
Here at Google Cloud we are always trying to find new ways to simplify how our customers troubleshoot. We’re excited to announce the introduction of a new troubleshooting experience: recommended interactive playbooks for Google Kubernetes Engine (GKE).
When dealing with issues that may be new to you, but that we’ve seen commonly in the past, these new playbooks can help you more quickly resolve issues and improve your Mean Time to Resolution, or MTTR.
Let’s take a quick look at one of these new example playbooks.
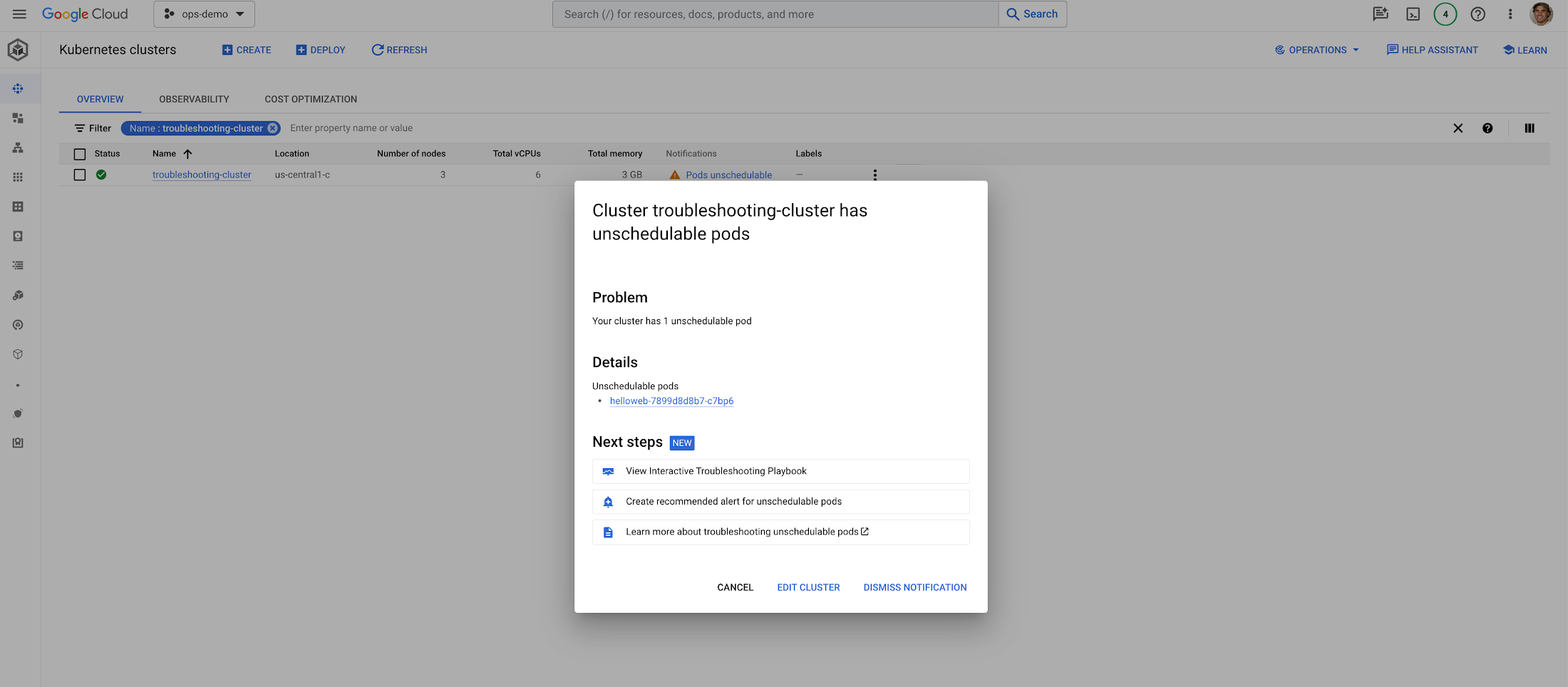
Let’s say we have a GKE cluster and an application requesting more resources than are available to it, such as memory or CPU. In that situation, it’s often the case that a Pod (or Pods) will be marked as ‘unschedulable’.
