Sign here! Creating a policy contract with Configuration as Data
Kelsey Hightower
Principal Engineer
Mark Balch
Senior Product Manager, Google Cloud
Configuration as Data is an emerging cloud infrastructure management paradigm that allows developers to declare the desired state of their applications and infrastructure, without specifying the precise actions or steps for how to achieve it. However, declaring a configuration is only half the battle: you also want policy that defines how a configuration is to be used.
Configuration as Data enables a normalized policy contract across all your cloud resources. That contract, knowing how your deployment will operate, can be inspected and enforced throughout a CI/CD pipeline, from upstream in your development environment to deployment time, and ongoing in the live runtime environment. This consistency is possible by expressing configuration as data throughout the development and operations lifecycle.
Config Connector is the tool that allows you to express configuration as data in Google Cloud. In this model, configuration is what you want to deploy, such as “a storage bucket named my-bucket with a standard storage class and uniform access control.”
Policy, meanwhile, typically specifies what you’re allowed to deploy, usually in conformance with your organization’s compliance needs. For example, “all resources must be deployed in Google Cloud’s LONDON region.”
When each stage in your pipeline treats configuration as data, you can use any tool or language to manipulate configuration as data, knowing they will interoperate and that policy can be consistently enforced at any or all stages. And while a policy engine won’t be able to understand every tool, it can validate the data generated by each tool. It’s just like data in a database can be inspected by anyone who knows the schema regardless of the tool that wrote into the database.
Contrast that with pipelines today, where policy is manually validated, hard coded in scripts within the pipeline logic itself, or post-processed on raw deployment artifacts after rendering configuration templates into specific instances. In each case, policy is siloed—you can’t take the same policy and apply it anywhere in your pipeline because formats differ from tool to tool.
Helm, for example, contains code specific to its own format.1
Terraform HCL may then deploy the Helm chart.2
The HCL becomes a JSON plan, where the deployment-ready configuration may be validated before being applied to the live environment.3
These examples show three disparate data formats across two different tools representing different portions of a desired end state. Add in Python scripting, gcloud CLI, or kubectl commands and you start approaching ten different formats—all for the same deployment! Reliably enforcing a policy contract requires you to inject tool- and format-specific validation logic on case-by-case basis. If you decide to move a config step from Python to Terraform or from Terraform to kubectl, you’ll need to re-evaluate your contract and probably re-implement some of that policy validation.
Why don’t these tools work together cleanly? Why does policy validation change depending on the development tools you’re using? Each tool can do a good job enforcing policy within itself. As long as you use that tool everywhere, things will probably work ok. But we all know that’s not how development works. People tend to choose tools that fit their needs and figure out integration later on.
A Rosetta Stone for policy contracts
Imagine that everyone is defining their configuration as data, while using tools and formats of their choice. Terraform or Python for orchestration. Helm for application packaging. Java or Go for data transformation and validation. Once the data format is understood (because it is open source and extensible), your pipeline becomes a bus that anyone can push configuration onto and pull configuration from.
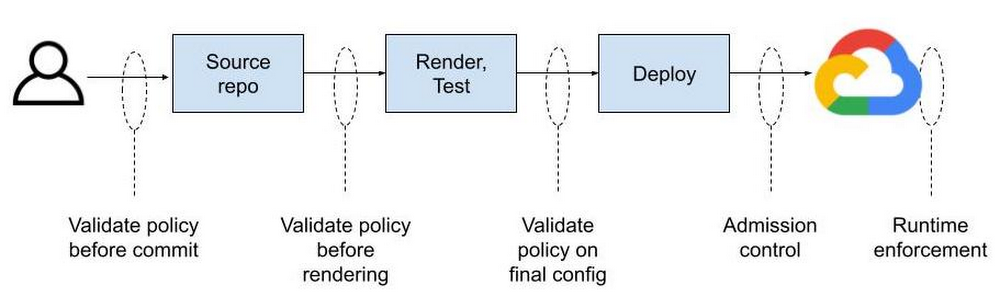
Policies can be automatically validated at commit or build time using custom and off-the-shelf functions that operate on YAML. You can manage commit and merge permissions separately for config and policy to separate these distinct concerns. You can have folders and unique permissions for org-wide policy, team-wide policy, or app-specific policy. Therein lies the dream.
