Bayer Crop Science seeds the future with 15000-node GKE clusters
Rob Long
Data Engineering Lead, Bayer Crop Science
Maciek Różacki
Product Manager, GKE
Editor’s note: Today’s post examines how GKE’s support of up to 15,000 nodes per cluster benefits a wide range of use cases, including helping Bayer Crop Science rapidly process new information arriving from its genotyping labs.
At Google, scalability is a core requirement for the products we build. With more enterprises adopting Google Kubernetes Engine (GKE), we’ve been working to push the limits of a GKE cluster way beyond the supported limits—specifically, clusters with up to 15,000 nodes. This is the most supported nodes of any cloud-based Kubernetes service, and 3X the number of nodes supported by open-source Kubernetes.
There are various use cases when this kind of huge scale is useful:
If you’re running large, internet-scale services
If you need to simplify infrastructure management by having fewer clusters to manage
Batch processing — shortening the time needed to process data by temporarily using much more resources
To absorb large spikes in resource demand, for example during a gaming launch, or an online ecommerce campaign. Being able to resize an existing cluster rather than provisioning a new one can improve the availability and performance of your service.
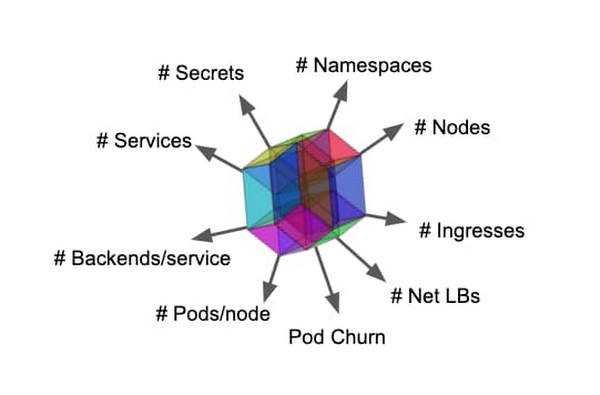
Having 15,000 nodes per cluster is all the more significant when you consider that the scalability of an IT system is much more than just how many nodes it supports. A scalable system needs to be able to use a significant amount of resources and still serve its purpose. In the context of a Kubernetes cluster, the number of nodes is usually a proxy for the size of a cluster and its workloads. When you take a closer look though, the situation is far more complex.
The scale of a Kubernetes cluster is like a multidimensional object composed of all the cluster’s resources—and scalability is an envelope that limits how much you can stretch that cube. The number of pods and containers, the frequency of scheduling events, the number of services and endpoints in each service—these and many others are good indicators of a cluster’s scale. The control plane must also remain available and workloads must be able to execute their tasks. What makes operating at a very large scale harder is that there are dependencies between these dimensions. For more information and examples, check out this document on Kubernetes Scalability thresholds and our GKE-specific scalability guidelines.
It’s not just hyperscale services that benefit from running on highly scalable platforms—smaller services benefit too. By pushing the limits of an environment’s scalability, you also expand your comfort zone, with more freedom to make mistakes and use non-standard design patterns without jeopardizing the reliability and performance of your infrastructure. For a real-world example of highly scalable platforms, today we are hearing from the team at Bayer Crop Science and learning about a recent project they designed.
Setting on a journey to run at 15,000 node scale
To make it possible for GKE users to run workloads that need more than 5,000 nodes in one cluster, we engaged a group of design partners into a closed early access program.
Precision agriculture company Bayer Crop Science (BCS) is currently one of the biggest users of GKE, with some of the largest GKE clusters in the Google Cloud fleet. Specifically, it uses GKE to help it make decisions about which seeds to advance in its Research & Development pipeline, and eventually which products (seeds) to make available to farmers. Doing this depends upon having accurate and plentiful genotype data. With 60,000 germplasm in its corn catalog alone, BCS can’t test each seed population individually, but rather, uses other data sets, like pedigree and ancestral genotype observations, to infer the likely genotypes of each population. This way, BCS data scientists can answer questions like “will this seed be resistant to a particular pest?”, reducing how much farmland they need each year to operate the seed production pipeline.
Last year, BCS moved its on-premises calculations to GKE, where the availability of up to 5,000-node clusters allowed scientists to precalculate the data they would need for the month, and run it as a single massive multi-day batch job. Previously, scientists had to specially request the genotype data they needed for their research, often waiting several days for the results. To learn more, watch this presentation from Next ‘19 by BCS’s Jason Clark.