A Pod being marked as ‘unschedulable’ is a common issue and something we have documented extensively, but let’s see how we can simplify the troubleshooting process.
In the screenshot below we’ve highlighted the notification from the cluster view that Pods are unschedulable.

If we click this notification we see a screen appear offering us a few ways to better understand this issue:
Clicking into the playbook, we can see a lot of information relevant to the issue at hand including relevant logs, metrics, and suggested next steps:
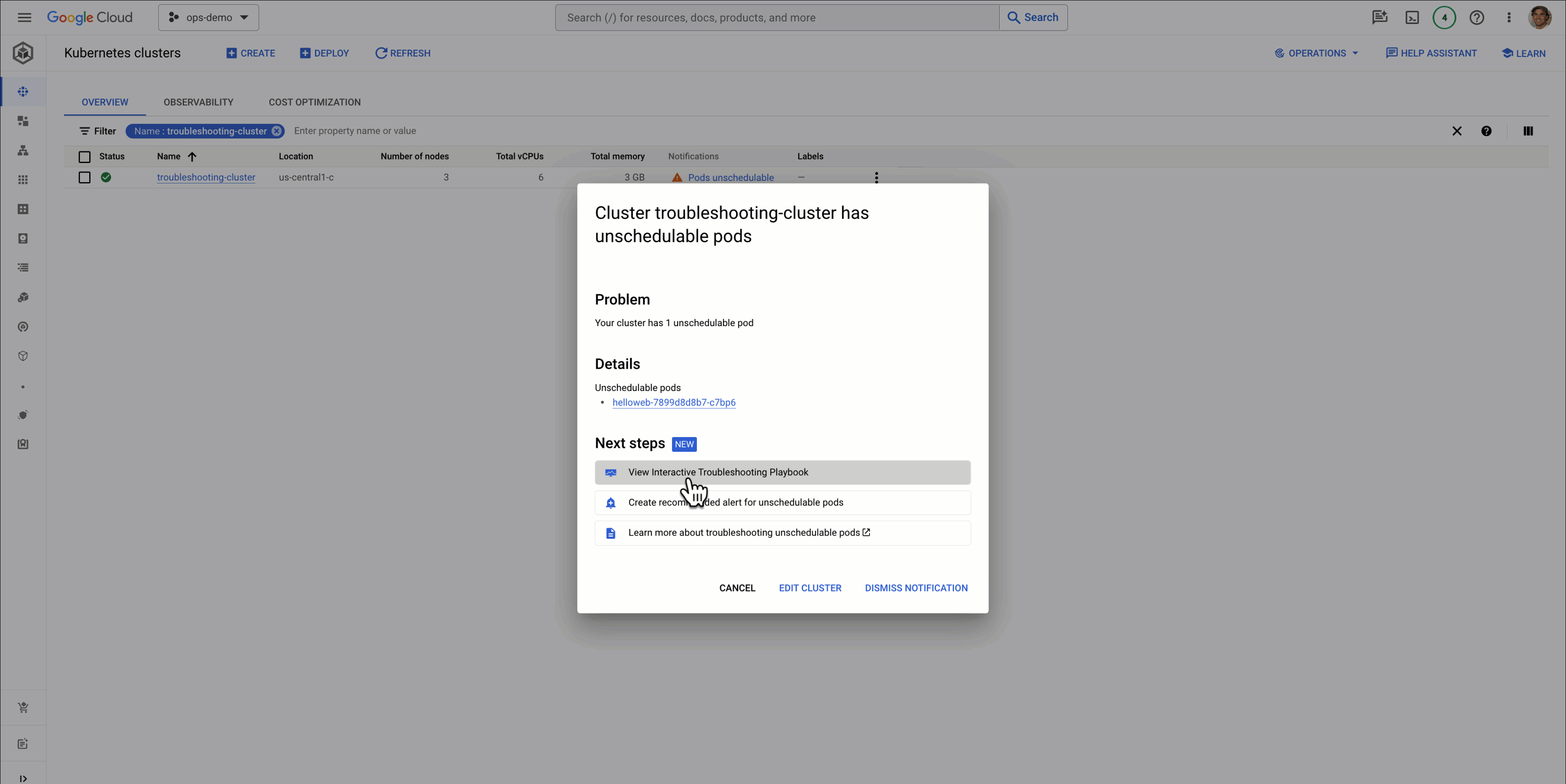