The most common way to generate configuration is to simply write a YAML file describing how Kubernetes should create a resource for you. The resulting YAML file is then stored in a git repository where it can be versioned and picked up by another tool and applied to a Kubernetes cluster. Policies can be enforced on the git repo side to limit who can push changes to the repository and ultimately reference them at deploy time.
For most users this is not where policy enforcement ends. While code reviews can catch a lot of things, it’s considered best practice to “trust but verify” at all layers in the stack. That’s where admission controllers come in, which can be considered to be the last mile of policy enforcement. Gatekeeper serves as an admission controller inside of a Kubernetes cluster. Only configurations that meet defined constraints will be admitted to the live cloud environment.
Let’s tie these concepts together with an example. Imagine you want to enable users to create Cloud Storage buckets, but you don’t want them doing so using the Google Cloud Console or the gcloud command line tool. You want all users to declare what they want and push those changes to a git repository for review before the underlying Cloud Storage buckets are created with Config Connector. Essentially you want users to be able to submit a YAML file that looks like this:
This creates a storage bucket in a default location. There is one problem with this: users can create buckets in any location even if company policy dictates otherwise. Sure, you can catch people using forbidden bucket locations during code review, but that’s prone to human error.
This is where Gatekeeper comes in. You want the ability to limit which Cloud Storage bucket location can be used. Ideally you can write policies that look like this:
The above StorageBucketAllowedLocation policy rejects StorageBucket objects with the spec.location field set to any value other than one of the Cloud Storage multi-region locations: ASIA, EU, US. You decide where to validate policy without being limited by your tool of choice and anywhere in your pipeline.
Now you have the last stage of your configuration pipeline.
Testing the contract
How does this work in practice? Let’s say someone managed to check in StorageBucket resource with the following config:
Our policy would reject the bucket because an empty location is not allowed. What happens if configuration was set to a Cloud Storage location not allowed by the policy, US-WEST1 for example?
Ideally you would catch this during the code review process before the config is committed to a git repo, but as mentioned above, that’s error prone.
Luckily, the configuration will fail because the allowmultiregions policy constraint only allows multi-region bucket locations including ASIA, EU, and US, and will reject the configuration. So, now, if you set location to “US” you can deploy the Cloud Storage bucket. You can also apply this type of location policy or any other like it to all of your resource types—Redis instances, Compute Engine virtual machines, even Google Kubernetes Engine (GKE) clusters. Beyond admission control, you can apply the same constraint anywhere in your pipeline, by ”shifting left” policy validation at any stage.
One contract to rule them all
When config is managed in silos—whether across many tools, pipelines, graphical interfaces, and command lines—you can’t inject logic without building bespoke tools for every interface. You may be able to define policies built for your front-end tools and hope nothing changes on the backend. Or you can wait until deployment time to scan for deviations and hope nothing appears during crunch time.
Compare that with configuration as data contracts, which are transparent and normalized across resource types, which has facilitated a rich ecosystem of tooling built around Kubernetes with varied syntax (YAML, JSON) and languages including Ruby, Typescript, Go, Jinja, Mustache, Jsonnet, Starlark, and many others. This isn’t possible without a data model.
Configuration-as-Data-inspired tools such as Config Connector and Gatekeeper let you enforce policy and governance as natural parts of your existing git-based workflow rather than creating manual processes and approvals. Configuration as data normalizes your contract across resource types and even cloud providers. You don’t need to reverse engineer scripts and code paths to know if your contract is being met—just look at the data.
1. https://github.com/helm/charts/blob/master/stable/jenkins/templates/jenkins-master-deployment.yaml
2. https://medium.com/swlh/deploying-helm-charts-w-terraform-58bd3a690e55
3. https://github.com/hashicorp/terraform-getting-started-gcp-cloud-shell/blob/master/tutorial/cloudshell_tutorial.md