Bayer Crop Science infrastructure/architecture
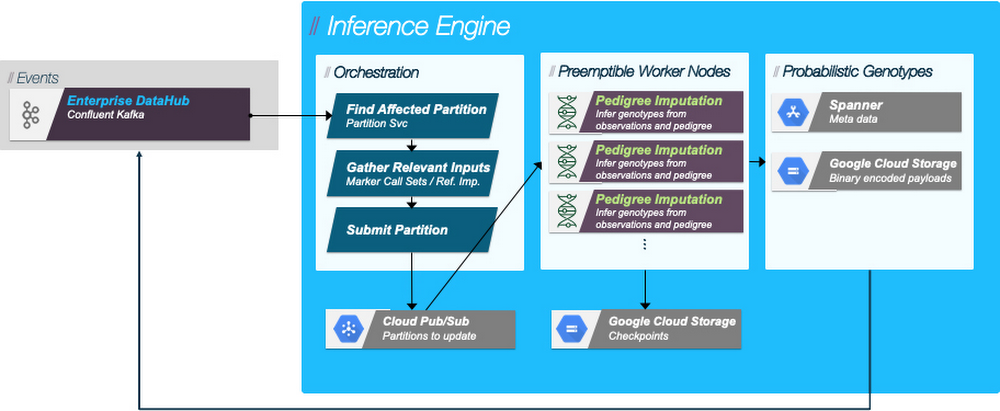
To facilitate the rapid processing of new information arriving from genotyping labs, BCS implemented an event-driven architecture. When a new set of genotype observations passes quality control, it’s written to a service, and an event is published to a Cloud Pub/Sub topic. The inference engine watches this topic, and if the incoming events match the requirements to allow inference, a job request is created and placed on another topic. The inference engine worker nodes are deployed on the largest available Kubernetes cluster using a Horizontal Pod Autoscaler that looks at the depth of work on the incoming queue. Once a worker selects a job from the topic, it stages all the required inputs, including the genotype observations that initially triggered the job, and runs the genotype inference algorithm. Results are written into a service for accessibility and an event is emitted to a genotype inference topic. Downstream processes like decision making based on inferred genotypes are wired into this event stream and begin their work as soon as they receive the event.
Preparations and joint tests
BCS’s biggest cluster used to infer the data (a.k.a. for imputation) uses up to 4,479 nodes with 94,798 CPUs and 455 TB of RAM. And because that imputation pipeline is a highly parallelizable batch job, scaling it to run on a 15,000-node cluster was straightforward.
In our joint tests we used the cluster hosting the inference engine and its autoscaling capabilities to overscale the size of the workload and amount of available resources. We aimed to scale the cluster from 0 to 15,000 nodes with large machines (16CPU highmem 104GB RAM), for a total of 240,000 CPU cores and 1.48PiB of RAM.
To make sure that the resources here are provided at low cost, the cluster hosting the inference engine worker pods used exclusively preemptible instances, while the supporting services hosting the input data and handling outputs ran on regular instances. With preemptible VMs, BCS gets a massive amount of compute power, while slashing the costs of compute power almost by a factor of five.
With 15,000 nodes at its disposal, BCS also saves a lot of time. In the old on-prem environment with 1,000 CPUs, BCS would have been able to process ~62,500,000 genotypes per hour. With clusters up to the 5,000 node limit BCS can process 100 times faster. And with 240,000 CPUs across 15,000 nodes, BCS can process ~15,000,000,000 genotypes per hour. That gives BCS the flexibility to make model revisions and quickly reprocess the entire data backlog, or quickly add inference based on new data sets, so data scientists can continue to work rather than waiting for batch jobs to finish.
Lessons learned from running at large scale
Both Google and BCS learned a lot from running a workload across a single 15,000 node cluster.
For one thing, scaling the components that interact with the cluster proved to be very important. As GKE processed data with increased throughput, we had to scale up other components of the system too, e.g., increase the number of instances on which Spanner runs.
Another important takeaway was the importance of managing preemptible VMs. Preemptible VMs are highly cost efficient but only run for up to 24 hours, during which period they can be evicted. To use preemptible VMs effectively, BCS checkpointed their Google Cloud Storage environment every 15 minutes. That way, if the job is preempted before it completes, the job request falls back into the queue and is picked up and continued by the next available worker.
Sowing the seeds of innovation
For Bayer Crop Science to handle large amounts of genome data, it needs significant amounts of infrastructure on-demand. When all is said and done, being able to run clusters with thousands of nodes helps BCS deliver precomputed data quickly, for example, being able to reprocess the entire data set in two weeks. Up to 15,000 node clusters will help cut that time down to four days. This way analysts don’t have to request specific batches to be processed offline. BCS also realized the value of testing hypotheses on large datasets quickly, in a non-production setting.
And thanks to this collaboration, all GKE users will soon be able to access these capabilities, with support for 15,000 node clusters broadly available later this year. Stay tuned for more updates from the GKE team. In particular, be sure to join our session during NEXT OnAir on August 25th. There we’ll talk about how Google Cloud is collaborating with large Mesos and Aurora users to offer similar hyperscale experiences on GKE.