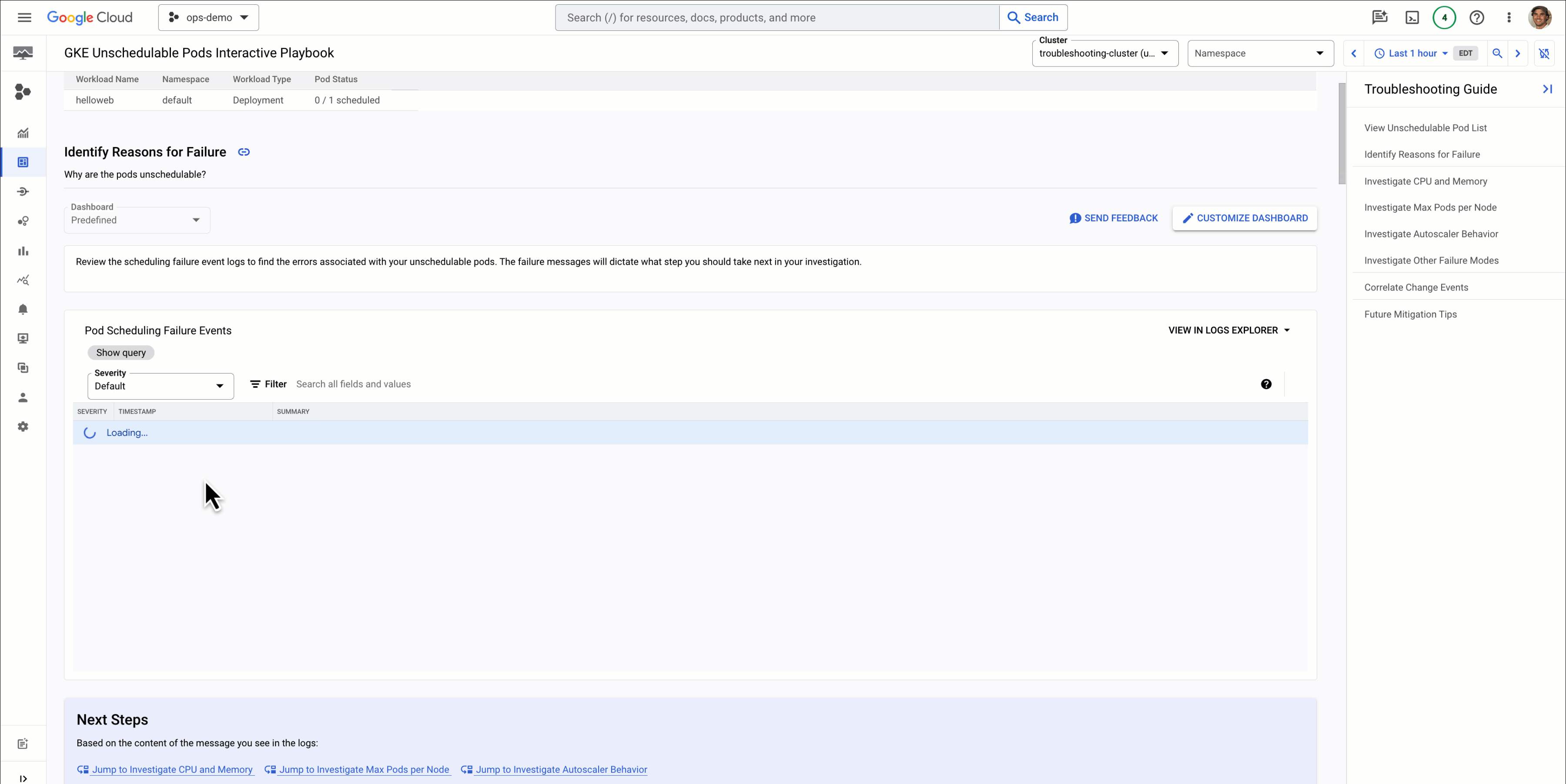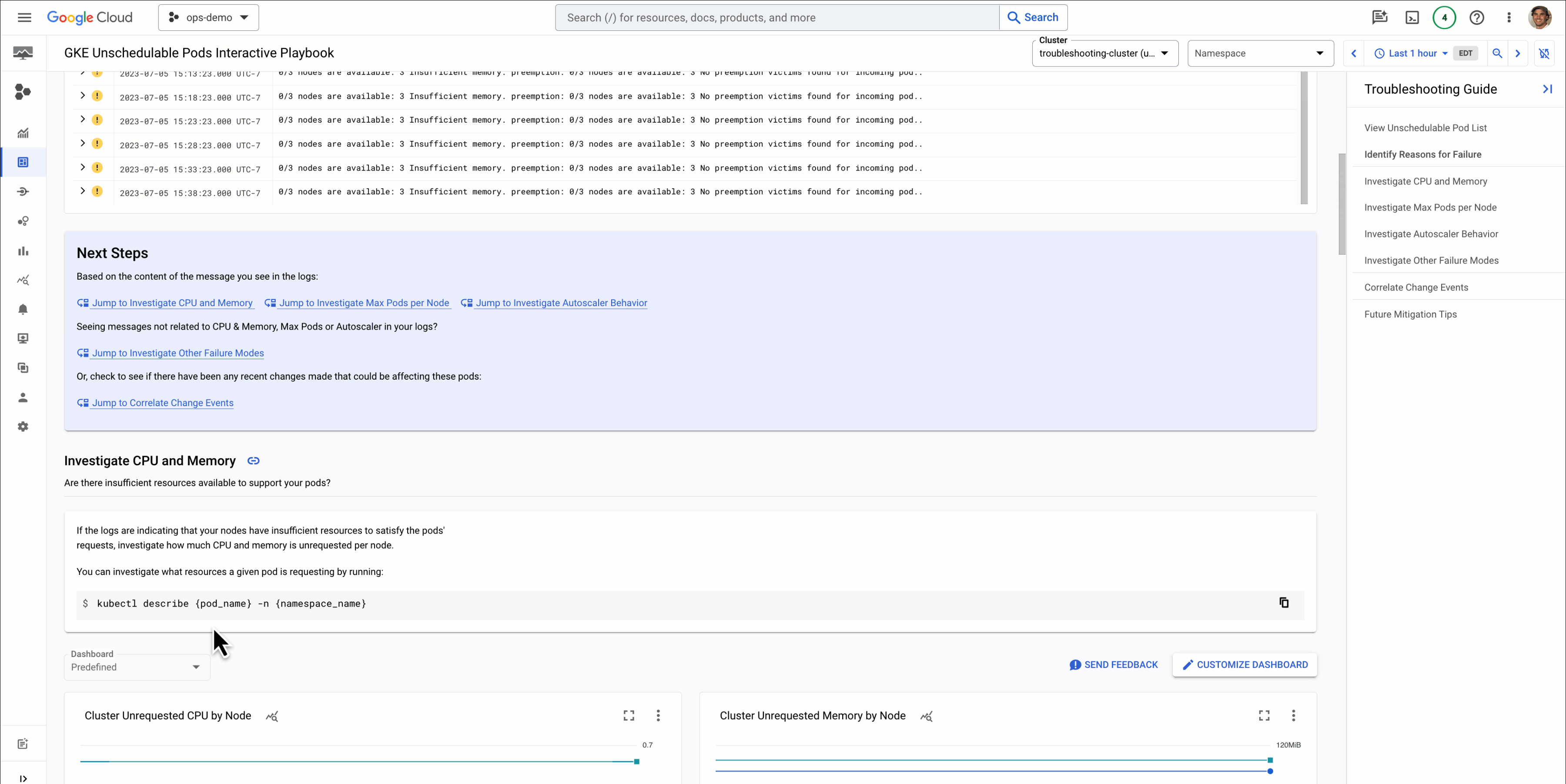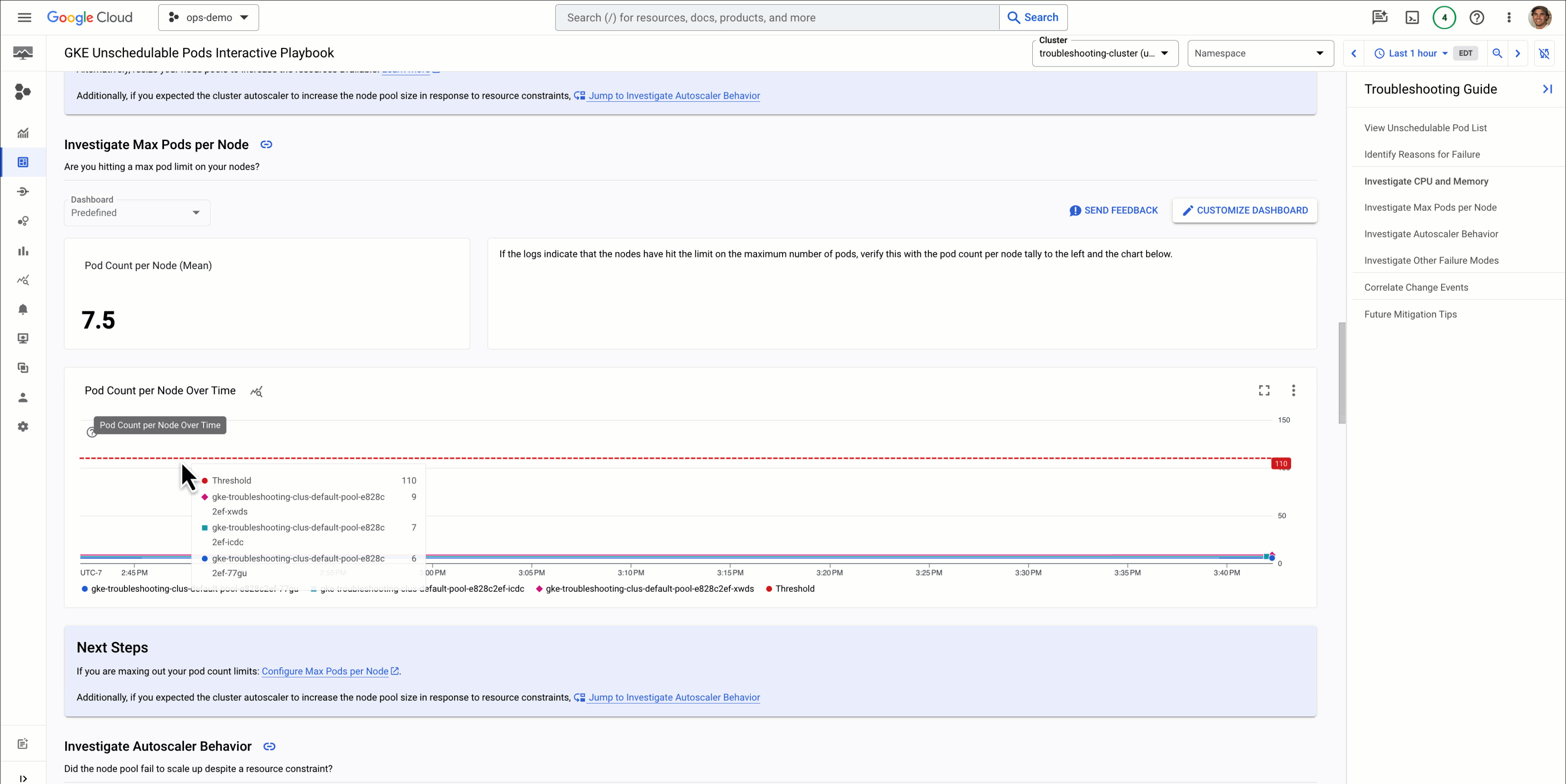
We can see from the logs and metrics that the Pods of the Deployment have requested more memory than is available, but that the node has ample resources available and there are no maximum limits on Pods being set. So to resolve this issue, we’ll need to modify the amount of memory the Pod requests, or increase the size of our cluster.
This dashboard is also customizable, so if you’d like you can add or remove components based on what’s most pertinent to you and your organization.
