Improved gVisor file system performance for GKE, Cloud Run, App Engine and Cloud Functions
Ayush Ranjan
Software Engineer
Fabricio Voznika
Software Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialFlexible application architectures, CI/CD pipelines, and container workloads often run untrusted code and hence should be isolated from sensitive infrastructure. One common solution has been to deploy defense-in-depth products (like GKE Sandbox which uses gVisor) to isolate workloads with an extra layer of protection. Google Cloud’s serverless products (App Engine, Cloud Run, Cloud Functions) also use gVisor to sandbox application workloads.
However, adding layers of defense can also introduce new performance challenges. We discovered one such challenge when gVisor’s user space kernel required several operations to walk file system paths. To address this and significantly increase gVisor performance, we wrote an entirely new file system layer with performance in mind while retaining the same level of security. The new file system (VFS2) reduces the number of operations required to serve file system syscalls, reduces lock contention, allocates memory more efficiently, and improves compatibility with Linux.
Defense-in-depth and the file system
The first layer of defense is the gVisor kernel running in user mode. The gVisor threat model assumes that a malicious container can compromise gVisor’s kernel while still keeping the malicious container isolated from the underlying host infrastructure or other workloads. Since the gVisor kernel cannot be trusted, it doesn’t have direct access to the file system. File system operations are brokered by a proxy (called Gofer) that is isolated from a possibly malicious workload. Operations like open, create, and stat are forwarded to the proxy, vetted, and then executed by the proxy. Gofers run as a separate process, one per container in the pod, and are also protected with defense in depth layers to only give it access it requires. After the gofer has given access to a file, read and write operations can be done by gVisor directly to the host to improve performance.
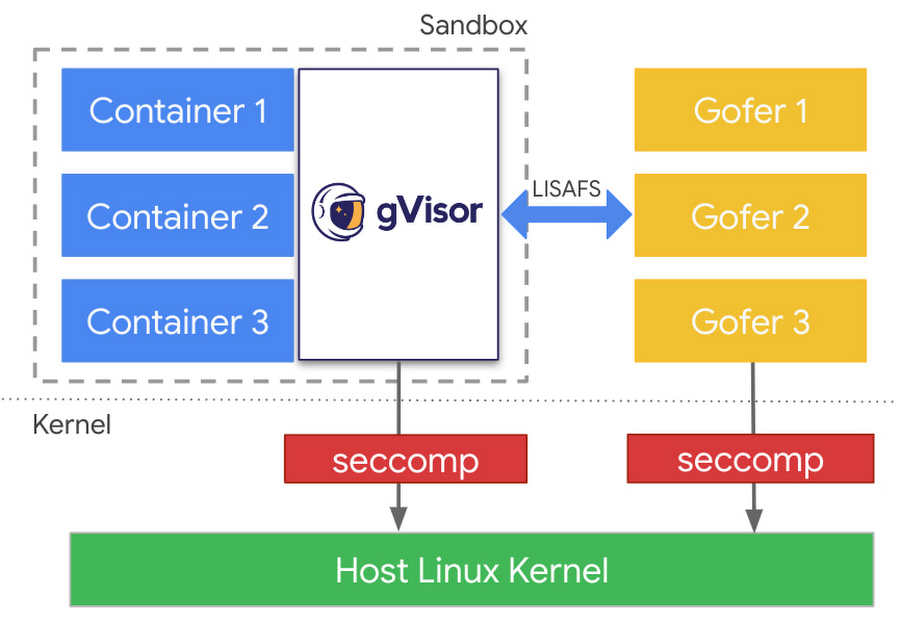
Before the rework of the gVisor kernel file system, numerous operations were required to walk file paths leading to some performance shortcomings. This issue was especially noticeable when using gofer mounted file systems, where the roundtrip cost for each operation is aggravated by the RPC and scheduling costs. More notably, gVisor sandbox would issue a new RPC to the gofer for walking each path component, which would degrade performance substantially.
Improved file system performance
Addressing this challenge required enabling gVisor’s Sentry with the ability to delegate path resolution directly to the file system. This allowed the gofer file system to issue a single RPC for performing large walks, instead of one RPC per path component in the operation. As an example, in VFS1 stat(/foo/bar/baz) generates at least three RPC to the gofer (foo, bar, baz) whereas VFS2 only generates one.
We took this opportunity to also rework our sandbox-gofer protocol layer. Earlier we were using a modified version of 9P2000.L protocol. However, this protocol turned out to be very chatty, issuing many RPCs and consuming a lot of memory. We built a new protocol called LISAFS (Linux Sandbox File system protocol) to replace 9P. LISAFS is more economical with RPCs and memory usage. LISAFS provides RPCs for multiple path-component walks. The gofer file system in VFS2 can now perform such one-shot walks with LISAFS. LISAFS can also perform much faster file IO over RPCs.
Workloads that perform frequent file system operations, like open, create, stat, list, and load libraries, are seeing improved performance with VFS2 and LISAFS. Examples of these workloads include running interpreted languages such as Python and NodeJS, with a large number of imports, or building binaries from source. CI/CD workloads, such as bazel, build on large codebases, and provide good insights into file system performance. Such workloads have to open and read a lot of source files and write a lot of object files and binaries.