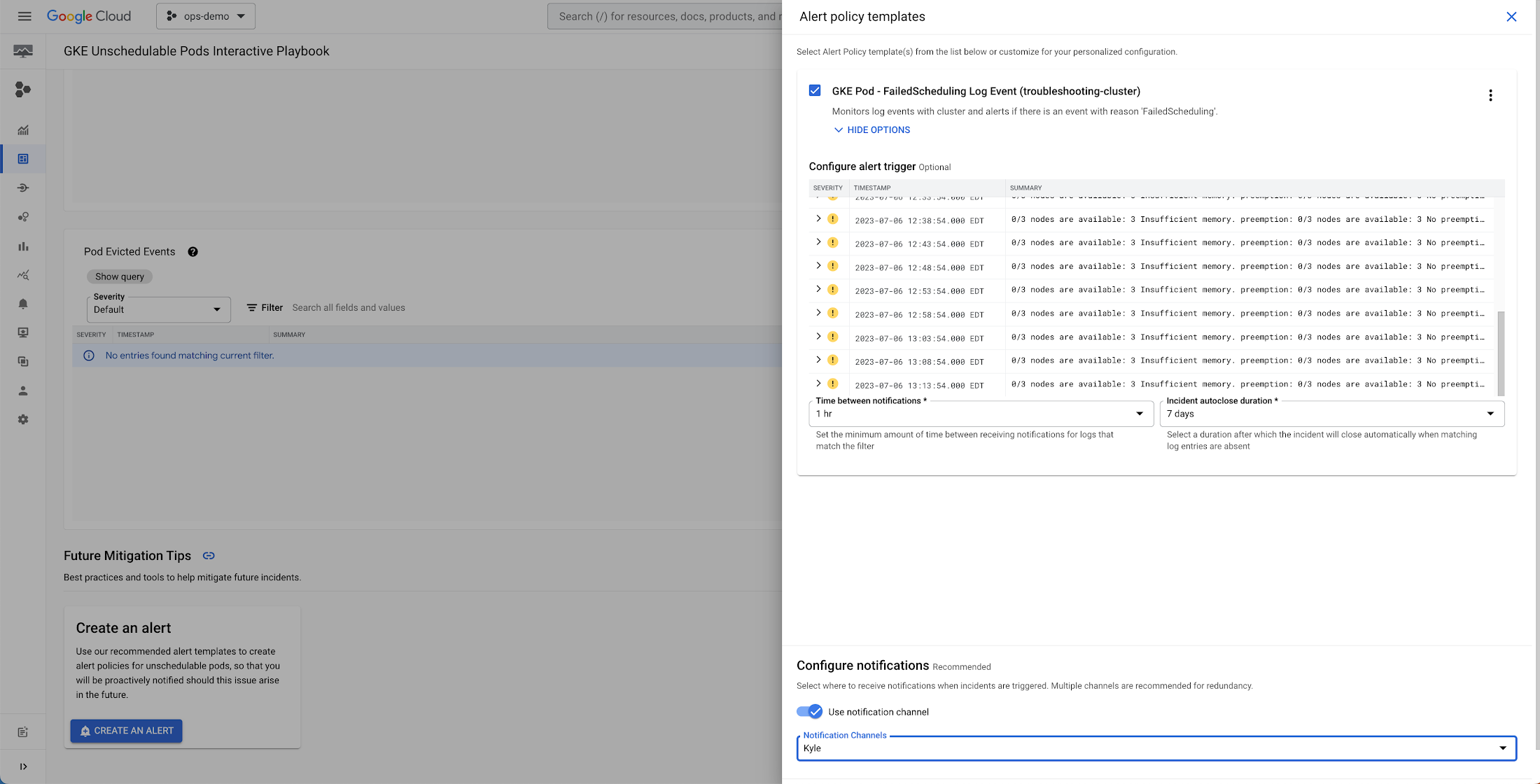
Finally, at the bottom of the playbook, under ‘Future Mitigation Tips’, you can also create an alert policy to look specifically for this issue:
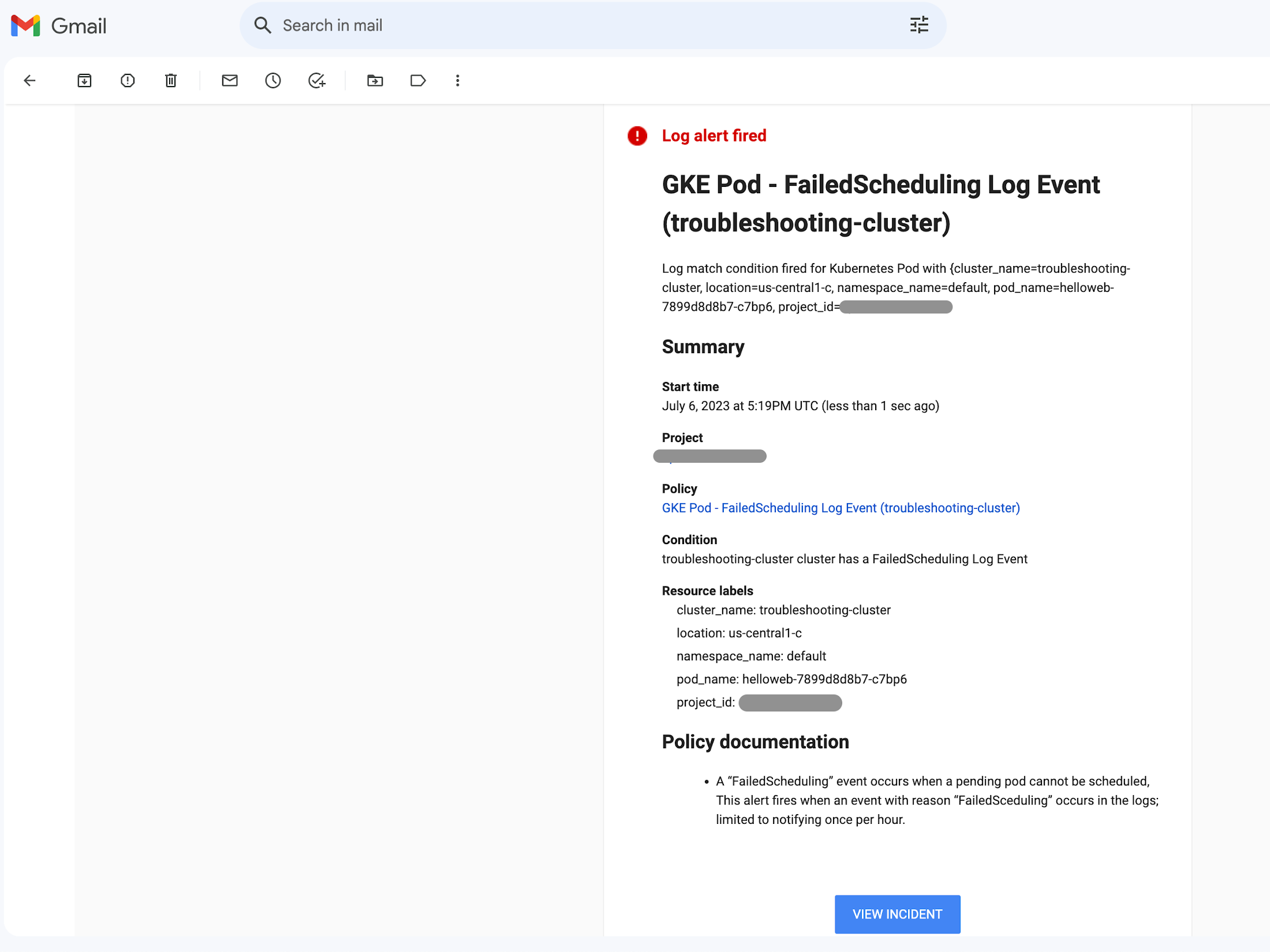
When this alert fires, you’ll be able to acknowledge the incident or click the policy link to jump straight into this dashboard and begin troubleshooting:
This week we’re making two playbooks available: Unschedulable Pods, and a playbook for troubleshooting repeated attempts of a deployment crashing, commonly known as CrashLoopBackOff. We have playbooks for Memory and CPU scaling issues coming soon.
Both will appear as notifications for clusters where issues are present, and we hope this helps you in your troubleshooting journey! As always, if you have any questions or feedback on the product, please let us know by leaving feedback under the question mark icon of the page.