Here are the results of our open-source bazel benchmarks that build gRPC and Abseil as of December 2022. These were run in a GKE-like environment. To understand the results, it’s helpful to understand the following terminology:
Runsc overhead: This is the performance overhead that gVisor adds compared to native. For example, if running a workload natively (with runc) takes 10 seconds and runsc takes 13 seconds, then runsc overhead is 30%.
Root: The project’s source code is placed in the root file system, which is mounted in exclusive mode. This means that the sandbox has full control over the file system and uses more aggressive caching for improved performance.
Bind: The project source code is placed in a bind mount. All bind mounts are mounted in shared mode. This means that external modifications of files might occur and gVisor revalidates the cache on every access to ensure the state is up to date.
Tmpfs: The project source code is placed in tmpfs (in-memory file system).
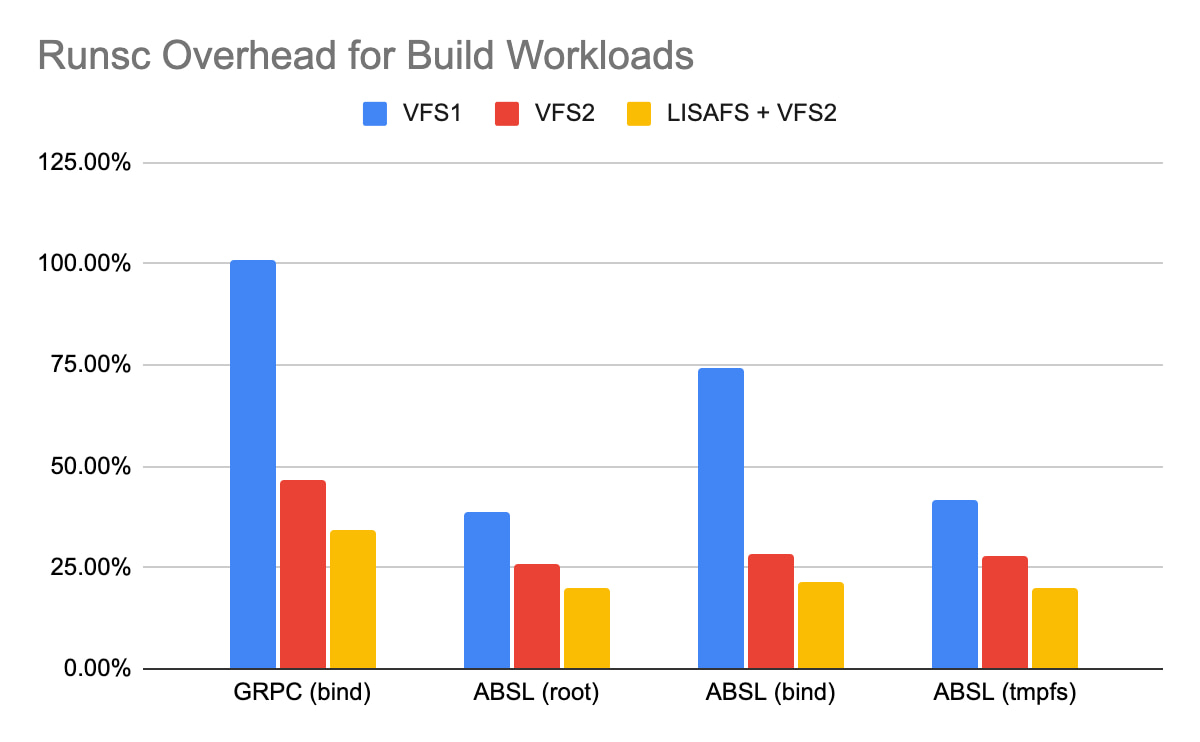
We can see that VFS2 and LISAFS consistently improve performance across all these configurations and bring runsc closer to native (runc) performance.
VFS2 and LISAFS are now launched 100% across all of GKE and serverless products. We rolled out these optimizations incrementally across several months. These also helped improve cold-start times for some applications that did a lot of file system work on initialization. For instance, LISAFS rollout data for App Engine from August 2022 shows that on average LISAFS improved cold start by more than 25%.
Delivering defense in depth security for container workloads at scale has helped us identify performance tradeoffs, such as the gVisor file system requiring a new implementation. These improvements substantially close this performance gap without requiring compromising on security. The VFS2 architecture allows us to continue improving upon security and performance tradeoffs while delivering an enterprise-ready container security solution.
Try GKE Sandbox today for enhanced workload security
GKE Sandbox provides an additional layer of security for your workloads and is ready for you to try today. Read the Enabling GKE Sandbox guide, learn more about container security by taking a look at the GKE Sandbox Overview, or get started now with a Google Cloud free trial. If you want to dive deeper into the technical details you can take a look at the Official gVisor documentation, view the source on GitHub, or even potentially contribute. We’re looking forward to seeing even more sandboxed workloads running on Google Cloud!
And try Cloud Run for a fully managed container runtime
Each Cloud Run container instance is sandboxed in a strict sandbox. The Cloud Run first generation execution environment leverages gVisor and has benefitted from the improvements described in this blog post. Get started with Cloud Run.

